

机器学习实用指南——准确率与召回率
电子说
描述
准确率与召回率
Scikit-Learn 提供了一些函数去计算分类器的指标,包括准确率和召回率。
>>> from sklearn.metrics import precision_score, recall_score >>> precision_score(y_train_5, y_pred) # == 4344 / (4344 + 1307) 0.76871350203503808 >>> recall_score(y_train_5, y_train_pred) # == 4344 / (4344 + 1077) 0.79136690647482011
当你去观察精度的时候,你的“数字 5 探测器”看起来还不够好。当它声明某张图片是 5 的时候,它只有 77% 的可能性是正确的。而且,它也只检测出“是 5”类图片当中的 79%。
通常结合准确率和召回率会更加方便,这个指标叫做“F1 值”,特别是当你需要一个简单的方法去比较两个分类器的优劣的时候。F1 值是准确率和召回率的调和平均。普通的平均值平等地看待所有的值,而调和平均会给小的值更大的权重。所以,要想分类器得到一个高的 F1 值,需要召回率和准确率同时高。
公式 3-3 F1 值
$$ F1 = \frac{2}{\frac{1}{precision} + \frac{1}{recall}} = 2 * \frac{precison * recall}{precison + recall} = \frac{TP}{TP + \frac{FN + FP}{2}} $$
为了计算 F1 值,简单调用f1_score()
>>> from sklearn.metrics import f1_score >>> f1_score(y_train_5, y_pred) 0.78468208092485547
F1 支持那些有着相近准确率和召回率的分类器。这不会总是你想要的。有的场景你会绝大程度地关心准确率,而另外一些场景你会更关心召回率。举例子,如果你训练一个分类器去检测视频是否适合儿童观看,你会倾向选择那种即便拒绝了很多好视频、但保证所保留的视频都是好(高准确率)的分类器,而不是那种高召回率、但让坏视频混入的分类器(这种情况下你或许想增加人工去检测分类器选择出来的视频)。另一方面,加入你训练一个分类器去检测监控图像当中的窃贼,有着 30% 准确率、99% 召回率的分类器或许是合适的(当然,警卫会得到一些错误的报警,但是几乎所有的窃贼都会被抓到)。
不幸的是,你不能同时拥有两者。增加准确率会降低召回率,反之亦然。这叫做准确率与召回率之间的折衷。
准确率/召回率之间的折衷
为了弄懂这个折衷,我们看一下SGDClassifier是如何做分类决策的。对于每个样例,它根据决策函数计算分数,如果这个分数大于一个阈值,它会将样例分配给正例,否则它将分配给反例。图 3-3 显示了几个数字从左边的最低分数排到右边的最高分。假设决策阈值位于中间的箭头(介于两个 5 之间):您将发现4个真正例(数字 5)和一个假正例(数字 6)在该阈值的右侧。因此,使用该阈值,准确率为 80%(4/5)。但实际有 6 个数字 5,分类器只检测 4 个, 所以召回是 67% (4/6)。现在,如果你 提高阈值(移动到右侧的箭头),假正例(数字 6)成为一个真反例,从而提高准确率(在这种情况下高达 100%),但一个真正例 变成假反例,召回率降低到 50%。相反,降低阈值可提高召回率、降低准确率。
![图3-3 决策阈值与准确度/召回率折衷][../images/chapter_3/chapter3.3.jpeg]
Scikit-Learn 不让你直接设置阈值,但是它给你提供了设置决策分数的方法,这个决策分数可以用来产生预测。它不是调用分类器的predict()方法,而是调用decision_function()方法。这个方法返回每一个样例的分数值,然后基于这个分数值,使用你想要的任何阈值做出预测。
>>> y_scores = sgd_clf.decision_function([some_digit]) >>> y_scores array([ 161855.74572176]) >>> threshold = 0 >>> y_some_digit_pred = (y_scores > threshold) array([ True], dtype=bool)
SGDClassifier用了一个等于 0 的阈值,所以前面的代码返回了跟predict()方法一样的结果(都返回了true)。让我们提高这个阈值:
>>> threshold = 200000 >>> y_some_digit_pred = (y_scores > threshold) >>> y_some_digit_pred array([False], dtype=bool)
这证明了提高阈值会降调召回率。这个图片实际就是数字 5,当阈值等于 0 的时候,分类器可以探测到这是一个 5,当阈值提高到 20000 的时候,分类器将不能探测到这是数字 5。
那么,你应该如何使用哪个阈值呢?首先,你需要再次使用cross_val_predict()得到每一个样例的分数值,但是这一次指定返回一个决策分数,而不是预测值。
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function")
现在有了这些分数值。对于任何可能的阈值,使用precision_recall_curve(),你都可以计算准确率和召回率:
from sklearn.metrics import precision_recall_curve precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
最后,你可以使用 Matplotlib 画出准确率和召回率(图 3-4),这里把准确率和召回率当作是阈值的一个函数。
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(thresholds, precisions[:-1], "b--", label="Precision") plt.plot(thresholds, recalls[:-1], "g-", label="Recall") plt.xlabel("Threshold") plt.legend(loc="upper left") plt.ylim([0, 1]) plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
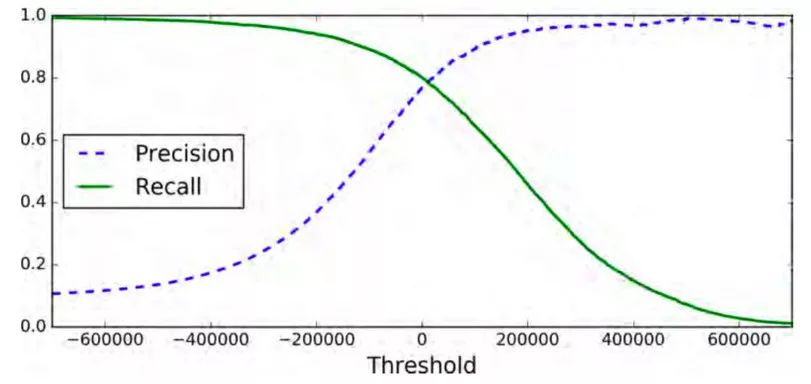
你也许会好奇为什么准确率曲线比召回率曲线更加起伏不平。原因是准确率有时候会降低,尽管当你提高阈值的时候,通常来说准确率会随之提高。回头看图 3-3,留意当你从中间箭头开始然后向右移动一个数字会发生什么: 准确率会由 4/5(80%)降到 3/4(75%)。另一方面,当阈值提高时候,召回率只会降低。这也就说明了为什么召回率的曲线更加平滑。
现在你可以选择适合你任务的最佳阈值。另一个选出好的准确率/召回率折衷的方法是直接画出准确率对召回率的曲线,如图 3-5 所示。
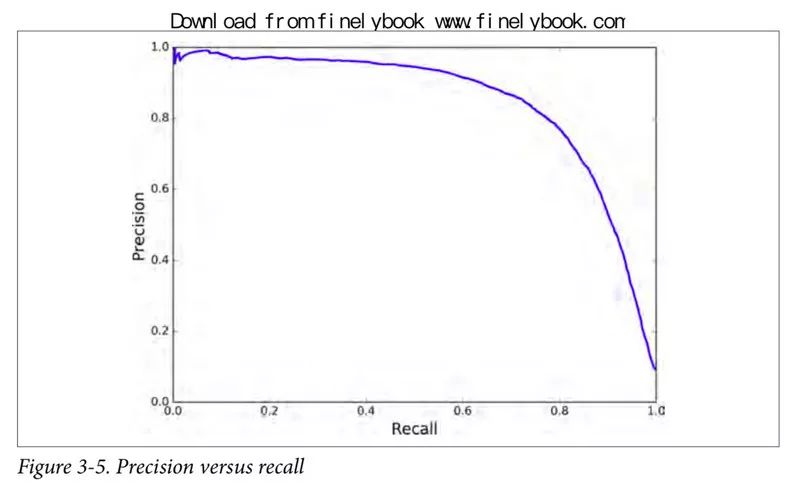
可以看到,在召回率在 80% 左右的时候,准确率急剧下降。你可能会想选择在急剧下降之前选择出一个准确率/召回率折衷点。比如说,在召回率 60% 左右的点。当然,这取决于你的项目需求。
我们假设你决定达到 90% 的准确率。你查阅第一幅图(放大一些),在 70000 附近找到一个阈值。为了作出预测(目前为止只在训练集上预测),你可以运行以下代码,而不是运行分类器的predict()方法。
y_train_pred_90 = (y_scores > 70000)
让我们检查这些预测的准确率和召回率:
>>> precision_score(y_train_5, y_train_pred_90) 0.8998702983138781 >>> recall_score(y_train_5, y_train_pred_90) 0.63991883416343853
很棒!你拥有了一个(近似) 90% 准确率的分类器。它相当容易去创建一个任意准确率的分类器,只要将阈值设置得足够高。但是,一个高准确率的分类器不是非常有用,如果它的召回率太低!
如果有人说“让我们达到 99% 的准确率”,你应该问“相应的召回率是多少?”
ROC 曲线
受试者工作特征(ROC)曲线是另一个二分类器常用的工具。它非常类似与准确率/召回率曲线,但不是画出准确率对召回率的曲线,ROC 曲线是真正例率(true positive rate,另一个名字叫做召回率)对假反例率(false positive rate, FPR)的曲线。FPR 是反例被错误分成正例的比率。它等于 1 减去真反例率(true negative rate, TNR)。TNR是反例被正确分类的比率。TNR也叫做特异性。所以 ROC 曲线画出召回率对(1 减特异性)的曲线。
为了画出 ROC 曲线,你首先需要计算各种不同阈值下的 TPR、FPR,使用roc_curve()函数:
from sklearn.metrics import roc_curve fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
然后你可以使用 matplotlib,画出 FPR 对 TPR 的曲线。下面的代码生成图 3-6.
def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') plt.axis([0, 1, 0, 1]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plot_roc_curve(fpr, tpr) plt.show()
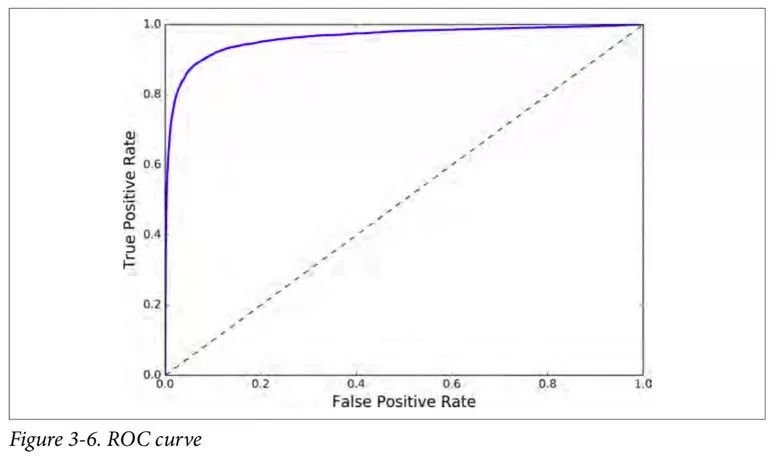
这里同样存在折衷的问题:召回率(TPR)越高,分类器就会产生越多的假正例(FPR)。图中的点线是一个完全随机的分类器生成的 ROC 曲线;一个好的分类器的 ROC 曲线应该尽可能远离这条线(即向左上角方向靠拢)。
一个比较分类器之间优劣的方法是:测量ROC曲线下的面积(AUC)。一个完美的分类器的 ROC AUC 等于 1,而一个纯随机分类器的 ROC AUC 等于 0.5。
Scikit-Learn 提供了一个函数来计算 ROC AUC:
>>> from sklearn.metrics import roc_auc_score >>> roc_auc_score(y_train_5, y_scores) 0.97061072797174941
因为 ROC 曲线跟准确率/召回率曲线(或者叫 PR)很类似,你或许会好奇如何决定使用哪一个曲线呢?一个笨拙的规则是,优先使用 PR 曲线当正例很少,或者当你关注假正例多于假反例的时候。其他情况使用 ROC 曲线。举例子,回顾前面的 ROC 曲线和 ROC AUC 数值,你或许人为这个分类器很棒。但是这几乎全是因为只有少数正例(“是 5”),而大部分是反例(“非 5”)。相反,PR 曲线清楚显示出这个分类器还有很大的改善空间(PR 曲线应该尽可能地靠近右上角)。
让我们训练一个RandomForestClassifier,然后拿它的的ROC曲线和ROC AUC数值去跟SGDClassifier的比较。首先你需要得到训练集每个样例的数值。但是由于随机森林分类器的工作方式,RandomForestClassifier不提供decision_function()方法。相反,它提供了predict_proba()方法。Skikit-Learn分类器通常二者中的一个。predict_proba()方法返回一个数组,数组的每一行代表一个样例,每一列代表一个类。数组当中的值的意思是:给定一个样例属于给定类的概率。比如,70%的概率这幅图是数字 5。
from sklearn.ensemble import RandomForestClassifier forest_clf = RandomForestClassifier(random_state=42) y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3, method="predict_proba")
但是要画 ROC 曲线,你需要的是样例的分数,而不是概率。一个简单的解决方法是使用正例的概率当作样例的分数。
y_scores_forest = y_probas_forest[:, 1] # score = proba of positive class fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)
现在你即将得到 ROC 曲线。将前面一个分类器的 ROC 曲线一并画出来是很有用的,可以清楚地进行比较。见图 3-7。
plt.plot(fpr, tpr, "b:", label="SGD") plot_roc_curve(fpr_forest, tpr_forest, "Random Forest") plt.legend(loc="bottom right") plt.show()
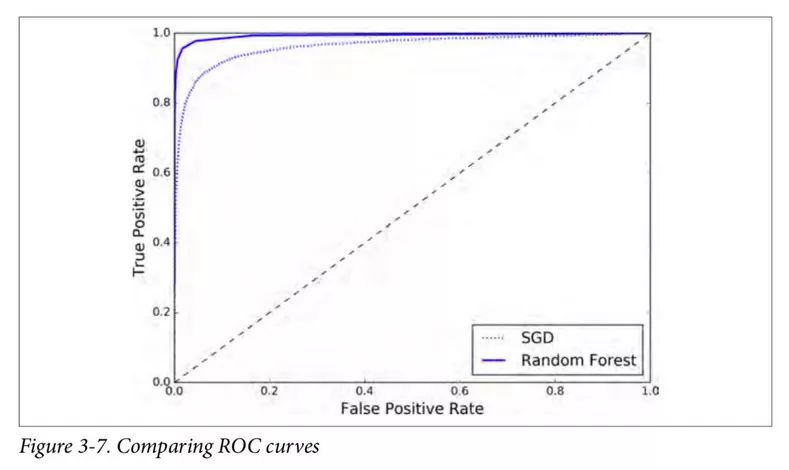
如你所见,RandomForestClassifier的 ROC 曲线比SGDClassifier的好得多:它更靠近左上角。所以,它的 ROC AUC 也会更大。
>>> roc_auc_score(y_train_5, y_scores_forest) 0.99312433660038291
计算一下准确率和召回率:98.5% 的准确率,82.8% 的召回率。还不错。
现在你知道如何训练一个二分类器,选择合适的标准,使用交叉验证去评估你的分类器,选择满足你需要的准确率/召回率折衷方案,和比较不同模型的 ROC 曲线和 ROC AUC 数值。现在让我们检测更多的数字,而不仅仅是一个数字 5。
-
NIUSB6009 采集准确率的问题?2024-09-23 7615
-
请问AFE4400 SPO2精度和准确率如何?2025-01-15 384
-
TF之LoR:基于tensorflow实现手写数字图片识别准确率2018-12-19 2615
-
基于RBM实现手写数字识别高准确率2018-12-28 2976
-
请问谁做过蚁群算法选择图像特征,使识别准确率最高?2019-02-17 3457
-
如何提高Stm32F746G准确率?2023-01-12 546
-
BOM准确率提高方法2011-06-13 6213
-
交大教授训练机器通过面部识别罪犯 准确率达到86%以上2016-12-01 1317
-
深度学习:我国成功研发智能辅助驾驶系统,准确率世界先进水平2018-03-31 5197
-
阿里达摩院公布自研语音识别模型DFSMN,识别准确率达96.04%2018-06-07 4522
-
人脸识别准确率大幅度提升,离不开科技企业的努力2018-09-30 2347
-
AI垃圾分类的准确率和召回率达到99%2020-06-16 4369
-
ai人工智能回答准确率高吗2024-10-17 11995
-
微机保护装置预警功能的准确率2024-11-03 1123
-
电能质量在线监测装置识别谐波源的准确率有多高?2025-10-22 1055
全部0条评论

快来发表一下你的评论吧 !
