

基于开源鸿蒙的语音识别及语音合成应用开发样例
描述
【拆·应用】是为开源鸿蒙应用开发者打造的技术分享平台,是汇聚开发者的技术洞见与实践经验、提供开发心得与创新成果的展示窗口。诚邀您踊跃发声,期待您的真知灼见与技术火花!
引言
本期内容由AI Model SIG提供,介绍了在开源鸿蒙中,利用sherpa_onnx开源三方库进行ASR语音识别与TTS语音合成应用开发的流程。
ASR/TTS介绍
ASR也就是自动语音识别(Automatic Speech Recognition),其主要作用是把人类语音里的词汇内容转变为计算机能够读取的文本形式。
TTS也就是文本转语音(Text-to-Speech),它主要的功能是把计算机里以文本形式存在的信息转变成人耳可听见的语音。
ASR/TTS有着广泛的用途,例如语音助手聊天、设备控制、新闻播报、有声阅读等。
Sherpa_onnx介绍
sherpa-onnx是一个开源语音处理工具包,具有轻量级、跨平台和高性能的语音识别推理能力。它基于ONNX Runtime,支持CPU/GPU加速,且内存占用低、延迟小,适合实时流式语音处理。它兼容多种 端到端语音模型(如Transformer、RNN-T),提供简洁的C++/Python API,并支持动态断句和流式识别,开箱即用。相比传统方案(如Kaldi),sherpa_onnx依赖更少、部署更简单,特别适合 移动端、离线语音助手、实时字幕等场景兼顾效率与易用性。
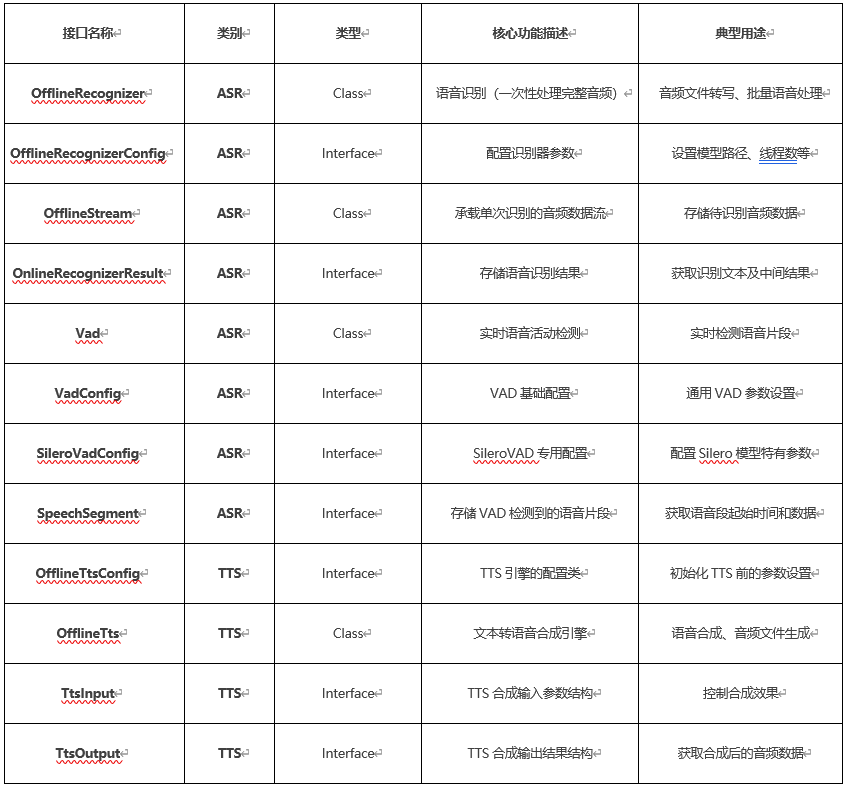
sherpa_onnx已经移植到开源鸿蒙,直接支持ArkTS接口,本示例用到的接口如下:
开发准备
1.环境搭建:确保安装了ArkUI开发所需的IDE,如DevEco Studio,并配置好相应的开发环境,包括SDK(本示例Api11及以上)版本等。
2.了解ArkUI框架特性:熟悉ArkUI的布局和组件使用方法,例如文本输入框用于接收用户输入,按钮组件用于触发ASR语音识别操作等。还要了解ArkUI的数据绑定机制,方便将ASR识别结果和TTS合成状态等信息实时显示在界面上。
示例界面设计
底部栏:语音采集与文本输入切换按钮,点击切换。
中间区:文本显示区,呈现识别后文本和输入内容。
头部栏:标题、语音播放按钮(播放中间区域文本)、设置按钮(语速设置和声音模型切换)。

示例功能逻辑
示例基于sherpa_onnx三方库开发,此库在OpenHarmony三方库中心仓下载安装,链接如下:
https://ohpm.openharmony.cn/#/cn/detail/sherpa_onnx

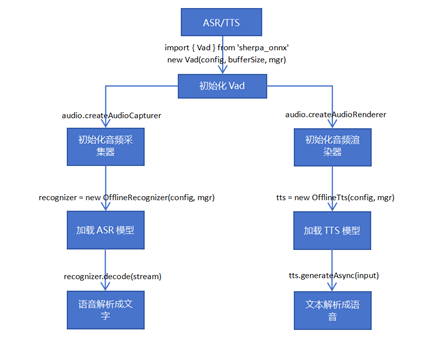
以下所展示的是本示例的流程图,该流程图涵盖了从Vad声音活动检测的初始化阶段,音频采集器与渲染器初始化过程,接着是ASR(自动语音识别)模型和TTS(文本到语音)模型的加载,直至最终成功实现语音识别与语音生成的流程。
ASR模型解析核心实现
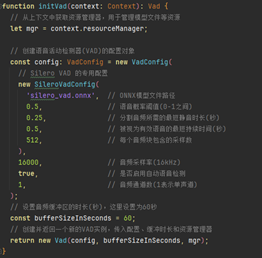
1.初始化Vad
Vad声音活动检测(Voice activity detection),也称为语音活动检测或语音检测(speech activity detection或者speech detection),是检测人类语音存在与否的技术,主要用于语音处理。Vad的主要用途在于说话人分割(speaker diarization)、语音编码(speech coding)和语音识别(speech recognition),初始化vad过程如下:
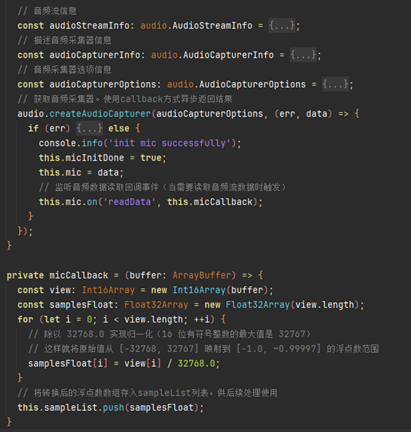
2.初始化音频采集器
初始化一个音频采集器,用于从麦克风硬件获取音频数据,注册回调事件micCallback将音频数据存储到ampleList数组中。
3.加载ASR模型
语音识别需要加载一个ASR模型,用户可依据自身业务需求下载合适的模型,模型下载地址:
https://github.com/k2-fsa/sherpa-onnx/releases/tag/asr-models。
本示例使用的是sherpa-onnx-sense-voice-zh-en-ja-ko-yue-2024-07-17模型,支持中文、英文、日文、韩文以及粤语五种语言。
将解压后的模型文件放入指定路径中。
路径:src/main/resources/rawfile
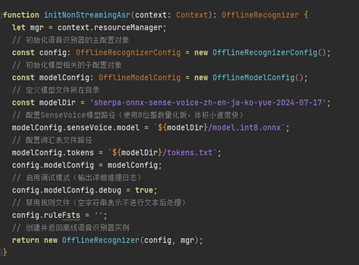
创建语音识别实例OfflineRecognizer,加载该模型。
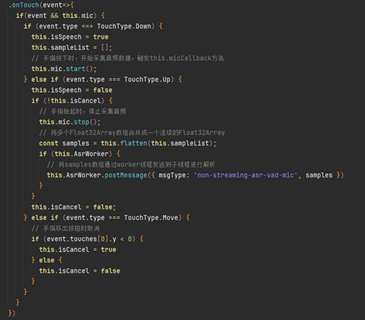
4.语音解析成文字
“按住说话”按钮,当手指按下时采集音频数据,触发micCallback回调保存数据,手指抬起时终止采集,随后,将数据经由worker线程发送至子线程予以解析。
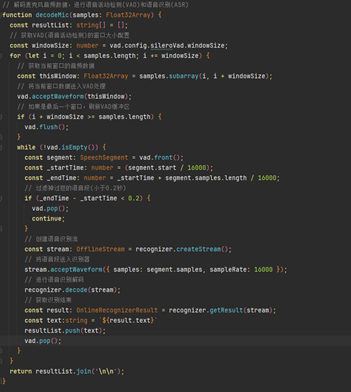
子线程在获取音频数据之后,将其解析为文字,最终呈现在应用界面上,具体解析流程如下:
TTS模型解析核心实现
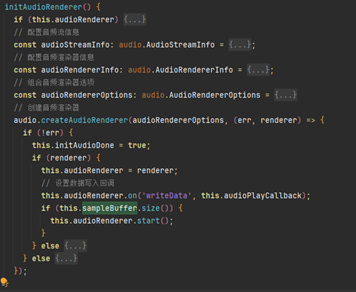
1.初始化音频渲染器
初始化一个音频渲染器,用于将音频数据输出到设备扬声器。通过配置音频参数和渲染属性,确保音频格式与硬件兼容,并建立数据写入的回调机制audioPlayCallback。
2.加载TTS模型
语音合成需要加载一个TTS模型,用户可依据自身业务需求下载合适的模型,模型下载地址:
https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models。
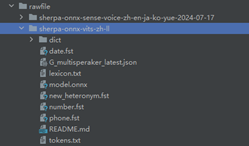
其中有多种文本转语音模型,本示例选用了6种TTS模型,用在设置界面切换不同的声音。
将解压后的模型文件放到指定的路径下。
路径:src/main/resources/rawfile
创建语音识别实例OfflineTts,加载该模型:
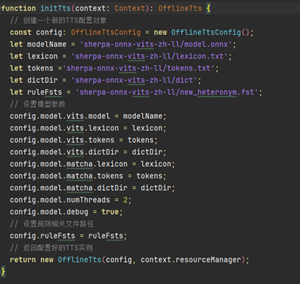
加载完TTS模型后,获取模型相关信息,音频采样率、说话人(音色)数量,CPU线程数(本示例为双线程)。
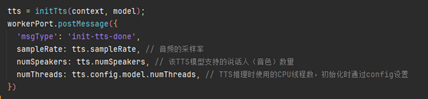
3.文本解析成音频
点击播放图标,播放或暂停可将中间区域的文字以语音形式予以播放。
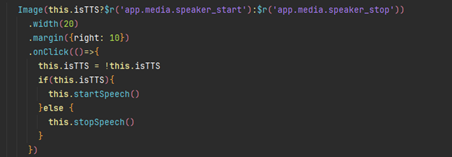
将文本信息通过worker发送至子线程进行语音合成;
text为输入文本,当界面上无文字时默认“你好”,有文字时,将文字以句号分割,使播放句子有停顿效果;
sid说话人音色(模型相关信息numSpeakers)参数选择(通常0 ≤ sid ≤ numSpeakers);
speed语速,默认语速为1,可在设置界面调节。
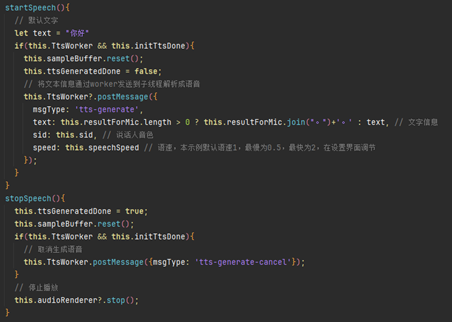
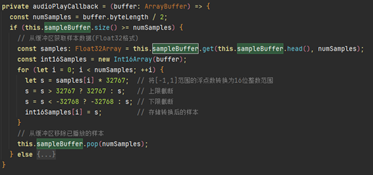
使用tts.generateAsync方法把文字转化为语音,TtsInput为TTS合成输入参数,文字转成语音后,数据由worker回传至主线程。
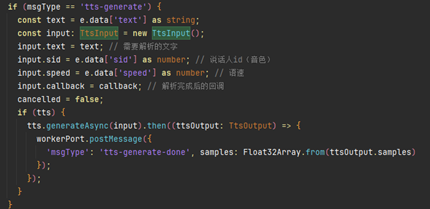
接收到语音数据后,将数据存储在sampleBuffer数组,然后通过this.audioRenderer.start()触发语音播放。
效果展示
ASR/TTS示例应用代码
代码仓链接:https://gitcode.com/openharmony-sig/applications_ai_model_samples/tree/master/AsrAndTts
AI Model SIG简介
AI Model SIG 是经开源鸿蒙PMC(项目管理委员会)正式批准成立的特别兴趣小组(SIG),核心目标是丰富开源鸿蒙生态下的大小应用模型,并提供端到端的实践范例,为开发者构建 AI 应用提供高效支撑。
未来,AI Model SIG 将围绕三大方向持续深耕:
聚焦模型推理框架与多推理后端的深度适配,夯实 AI 能力底层基座;
推进多模态模型的生态适配与优化,拓展 AI 应用场景边界;
将技术成果分享出来,确保广大开发者可便捷获取与使用。
同时,小组将联合全球开发者协同共建,持续完善开源鸿蒙 AI 技术体系,助力打造更具竞争力的全场景智能终端生态。
如果您对开源鸿蒙AI技术感兴趣,欢迎加入AI Model SIG,一起探索万物智联的未来!
-
基于开源鸿蒙的图片编辑开发样例(1)2025-10-31 3351
-
明远智睿SSD2351开发板:语音机器人领域的变革力量2025-05-28 803
-
离线语音识别与在线语音识别有什么不一样?2023-12-12 3103
-
使用Arduino进行语音识别和合成2022-11-17 2275
-
[CB5654智能语音开发板测评] 语音识别开发板的比较2022-03-09 4486
-
【1024平头哥开发套件开发体验】 语音识别开发板的比较2021-12-13 2382
-
使用语音控制的鸿蒙小车开发流程2020-11-24 2068
-
【HarmonyOS HiSpark AI Camera】居家语音智能识别控制2020-10-29 764
-
语音合成IC选型之经验分享2020-05-19 3170
-
语音合成IC与语音IC的两三事2020-05-13 3516
-
语音合成芯片与语音芯片对比2019-03-08 7680
-
语音识别模块2015-09-01 6685
全部0条评论

快来发表一下你的评论吧 !
