

深度学习高效化与专用处理芯片设计
电子说
描述
“夫因朴生文,因拙生巧,相因相生,以至今日。”在人工智能领域,机器学习研究与芯片行业的发展,即是一个相因相生的过程。自第一个深度网络提出,深度学习历经几次寒冬,直至近年,才真正带来一波AI应用的浪潮,这很大程度上归功于GPU处理芯片的发展。与此同时,由于AI应用场景的多元化,深度学习在端侧的应用需求日益迫切,也促使芯片行业开展面向深度学习的专用芯片设计。如果能够将深度算法与芯片设计相结合,将大大拓展AI的应用边界,真正将智能从云端落地。本文中,来自中科院自动化所的程健研究员,将带着大家一方面探索如何将深度学习高效化,另一方面讨论如何针对深度算法来设计专用处理芯片。文末,提供文中提到参考文献的下载链接。
上图是本次汇报的大纲,主要从深度学习发展现状、面临的挑战、神经网络加速算法设计、深度学习芯片设计和对未来的展望五个方面来展开。

首先我们来看一下深度学习的发展现状。毋庸置疑的是深度学习目前在各个领域都取得了一些突破性的进展,上图展示了深度学习目前广泛应用的领域。

深度学习近年来取得的长足发展离不开三个方面,上图展示了其不可或缺的三个要素。一是随着互联网的发展产生的大数据,二是游戏行业的发展促使的如GPU计算资源的迅速发展,三是近年来研究者们对于深度学习模型的研究。在目前的情况下,给定一个应用场景,我们可以使用大量的数据和计算资源搭建非常深的网络模型来达到比较高的性能。然而在实际应用中,这些复杂网络由于需要很高的计算量难以很好地部署到设备上以满足实际应用的需求,所以如何减少深度神经网络计算量,成为深度学习领域中的研究热点。

另一方面,面向深度学习设计的芯片也受到了越来越多的关注。目前一些通用的芯片如CPU不能很好地适应神经网络这种计算量非常密集的操作,而计算能力强大的GPU由于其价格和功耗因素很难在大量终端设备上部署。所以如何设计一个面向深度学习的专用芯片达到速度和功耗的要求是目前比较火热的研究方向。

虽然现在对神经网络模型设计和深度学习芯片设计的研究很多,但依旧面临很多挑战。
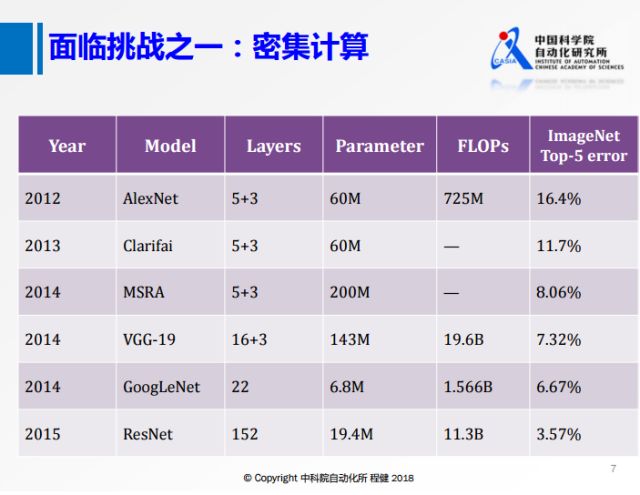
面临的挑战之一是越来越复杂的网络模型,上图展示了近年来主流网络模型的参数和计算量等信息。可以看出随着网络规模越来越大,网络结构越来越复杂,由此带来的越来越大的计算量会是一个挑战。

面临的挑战之二是深度学习复杂多变的应用场景,主要包括在移动设备上算不好、穿戴设备上算不了、数据中心算不起三个方面。由于移动设备和可穿戴设备本身硬件比较小,允许运行的计算量非常有限,在面临非常复杂多变的应用场景的时候,往往不能满足实际需求。而目前存在的一些移动中心的计算由于其代价昂贵使得大多数人只能望而却步。
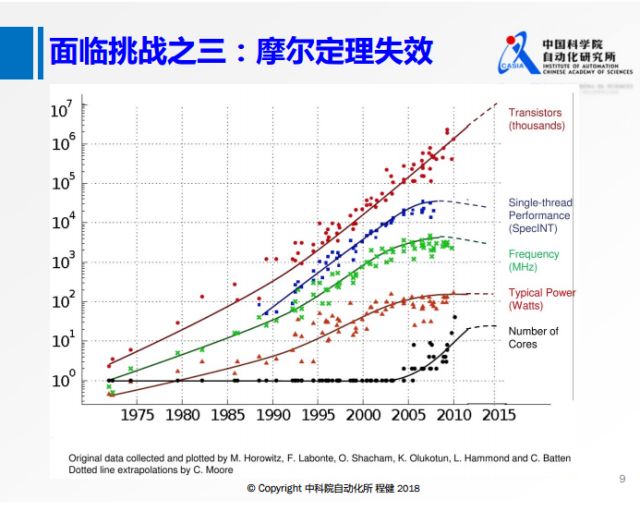
面临的挑战之三是近年来摩尔定理随着时间推移的失效,不能像以前一样仅仅依靠在硬件上堆叠晶体管来实现物理层面的性能提升。

目前深度学习面临的三个挑战促使我们从两个方面去思考,一是网络模型本身优化的问题,二是设计面向深度学习专用芯片来实现神经网络的高效计算。下面分别从这两个方面进行阐述。
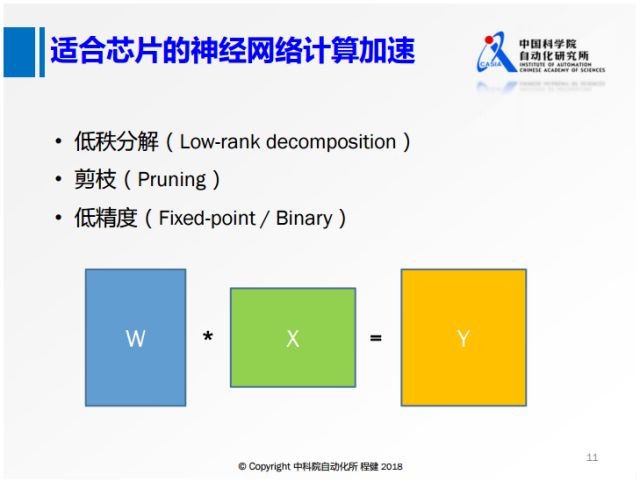
在深度学习模型的优化计算方面,包括一些最近几年研究的工作,上图展示了三种方式,下面主要列出了一些比较适合芯片的神经网络加速计算的方法。
首先对于神经网络大部分的计算,无论是卷积层还是全连接层都可以转换成矩阵乘的基础操作,上图展示了这个过程,所以对矩阵乘进行加速的方法都可以引入到神经网络的加速中来,包括低秩分解、网络稀疏化、低精度表示等方法。
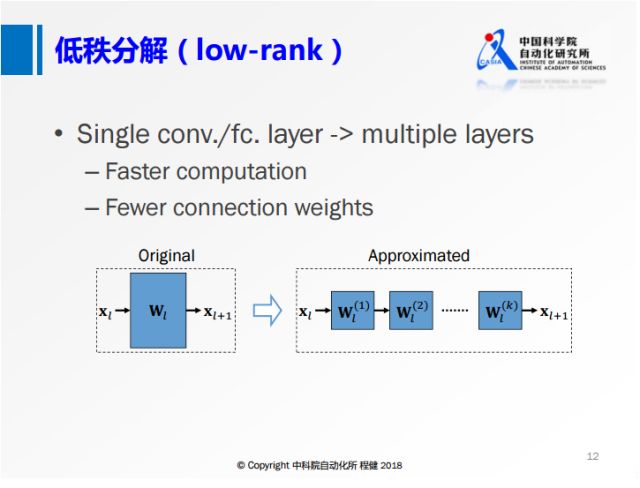
上图展示了低秩分解的基本思想,将原来大的权重矩阵分解成多个小的矩阵,右边的小矩阵的计算量都比原来大矩阵的计算量要小,这是低秩分解的基本出发点。
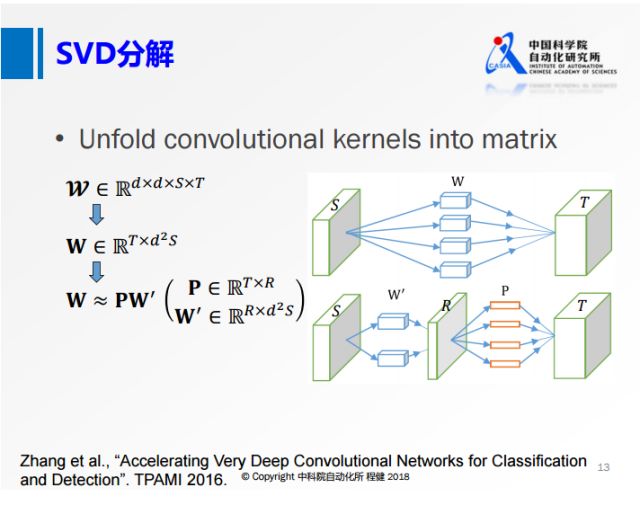
低秩分解有很多方法,最基本的是奇异值分解SVD。上图是微软在2016年的工作,将卷积核矩阵先做成一个二维的矩阵,再做SVD分解。上图右侧相当于用一个R的卷积核做卷积,再对R的特征映射做深入的操作。从上面可以看到,虽然这个R的秩非常小,但是输入的通道S还是非常大的。
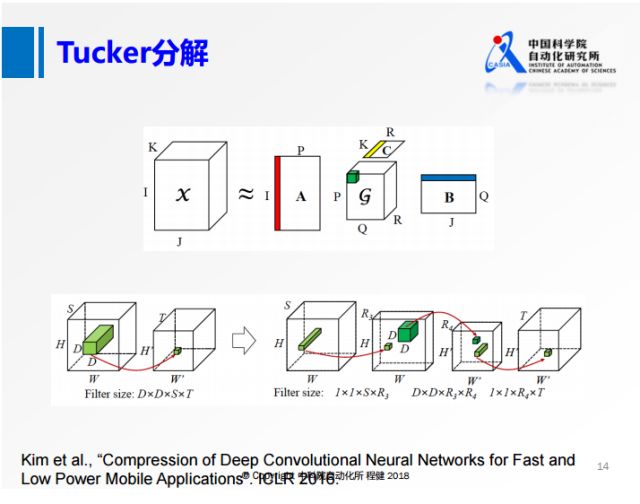
为了解决SVD分解过程中通道S比较大的问题,我们从另一个角度出发,沿着输入的方向对S做降维操作,这就是上图展示的Tucker分解的思想。具体操作过程是:将原来的卷积,首先在S维度上做一个低维的表达,再做一个正常的3×3的卷积,最后再做一个升维的操作。
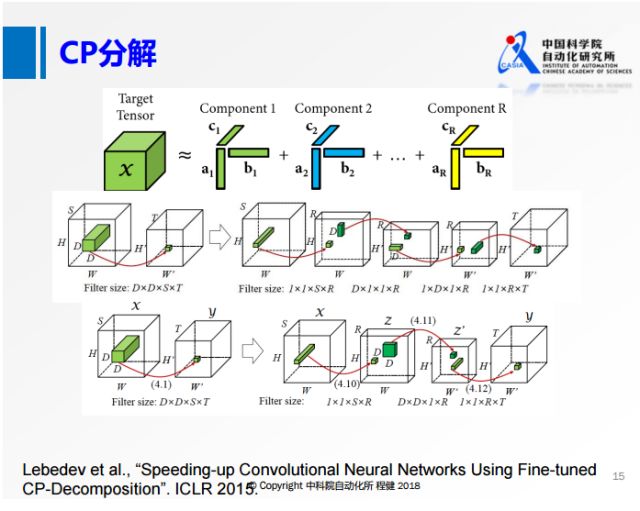
在SVD分解和Tucker分解之后的一些工作主要是做了更进一步的分解。上图展示了使用微调的CP分解加速神经网络的方法。在原来的四维张量上,在每个维度上都做类似1×1的卷积,转化为第二行的形式,在每一个维度上都用很小的卷积核去做卷积。在空间维度上,大部分都是3×3的卷积,所以空间的维度很小,可以转化成第三行的形式,在输入和输出通道上做低维分解,但是在空间维度上不做分解,类似于MobileNet。
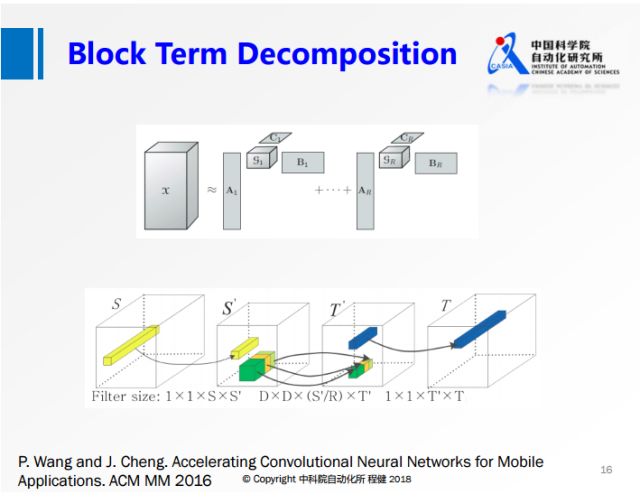
上图展示了我们在2016年的工作,结合了上述两种分解方法各自的优势。首先把输入参数做降维,然后在第二个卷积的时候,做分组操作,这样可以降低第二个3×3卷积的计算量,最后再做升维操作。另一方面由于分组是分块卷积,它是有结构的稀疏,所以在实际中可以达到非常高的加速,我们使用VGG网络在手机上的实验可以达到5-6倍的实际加速效果。
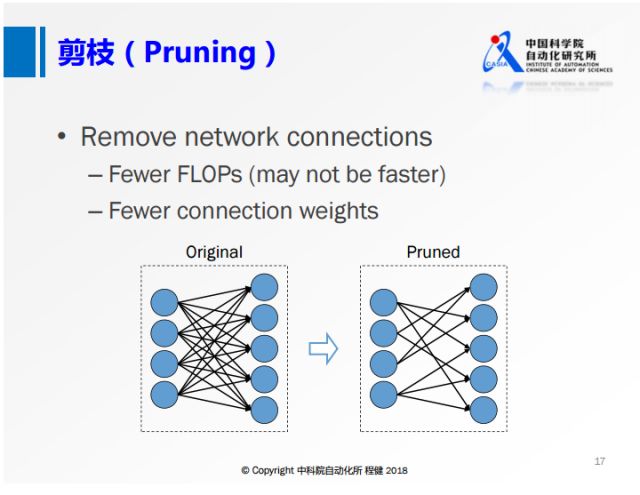
第二个方面是网络的剪枝,基本思想是删除卷积层中一些不重要的连接。
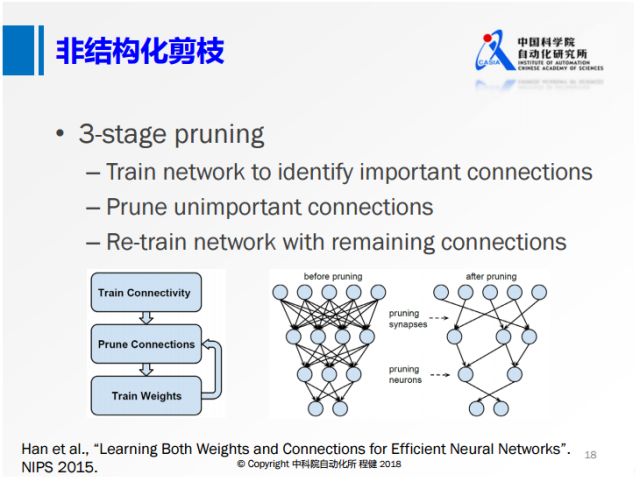
上图展示了在NIP2015上提出的非常经典的三阶段剪枝的方法。首先训练一个全精度网络,随后删除一些不重要的节点,后面再去训练权重。这种非结构化的剪枝的方法,虽然它的理论计算量可以压缩到很低,但是收益是非常低的,比如在现在的CPU或者GPU框架下很难达到非常高的加速效果。所以下面这种结构化的剪枝技术越来越多。
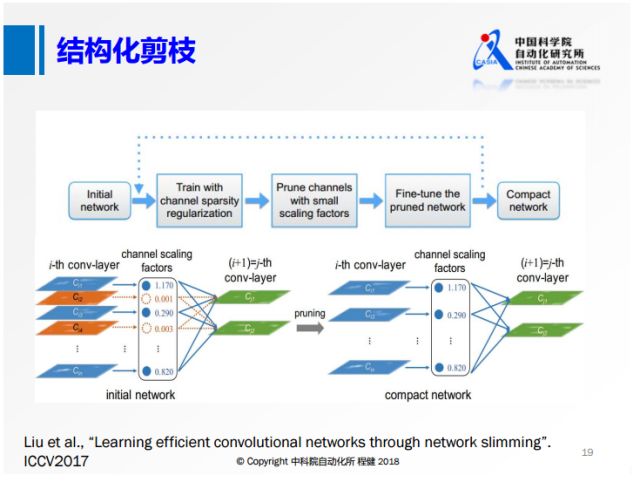
从去年的ICCV就有大量基于channel sparsity的工作。上面是其中的一个示意图,相当于对每一个feature map定义其重要性,把不重要的给删除掉,这样产生的稀疏就是有规则的,我们可以达到非常高的实际加速效果。
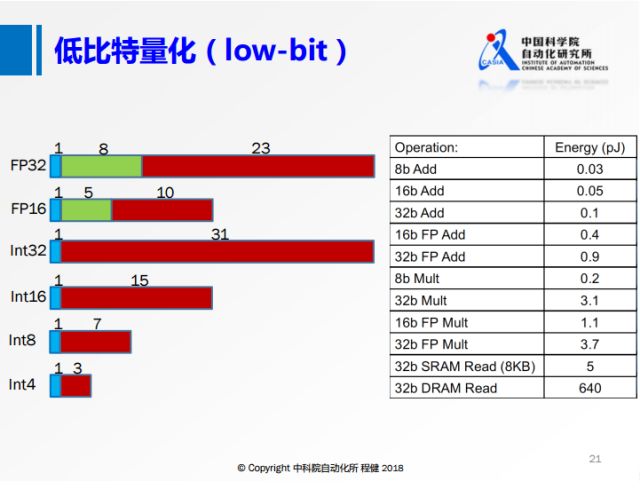
第三个方面是低比特量化,上图展示了具体操作方法。目前的低比特量化方法和上面提到的低秩分解、网络剪枝这两种方法是可结合的。左侧是不同的比特数在计算机上的存储方式,右侧是不同操作的功耗。可以看出来低比特的功耗远远小于高比特浮点数操作的功耗。

上图是在定点表示里面最基本的方法:BNN和BWN。在网络进行计算的过程中,可以使用定点的数据进行计算,由于是定点计算,实际上是不可导的,于是提出使用straight-through方法将输出的估计值直接传给输入层做梯度估计。在网络训练过程中会保存两份权值,用定点的权值做网络前向后向的计算,整个梯度累积到浮点的权值上,整个网络就可以很好地训练,后面几乎所有的量化方法都会沿用这种训练的策略。前面包括BNN这种网络在小数据集上可以达到跟全精度网络持平的精度,但是在ImageNet这种大数据集上还是表现比较差。
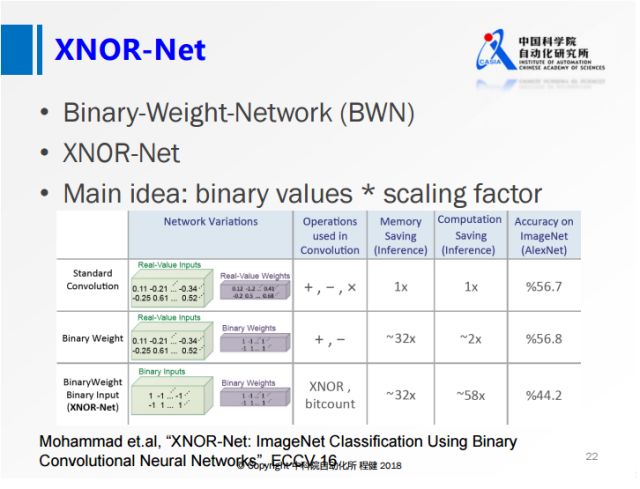
上图展示了ECCV2016上一篇名为XNOR-Net的工作,其思想相当于在做量化的基础上,乘了一个尺度因子,这样大大降低了量化误差。他们提出的BWN,在ImageNet上可以达到接近全精度的一个性能,这也是首次在ImageNet数据集上达到这么高精度的网络。

上图展示了阿里巴巴冷聪等人做的通过ADMM算法求解binary约束的低比特量化工作。从凸优化的角度,在第一个优化公式中,f(w)是网络的损失函数,后面会加入一项W在集合C上的loss来转化为一个优化问题。这个集合C取值只有正负1,如果W在满足约束C的时候,它的loss就是0;W在不满足约束C的时候它的loss就是正无穷。为了方便求解还引进了一个增广变量,保证W是等于G的,这样的话就可以用ADMM的方法去求解。
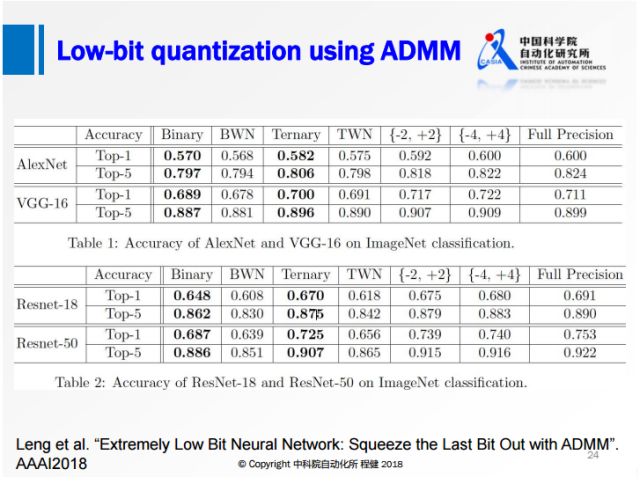
他们在AlexNet和ResNet上达到了比BWN更高的精度,已经很接近全精度网络的水平。

上图是我们今年通过Hashing方法做的网络权值二值化工作。第一个公式是我们最常用的哈希算法的公式,其中S表示相似性,后面是两个哈希函数之间的内积。我们在神经网络做权值量化的时候采用第二个公式,第一项表示输出的feature map,其中X代表输入的feature map,W表示量化前的权值,第二项表示量化后输出的feature map,其中B相当于量化后的权值,通过第二个公式就将网络的量化转化成类似第一个公式的Hashing方式。通过最后一行的定义,就可以用Hashing的方法来求解Binary约束。
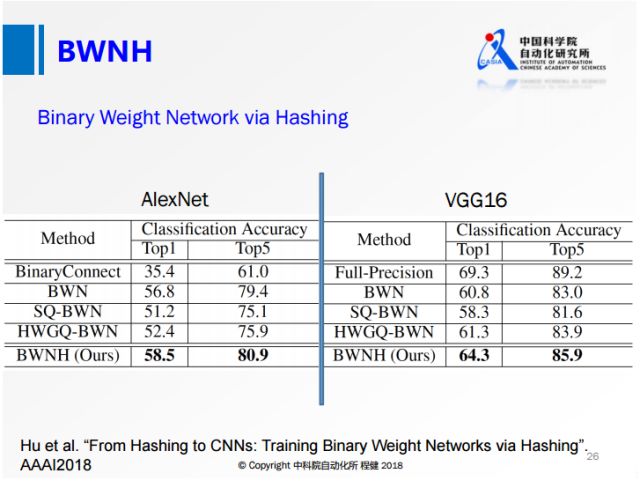
我们做了实验,达到了比之前任何一个网络都高的精度,非常接近全精度网络的性能。
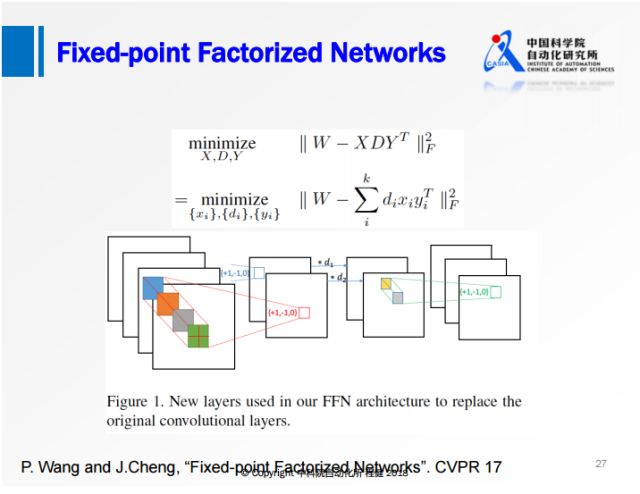
上图是我们在CVPR2017上的工作。实际中借助了矩阵分解和定点变换的优势,对原始权值矩阵直接做一个定点分解,限制分解后的权值只有+1、-1、0三个值。将网络变成三层的网络,首先是正常的3×3的卷积,对feature map做一个尺度的缩放,最后是1×1的卷积,所有的卷积的操作都有+1、-1、0。
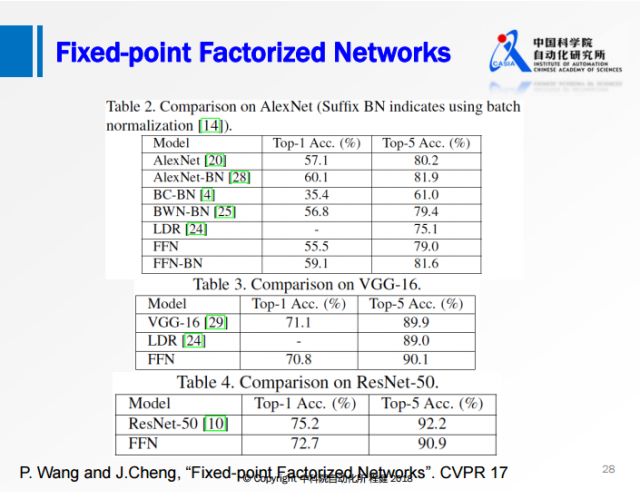
上图是我们在ImageNet数据集上与流行的网络模型做的对比实验,可以看出我们提出的FFN与一些网络相比已经达到甚至超过全精度网络的性能;虽然与ResNet-50相比还存在一些性能上的损失,但是相比之前的方法损失已经小了很多。

下面讲述一些专门针对深度学习芯片设计的工作。
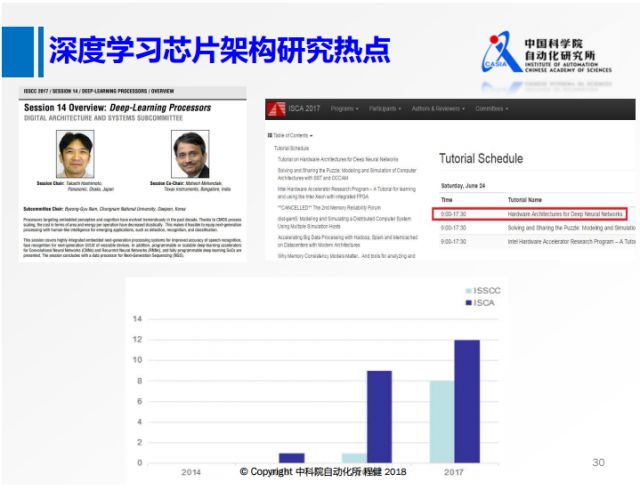
上图是2017年芯片设计两个顶会ISCA和ISSCC上与deep learning相关session情况,这两个会议上都有专门针对深度学习的讨论可以看出深度学习对芯片设计产生了巨大影响。
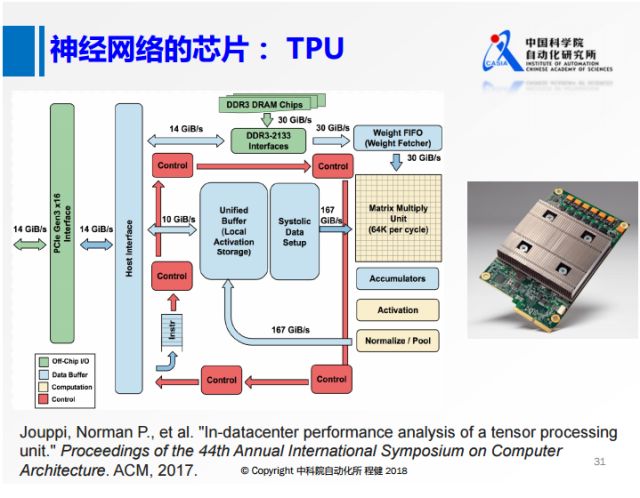
首先是上图中谷歌在2017年推出的的TPU,设计了矩阵基本乘法的单元,使用int8来表示,还专门针对芯片上包括权值的所有数据设计了一些缓冲区域。
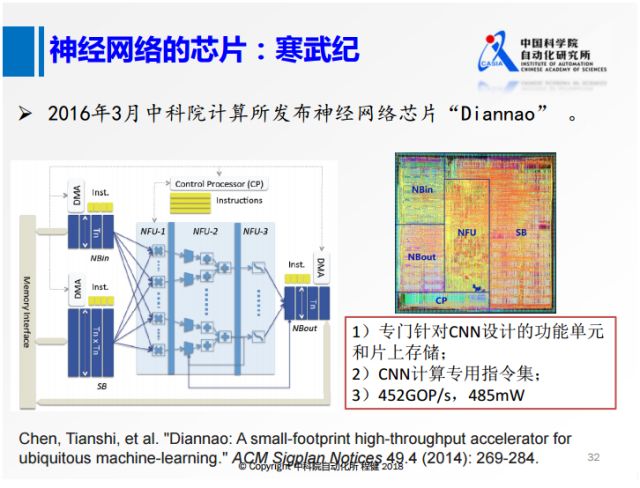
上图是中科院计算所研发的寒武纪。它在思想上实际和TPU有一点相似,实际中专门针对CNN设计了一些计算单元,还对常用的一些卷积神经网络中的操作专门设计了一些指令,这样芯片可以达到452GOP/s的高速度和485Mw的低功耗。
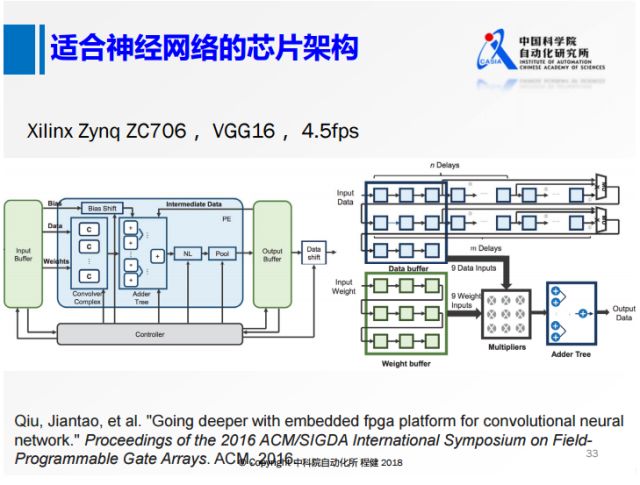
上图是清华大学2016年在FPGA平台上使用了VGG16所做的早期工作,采用类似正常网络的计算思路,在FPGA上实现了VGG16,可以达到4.5帧每秒的速度。
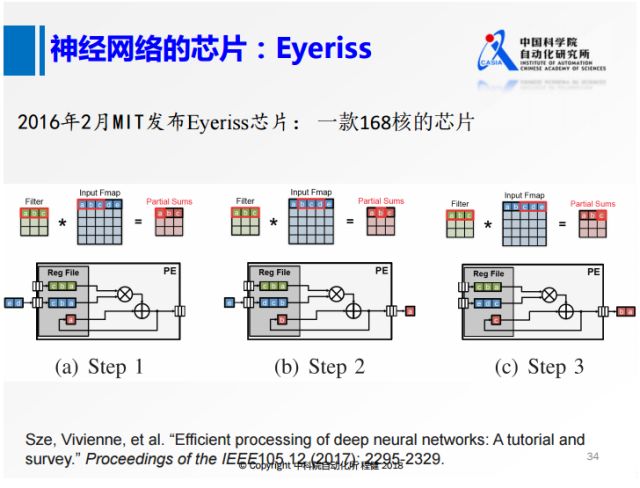
上图是MIT发布的一款名为Eyeriss的芯片,把正常的3×3卷积核操作做差分运算,将每一行做一个类似的处理,在卷积核进来以后,对整个feature map扫描以后,再把数据给抛掉。
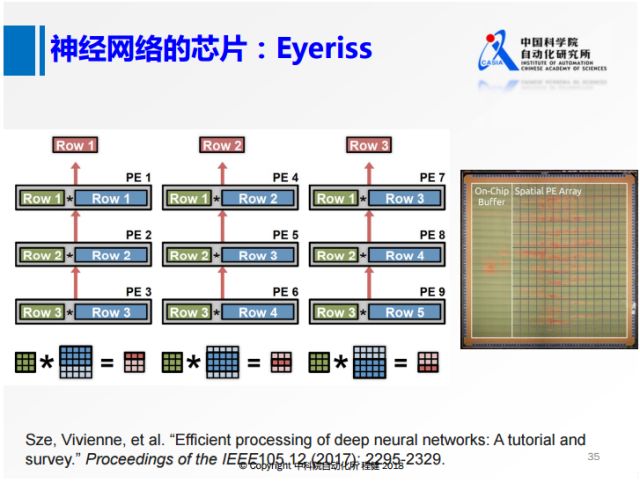
上面对3×3的卷积核的处理只是针对一行,如果并行处理三行,就是上面这张图。将三行都保存在片上,蓝色的部分相当于特征,对其使用类似于一个流水线的方式进行处理,最左边的图表示一二三,中间是三三四,右边是三四五,用这种方式把feature map在芯片上所有位置的响应都计算出来。
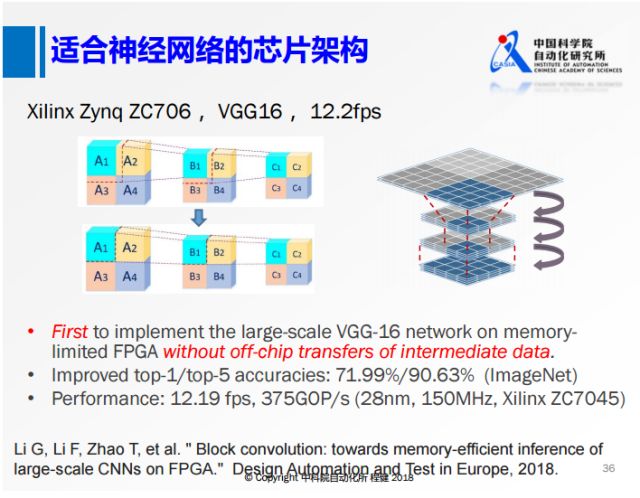
上面是我们2018年在DATE上的工作,我们和清华大学使用相同的板子做了VGG16。我们的出发点是这样的,由于VGG16的feature map非常大,所以在计算过程中我们不可避免地需要在内存和板子上搬数据,这会带来非常大的功耗。如果我们一次要搬这个数据的话,无论是从功耗还是速度的角度都有很大的损失。我们从算法和硬件结合的角度考虑,首先从算法上对神经网络进行分块的操作,将上面正常的卷积,分成2×2的四块,本来从A1计算B1的时候需要A2和A3的信息,现在在算法的层面把这些依赖都去掉,就可以转化成下面的这种方式。所有对B1的计算只依赖于A1,得到B1以后不需要等B2和B3的计算结果,就可以直接使用B1去计算C1,而且还可以把A1、B1、C1的操作做层之间的合并,这样计算时延非常低,并且我们在整个网络的运算过程中不需要大量的内存,从而大幅提高了神经网络的计算速度。

下面谈一谈我们能看到的对神经网络未来的展望。

1. 首先前面提到的二值化方法大多都是针对权值的二值化,对这些网络的feature map做8比特的量化,很容易达到类似于feature map是浮点数的性能。如果我们能够把feature map也做成binary的话,无论是在现有的硬件还是在专用的硬件上都可以达到更好的性能。但是性能上还有很大损失。所以如何更高效地二值化网络也是未来研究的热点。
2. 目前在训练阶段的一些量化操作都是针对测试阶段的。如果我们要设计一款有自主学习能力的芯片,则需要在训练的阶段实现量化,我们可以在芯片实际使用的时候在线更新权值,这是未来发展的一个趋势。
3. 另一个方面是不需要重新训练,或者只需要无监督训练的网络加速与压缩方法。现在的网络加速方法都是做了一些网络压缩以后还要做大量的fine-tuning操作,但是实际使用中用户给定一个网络,如果我们可以使用不需要重新训练,或者我们只是用一部分不带标签的数据就可以对这个网络进行压缩的话,这是一个非常有实用价值的研究方向。
4. 面向不同的任务,现在进行加速的方法,包括面向深度学习的芯片,大部分都是针对分类任务去做的。但是在实际应用中,分类是一个最基础的工作,而像目标检测、图像分割的应用也非常的广泛,对这些任务进行加速也是非常重要的问题。
5. 单独做神经网络或芯片架构的优化都很难做得非常好,两个方面结合起来协同优化会更好。这些就是我们能看到的一些未来的发展。
-
FPGA做深度学习能走多远?2024-09-27 0
-
一款高质量多速率语音专用处理器芯片的设计2009-10-06 0
-
专用处理器,未来电机驱动的主流2015-12-31 0
-
采用专用处理器实现电机驱动方案2019-07-26 0
-
专用处理器技术在嵌入式系统中应用间题研究2009-05-09 419
-
应用处理器专用电源2008-11-26 437
-
新芯片架构瞄准深度学习和视觉处理2016-11-03 1895
-
寒武纪科技将发布深度学习专用处理器2017-10-11 1112
-
Google正式发布了第三代AI人工智能/机器学习专用处理器TPU 3.02018-05-11 2127
-
富士通DLU深度学习芯片今年可望开始出货2018-05-24 4534
-
可编程语音压缩专用处理器设计2018-10-31 397
-
装有专用处理引擎的Zynq UltraScale+ MPSoC介绍2018-11-23 3035
-
应用处理器芯片行业科普2022-01-25 541
-
芯易荟发布首款领域专用处理器生成工具FARMStudio2023-04-12 1058
-
什么是专用处理器?专用处理器的设计方法和工具介绍2023-07-17 1532
全部0条评论

快来发表一下你的评论吧 !
