

利用卷积神经网络识别对象,估算骨骼模型
电子说
描述
我们已经介绍过很多单目的动作捕捉方案,最近的单目动捕方案可以说大同小异,在原理上基本没有什么区别,都是利用卷积神经网络识别对象,估算骨骼模型,再在此基础上进行渲染。这些解决方案的困难也都类似,例如老大难的遮挡问题,脚踝处的识别和骨骼模型往往估计不准等等。
最近,清华、北航、南加州大学、马克思普朗克研究所等的研究人员合作了一篇论文DoubleFusion: Real-time Capture of Human Performances with Inner Body Shapes from a Single Depth Sensor,提出了一种叫做DoubleFusion、基于单个深度摄像头的解决方案,对人体动作捕捉识别有更好的效果。
简单地讲,DoubleFusion的原理是这样的,一般深度摄像头的动作捕捉来源于深度数据,因此可以构建人身体的表面形状(即包含衣服在内的外形数据),但这种方案难以在有遮挡的情况下实现捕捉,为了补足深度捕捉的缺憾,DoubleFusion将它和估算骨架模型的方案融合了起来,因此形成了一个“双层表面表示”,外层是深度数据得到的表面重建的数据,内层则是骨架模型数据,最终计算得到最合理的动作数据。我们看到的完整的身体模型,实际上是内外两层数据相互制约、相互融合的结果。
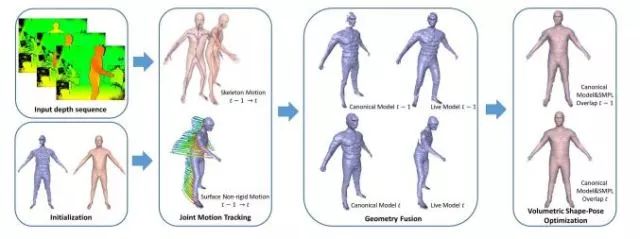
具体来说,DoubleFusion的输入只有捕获的深度数据,而输出是捕捉目标的双层表面。在骨架估计方面,它采用最近出现的基于Mask-RCNN的模型SMPL,可以非常迅速的得到比较完美的骨架模型,在外表数据方面,采用同样是近年来提出的捕获方法DynamicFusion。外表数据生成一个节点图,主要用于判断姿势变化方式,骨架数据同样形成节点图,主要用作判据,尽量避免姿势变化中违法骨骼连接的情况。
那么,这个方案的实际效果如何?
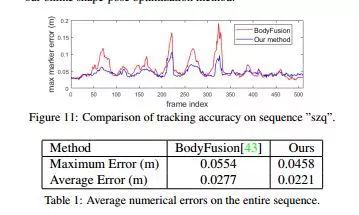
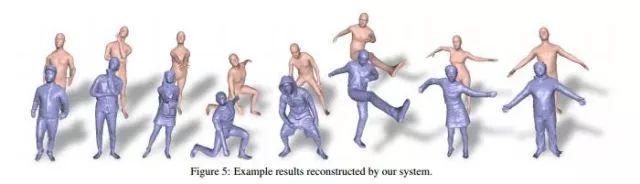
DoubleFusion方案比单方面骨架模型估计的方案效果更好,例如与BodyFusion相比较, 后者即使较紧身的衣服也会对结果产生影响,而前者捕捉的结果更为干净、完整;另外DoubleFusion的每帧最大误差更小,而且平均误差也较小,在捕捉快速运动期间表现也要更好,还有,实时重建的身体形状和显示的目标穿着看起来也要更合理一些。

从性能上来说,测试环境中,DoubleFusion每一帧执行6次ICP迭代,进行关节运动跟踪需要21毫秒,9毫秒用于体积形状和身体姿态的优化;另外,输入的深度数据属于异步运行处理,算上运行时间不到1毫秒,综合下来基本是每帧32毫秒。
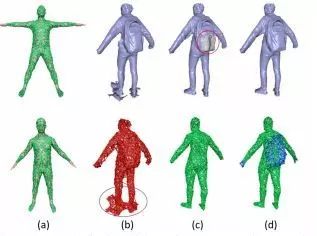
然而,这种解决方案还是存在限制,例如,当用户穿着较厚的衣服时,这个方案在捕捉过程中会将衣服的厚度都当成人的身体来计算,导致身体建模的误差出现;另外,目前的方案还无法处理人物对象之间的交互,不过按照论文的说法,这将会在未来的研究中得到解决。
最后,必须要说的是,这篇论文提出的解决方案效果可能比较好,但要实现它,深度摄像头至少是必须品,而现在的市场上仍然有很大一部分智能手机没有深度摄像头,否则之前的普通摄像头单目动捕也不至于备受关注。从这个方面来说,论文中解决方案的实用价值可能并没有我们想象中那么大。
-
卷积神经网络训练的是什么2024-07-03 1319
-
卷积神经网络的应用 卷积神经网络通常用来处理什么2023-08-21 6112
-
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法2023-08-17 2184
-
卷积神经网络简介:什么是机器学习?2023-02-23 25379
-
卷积神经网络模型发展及应用2022-08-02 13207
全部0条评论

快来发表一下你的评论吧 !
