

“一芯四用”,米尔RK3576如何同时驾驭4路YOLOv8视频流?
描述
在科技飞速发展的当下,人工智能与边缘计算的融合正以前所未有的速度重塑着我们的生活。RK3576芯片拥有4核Cortex-A72以及4核Cortex-A53提供基础算力,6TOPS算力NPU来模型推导运算。使用YOLOv8模型时也是手到擒来,接下来随着步伐看看它表现如何。
YOLO简介
YOLO(You Only Look Once)是当前业界领先的实时目标检测算法系列,以其速度和精度的完美平衡而闻名。从它发布至今,经历了好几个版本变革,下图是它发展历史。
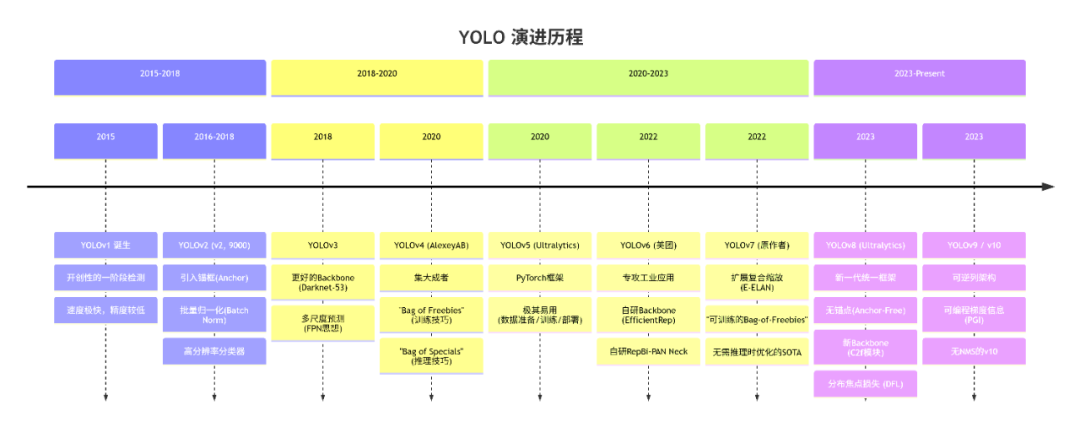
图1-1. YOLO版本发展史
YOLOv8在性能、易用性、架构现代性和生态之间取得了最佳的平衡,它是目前最全面,最省心选择。
同样YOLOv8也有很多尾缀,用一个表简单列一下它们分别代表什么意思:
表1-1.按任务类型区分
后缀
| 全称
| 任务
| 输出
| 典型应用
|
-det
| Detection
| 目标检测
| 边界框 (BBox)+类别和置信度
| 找出图像中所有感兴趣的物体并用框标出。如:行人检测、车辆检测、安全帽检测。
|
-seg
| Segmentation
| 实例分割
| 边界框+类别+像素级掩膜 (Mask)
| 在目标检测的基础上,进一步勾勒出物体的精确轮廓。如:抠图、自动驾驶中识别道路和车辆形状。
|
-pose
| Pose
| 关键点检测
| 边界框+人体关键点(17个点)
| 检测人体的关键骨骼点。如:动作识别、健身姿态分析、人机交互。
|
-cls
| Classification
| 图像分类
| 整个图像的类别标签
| 判断一张图片属于哪个类别。如:猫狗分类、图像质量评估。
|
-obb
| Oriented Bounding Boxes
| 旋转目标检测
| 旋转边界框(BBox+角度θ)+类别和置信度
| 检测带有角度的物体,其边界框不是水平的。
|
表1-2.按模型尺寸分
前缀
| 含义
| 特点
| 适用场景
|
n
| Nano
| 极小的模型,速度最快,精度最低
| 移动端、嵌入式设备(如 Jetson Nano)、CPU实时推理
|
s
| Small
| 小模型,速度和精度平衡
| 最常用的起点,适合大多数需要实时性的场景(如视频流分析)
|
m
| Medium
| 中等模型,精度和速度的最佳权衡
| 对精度有较高要求,且仍有不错的速度
|
l
| Large
| 大模型,精度高,速度较慢
| 服务器端应用,其中精度比速度更重要
|
x
| X-Large
| 超大模型,精度最高,速度最慢
| 学术研究、刷榜、对精度有极致要求的离线分析
|
米尔Demo模型选择
基于MYD-LR3576来说,选择s/n小模型相对合适,使用基础功能和-seg,-obb,-pos来演示。
单独测试视频场景
1.YOLOv8s.int 目标检测模型
2.YOLOv8s-seg.int 实例分割模型
3.YOLOv8s-pose.int 人体姿态估计模型
4.YOLOv8s-obb.float 旋转目标检测模型
上面已经看到了单独解析视频时,每一种模型效果,接下来演示MYD-LR3576通过4路摄像头同时推导效果。
实现方式如下:
MYD-LR3576拥有3路MIPI-CSI接口,通过3个MY-CAM004M分别接入3路MIPI-CSI,采用2+1+1方式搭载4路AHD高清摄像头,摄像头采集的画面输出为H.264编码的RTSP码流,1920*1080分辨率,30帧。经过MYD-LR3576开发板处理后,单路视频输出1920*1080,25fps,4路视频加起来在60~70帧,cpu占用率接近100%,NPU综合利用率在50~60%。
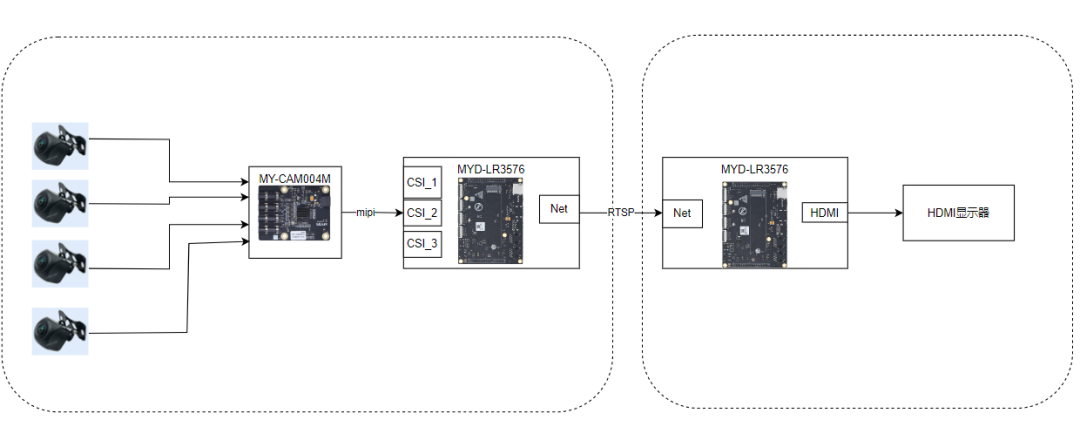
图1-2. 实物接线概要图
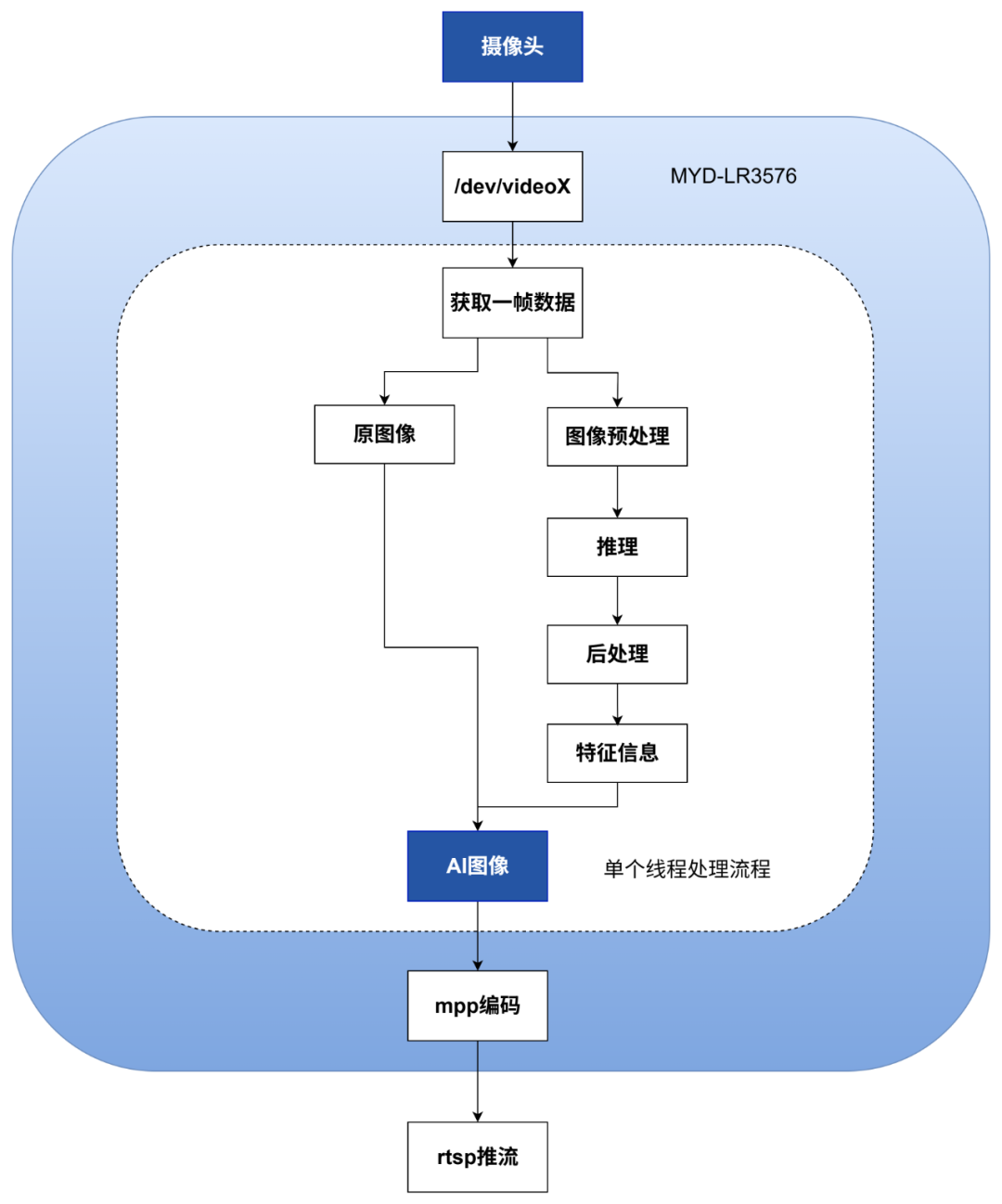
图1-3. 摄像头数据处理流程图
MYIR在程序中做了哪些优化
AI推导一轮流程
获取CSI一帧数据
裁剪数据到xxx*yyy较小图片
调用RKNN api处理
获取返回特征位置和相似度
对应放大到原始图片
增加方框和相似度值到原图
这样做后果是CPU利用率不高,视频采集帧数低,最后显示效果会卡顿。
米尔采用线程池方案,将上述过程通过线程处理,充分利用4个A72和4个A53资源,同时采用RGA来做图片裁剪和放大。将CPU,GPU,NPU,VPU4个模块协同工作,资源最大限度开发使用。
总结:
RK3576 在 YOLOv8 模型表现上十分亮眼,它的应用场景涉及到很多领域。例如智能安防,在公共场所,如机场、火车站、商场等,部署的安防监控系统,快速准确地识别出人群中的异常行为,如打架斗殴、奔跑逃窜等,并及时发出警报,同时,通过人脸识别技术,系统可以对进入场所的人员进行身份识别,与数据库中的信息进行比对,实现对重点人员的监控和追踪。又或者搭载智能机器人赋予迅速反馈。
更多MYD-LR3576创新应用,敬请期待。
-
米尔RK3576+Hailo-8突破6 TOPS极限,让高帧率摄像头真正“实时”2026-04-02 1036
-
迅为如何在RK3576上部署YOLOv5;基于RK3576构建智能门禁系统2025-11-25 2209
-
车载360环视平台:米尔RK3576开发板支持12路低延迟推流2025-10-11 1307
-
360环视硬件平台为什么推荐使用米尔RK3576开发板?2025-09-19 2370
-
12 路低延迟推流!米尔 RK3576 赋能智能安防 360° 环视2025-09-18 1333
-
单板挑战4路YOLOv8!米尔瑞芯微RK3576开发板性能实测2025-09-12 3586
-
【作品合集】米尔RK3576开发板测评2025-09-11 60411
-
RK3576助力智慧安防:8路高清采集与AI识别2025-08-22 2365
-
12路1080P高清视频流,米尔RK3576 开发板赋能车载360环视2025-08-14 10523
-
米尔瑞芯微RK3576实测轻松搞定三屏八摄像头2025-01-17 2599
-
【米尔RK3576开发板评测】+项目名称值得购买的米尔RK3576开发板2025-01-08 2594
-
米尔RK3576和RK3588怎么选?-看这篇就够了2024-12-27 2074
-
【米尔RK3576开发板评测】带你初步了解米尔RK3576这块开发板2024-12-18 2888
全部0条评论

快来发表一下你的评论吧 !
