

如何快速简单地训练神经网络?
电子说
描述
如何快速简单地训练神经网络?谷歌大脑研究人员研究了CNN的可训练性,提出了一种简单的初始化策略,不需要使用残差连接或批标准化,就能训练10000层的原始CNN。作者表示,他们的这项工作清除了在训练任意深度的原始卷积网络时存在的所有主要的障碍。
2015年,ResNet横空出世,以令人难以置信的3.6%的错误率(人类水平为5-10%),赢得了当年ImageNet竞赛冠军,在图像分类、目标检测和语义分割各个分项都取得最好成绩,152层顺序堆叠的残差模块让业界大为赞叹。
此后,ResNet作为训练“极”深网络的简单框架,得到了广泛的应用,包括最强版本的AlphaGo——AlphaGo Zero。
此后,随着神经网络向着更深、更大的规模发展,性能不断提高的同时,也为训练这样的网络带来了越来越大的挑战。虽然现在有类似谷歌AutoML的项目,将设计和优化神经网络的工作,交给神经网络自己去做,而且效果还比人做得更好。但是,AI研究者还是在思考,为什么残差连接、批标准化等方法,会有助于解决梯度消失或爆炸的问题。
在谷歌大脑研究人员发表于ICML 2018的论文《CNN动态等距和平均场论》(Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,000-Layer Vanilla Convolutional Neural Networks)中,他们对CNN的可训练性和信号在卷积网络中的传输特点进行了研究,并拓展了此前关于深度学习平均场论(Mean Field Theory)的工作。
他们发现,卷积核在空间上的分布情况扮演了很重要的角色:当使用在空间上均匀分布的卷积核对CNN做初始化时,CNN在深度上会表现得像全连接层;而使用在空间上不均匀分布的卷积核时,信号在深度网络中就表现出了多种传输模式。
基于这一观察,他们提出了一个简单的初始化策略,能够训练10000层乃至更深的原始CNN结构。
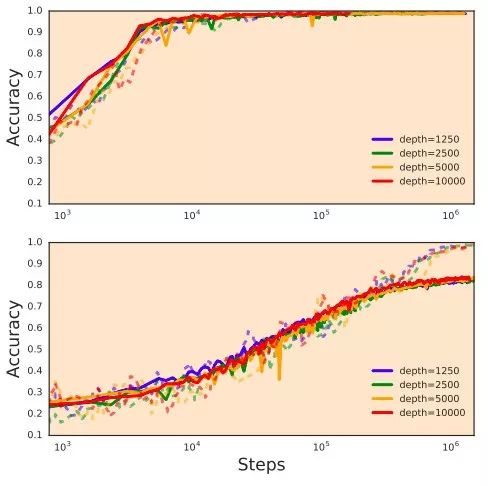
不用残差连接,也不用批标准化,只用一个简单的初始化策略,就能训练10000层深度的网络。上图为在MNIST数据集的结果,下图是CIFAR10,实线是测试,训练是训练。来源:论文
作者表示,他们的这项工作提供了对残差连接、批标准化等实践方法的理论理解。“残差连接和批标准化(Batch Normalization)这些结构上的特征,可能在定义好的模型类(model class)中有着重要的作用,而不是仅仅简单地能够提高训练的效率。”
CNN可以被训练的深度,就是信号能完全通过的层数
在物理学和概率论中,平均场论(Mean Field Theory,MFT)是对大且复杂的随机模型的一种简化。未简化前的模型通常包含数量巨大且存在相互作用的小个体。
平均场理论则做了这样的近似:对于某个独立的小个体,所有其他个体对它产生的作用可以用一个平均的量给出,这样简化后的模型就成了一个单体问题。
这种思想源于皮埃尔·居里(对,就是居里夫人的老公)和法国物理学家皮埃尔·外斯(Pierre-Ernest Weiss)对相变的研究。现在,平均场论广泛用于如传染病模型、排队论、计算机网络性能和博弈论当中。
在深度学习领域,平均场论也得到了研究。这些研究都揭示了一点,那就是在初始化阶段,信号能在网络中传输的深度存在一个最大值,而深度网络之所以能够被训练,恰恰是因为信号能够全部通过这些层。
平均场论预测信号在网络中传输深度存在一个最大值,这也就是网络可以被训练的深度
在这项工作中,作者基于平均场论开发了一个理论框架,研究深度CNN中信号的传播情况。通过研究信号在网络中向前和向后传播而不衰减的必要条件,他们得出了一个初始化方案,在不对网络的结构进行任优化(比如做残差连接、批标准化)的情况下,这个方案能帮助训练超级深——10000乃至更深的原始CNN。
简单初始化策略,训练10000层原始CNN
那么,这个初始化方案是什么呢?先从结论说起,就是这个算法:

这是一个生成随机正交卷积核的算法,目的是为了实现动态等距(dynamical isometry)。
大家都知道,深度神经网络中权重的初始化会对学习速度有很大的影响。实际上,深度学习建立在这样一个观察之上,即无监督的预训练为随后通过反向传播进行的微调提供了一组好的初始权重。
这些随机权重的初始化主要是由一个原理驱动,即深度网络雅可比矩阵输入-输出的平均奇异值应该保持在1附近。这个条件意味着,随机选择的误差向量在反向传播时将保持其范数。由于误差信息在网络中进行忠实地、等距地反向传播,因此这个条件就被称为“动态等距”。
对深度线性网络学习的非线性动力学的精确解进行理论分析后发现,满足了动态等距的权重初始化能够大大提高学习速度。对于这样的线性网络,正交权重初始化实现了动态等距,并且它们的学习时间(以学习轮数的数量来衡量)变得与深度无关。
这表明深度网络雅可比矩阵奇异值的整个分布形状,会对学习速度产生巨大的影响。只有控制二阶矩,避免指数级的梯度消失和爆炸,才能留下显著的性能优势。
现在,最新的这项研究发现,在卷积神经网络中也存在类似的情况。作者将要传播的信号分解为独立的傅里叶模式,促进这些信号进行均匀的传播。由此证明了可以比较容易地训练10000层或更多的原始CNN。
清除训练任意深度原始CNN的所有主要障碍
在ICLR 2017的一篇论文中,谷歌的研究人员,包括深度学习教父 Geoffrey Hinton 和谷歌技术大牛 Jeff Dean在内,提出了一个超大规模的神经网络——稀疏门控混合专家层(Sparsely-Gated Mixture-of-Experts layer,MoE)。
MoE 包含上万个子网络(也即“专家”),每个专家都有一个简单的前馈神经网络和一个可训练的门控网络(gating network),门控网络会选择专家的一个稀疏组合来处理每个输入。
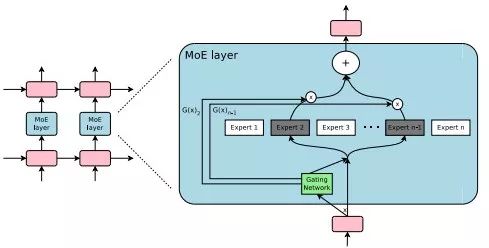
嵌入在循环语言模型中的混合专家(Mixture of Experts,MoE)模块。在这种情况下,稀疏门函数选择两个专家来执行计算,它们的输出由门控网络的输出控制。
最终的网络虽然是含有1370亿个参数的庞然大物,但由于实现了条件计算的好处,模型容量得到了超过1000倍的提升,而计算效率只有相对微小的损失。MoE在大规模语言建模和机器翻译基准测试中,花费很小的计算力实现了性能的显著提升。这项工作也是深度网络条件计算在产业实践中的首次成功。
2017年6月,Facebook人工智能实验室与应用机器学习团队合作,提出了一种新的方法,能够大幅加速机器视觉任务的模型训练过程,仅 1 小时就训练完ImageNet这样超大规模的数据集。Facebook 团队提出的方法是增加一个新的预热阶段(a new warm-up phase),随着时间的推移逐渐提高学习率和批量大小,从而帮助保持较小的批次的准确性。
现在,谷歌大脑的这项工作,提供了对这些实践方法的理论理解。作者在论文中写道,
我们的结果表明,我们已经清除了在训练任意深度的原始卷积网络时存在的所有主要的障碍。在这样做的过程中,我们也为解决深度学习社区中的一些突出问题奠定了基础,例如单凭深度是否可以提高泛化性能。
我们的初步结果表明,在一定的深度上,在几十或几百层的这个数量级上,原始卷积结构的测试性能已经饱和。
这些观察结果表明,残差连接和批标准化(Batch Normalization)这些结构上的特征,可能在定义好的模型类(model class)中有着重要的作用,而不是仅仅简单地能够提高训练的效率。
这一发现对深度学习研究社区有着重大的意义。不用批标准化,也不用残差连接,仅仅通过一个初始化函数,就训练10000层的原始CNN。
即使你不训练10000层,这个初始化带来的训练速度提升也是可观。
不过,作者目前只在MNIST和CIFAR10数据集上验证了他们的结果,推广到更大的数据集后情况会如何,还有待观察。
-
在Ubuntu20.04系统中训练神经网络模型的一些经验2025-10-22 324
-
人工神经网络原理及下载2008-06-19 9933
-
当训练好的神经网络用于应用的时候,权值是不是不能变了?2016-10-24 4644
-
请问Labveiw如何调用matlab训练好的神经网络模型呢?2018-07-05 9422
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3326
-
简单神经网络的实现2019-09-11 2164
-
【AI学习】第3篇--人工神经网络2020-11-05 4313
-
基于光学芯片的神经网络训练解析,不看肯定后悔2021-06-21 3049
-
matlab实现神经网络 精选资料分享2021-08-18 1762
-
优化神经网络训练方法有哪些?2022-09-06 1763
-
如何进行高效的时序图神经网络的训练2022-09-28 3217
-
如何训练和优化神经网络2024-07-01 1887
-
卷积神经网络训练的是什么2024-07-03 2021
-
怎么对神经网络重新训练2024-07-11 1617
-
脉冲神经网络怎么训练2024-07-12 2173
全部0条评论

快来发表一下你的评论吧 !
