

如何利用Python网络爬虫抓取微信朋友圈的动态信息
描述
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门。不过不要慌,小编在网上找到了第三方工具,它可以将朋友圈进行导出,之后便可以像我们正常爬虫网页一样进行抓取信息了。
就提供了这样一种服务,支持朋友圈导出,并排版生成微信书。本文的主要参考资料来源于这篇博文:
感谢大佬提供的接口和思路。具体的教程如下。
一、获取朋友圈数据入口
1、关注公众号【出书啦】
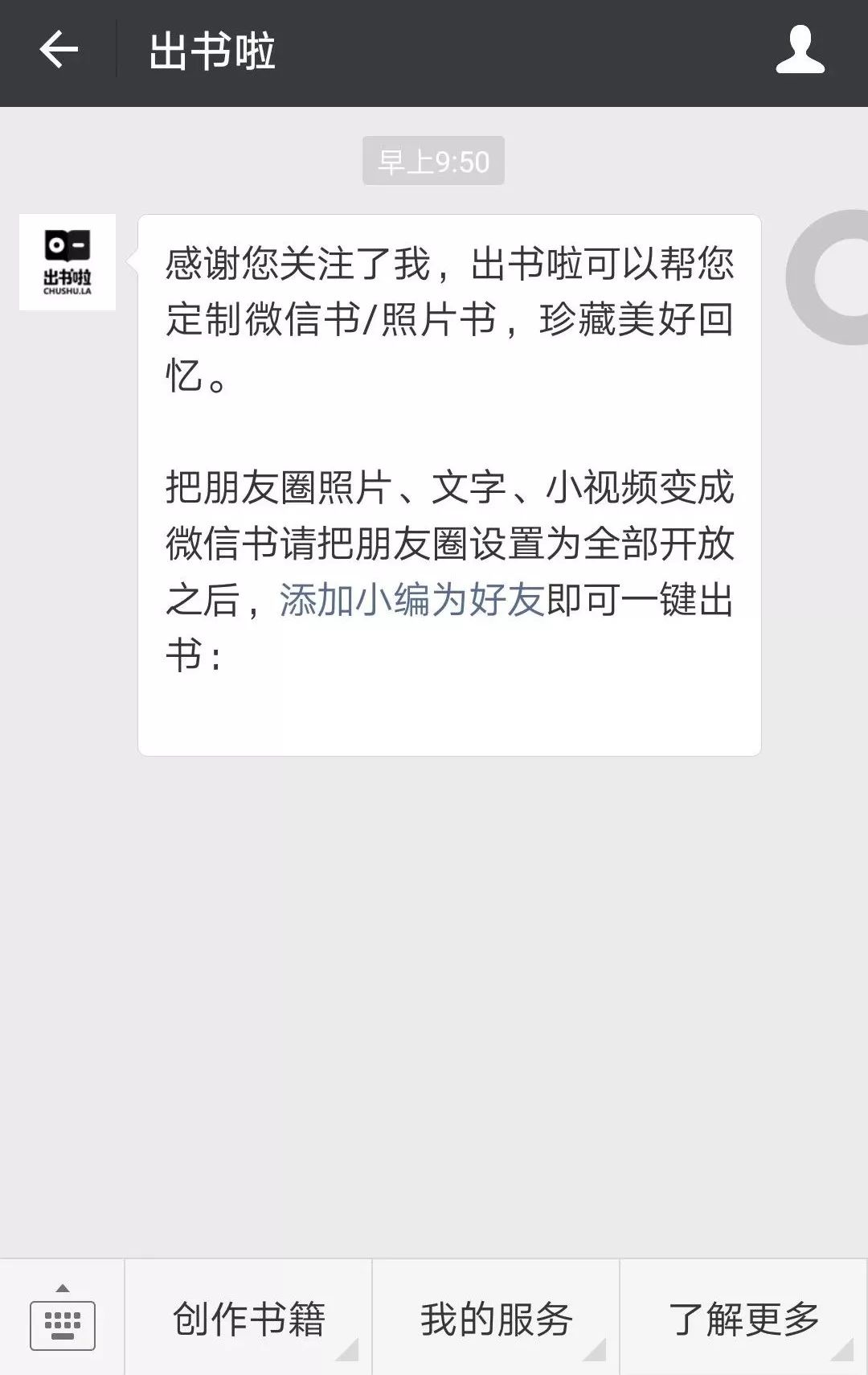
2、之后在主页中点击【创作书籍】-->【微信书】。
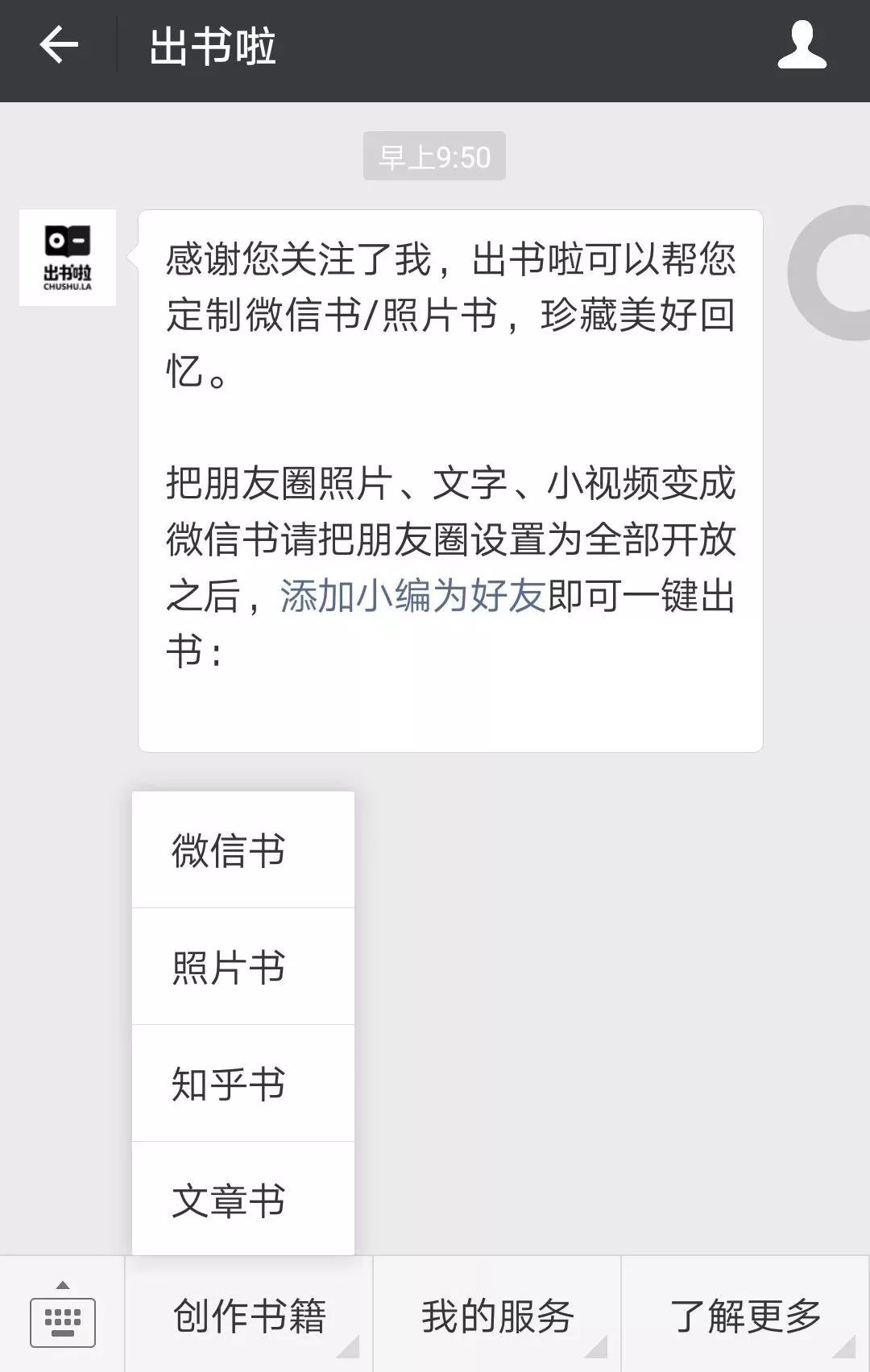
3、点击【开始制作】-->【添加随机分配的出书啦小编为好友即可】,长按二维码之后便可以进行添加好友了。
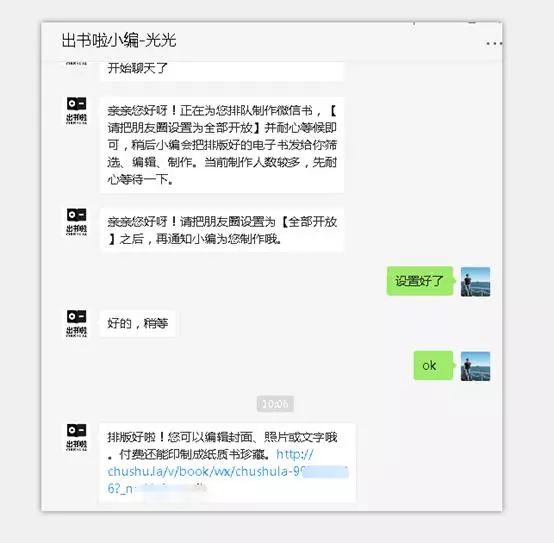
4、之后耐心等待微信书制作,待完成之后,会收到小编发送的消息提醒,如下图所示。
至此,我们已经将微信朋友圈的数据入口搞定了,并且获取了外链。
确保朋友圈设置为【全部开放】,默认就是全部开放,如果不知道怎么设置的话,请自行百度吧。
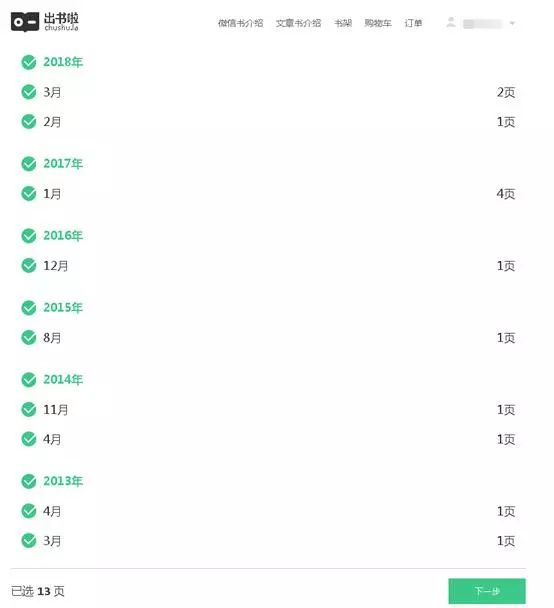
5、点击该外链,之后进入网页,需要使用微信扫码授权登录。
6、扫码授权之后,就可以进入到微信书网页版了,如下图所示。
7、接下来我们就可以正常的写爬虫程序进行抓取信息了。在这里,小编采用的是Scrapy爬虫框架,Python用的是3版本,集成开发环境用的是Pycharm。
二、创建爬虫项目
1、确保您的电脑上已经安装好了Scrapy。之后选定一个文件夹,在该文件夹下进入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
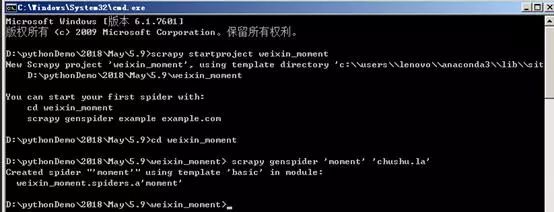
2、在命令行中输入cd weixin_moment,进入创建的weixin_moment目录。之后输入命令:
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图所示。
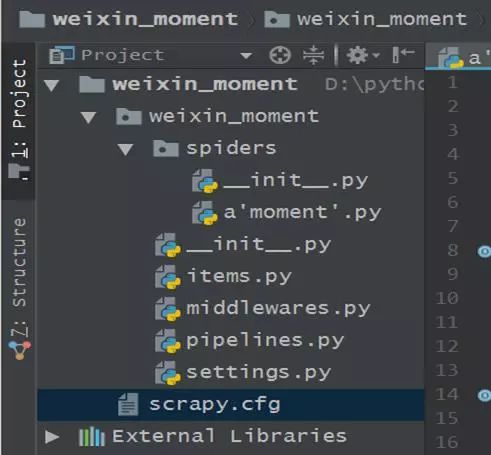
3、执行以上两步后的文件夹结构如下:
三、分析网页数据
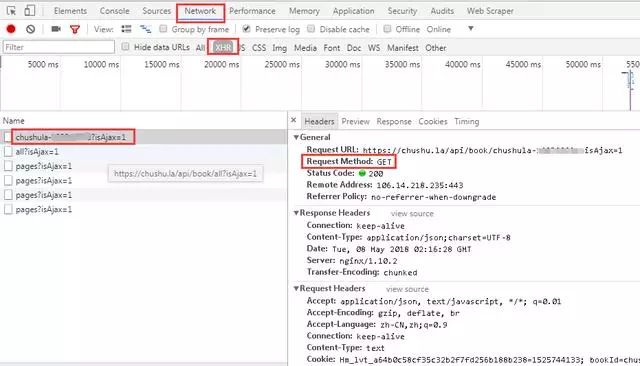
1、进入微信书首页,按下F12,建议使用谷歌浏览器,审查元素,点击“Network”选项卡,然后勾选“Preserve log”,表示保存日志,如下图所示。可以看到主页的请求方式是get,返回的状态码是200,代表请求成功。
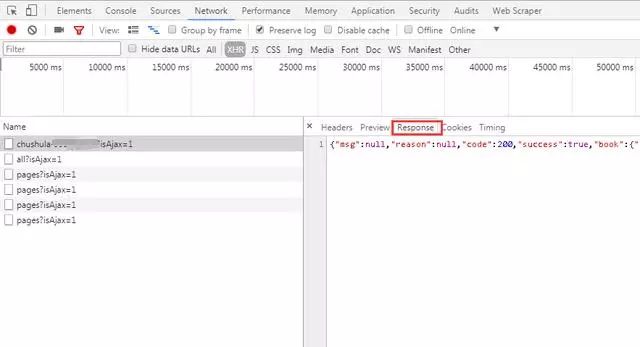
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明我们之后在程序中需要对JSON格式的数据进行处理。
3、点击微信书的“导航”窗口,可以看到数据是按月份进行加载的。当点击导航按钮,其加载对应月份的朋友圈数据。
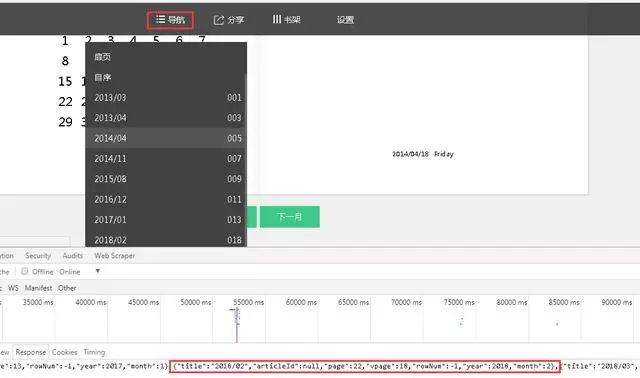
4、当点击【2014/04】月份,之后查看服务器响应数据,可以看到页面上显示的数据和服务器的响应是相对应的。
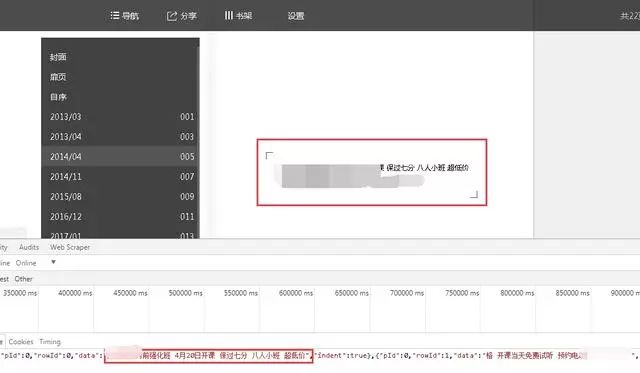
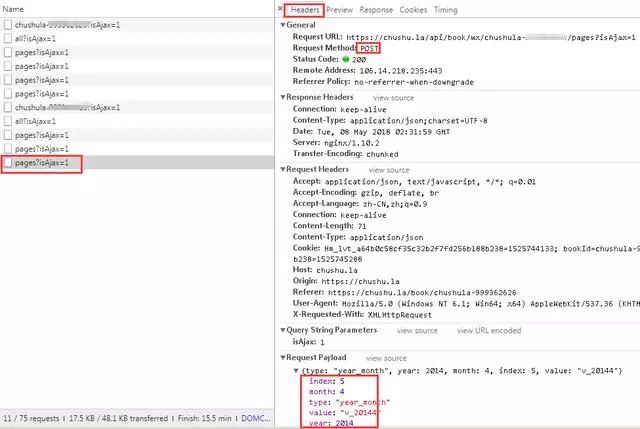
5、查看请求方式,可以看到此时的请求方式变成了POST。细心的伙伴可以看到在点击“下个月”或者其他导航月份的时候,主页的URL是始终没有变化的,说明该网页是动态加载的。之后对比多个网页请求,我们可以看到在“Request Payload”下边的数据包参数不断的发生变化,如下图所示。
6、展开服务器响应的数据,将数据放到JSON在线解析器里,如下图所示:
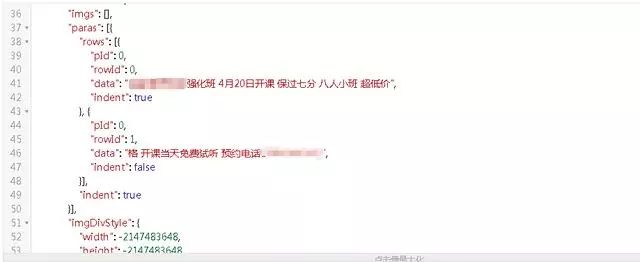
可以看到朋友圈的数据存储在paras /data节点下。
接下来将写程序,进行数据抓取。接着往下继续深入。
四、代码实现
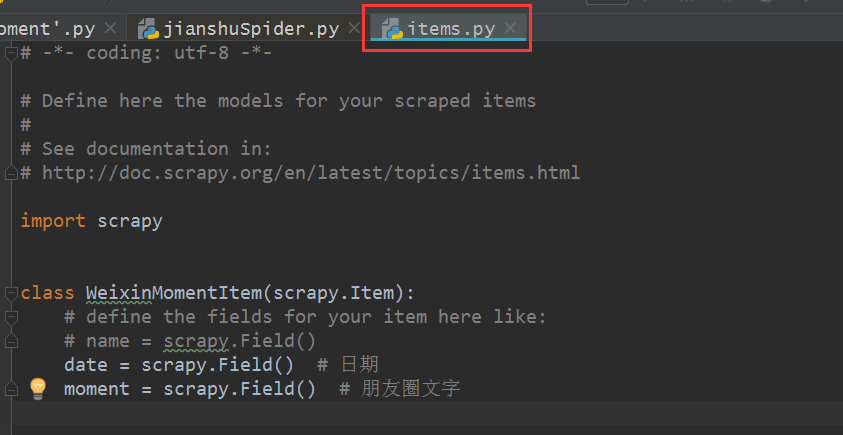
1、修改Scrapy项目中的items.py文件。我们需要获取的数据是朋友圈和发布日期,因此在这里定义好日期和动态两个属性,如下图所示。
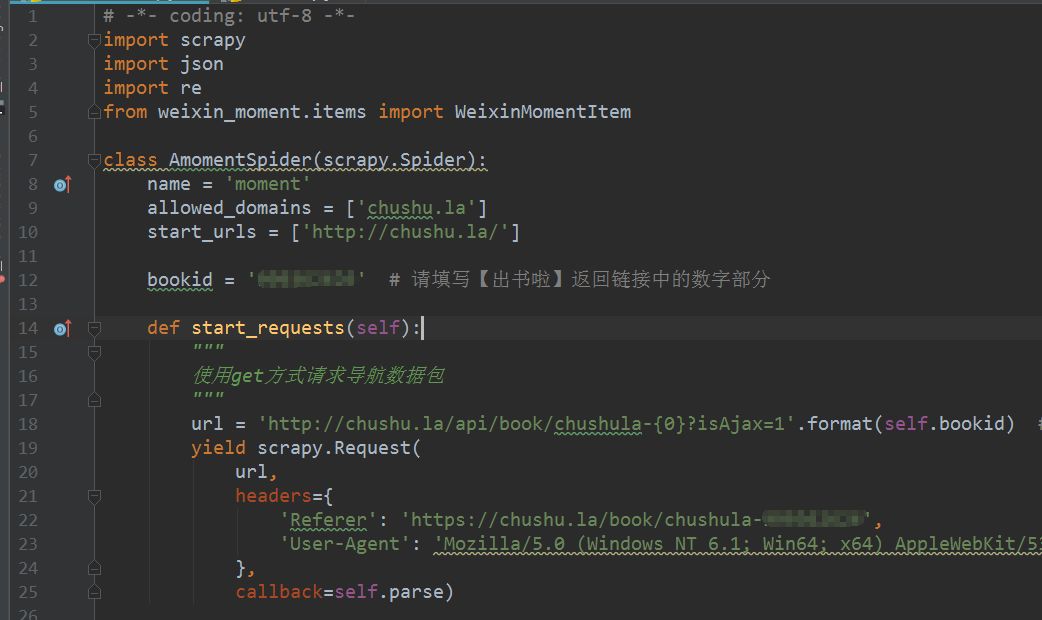
2、修改实现爬虫逻辑的主文件moment.py,首先要导入模块,尤其是要主要将items.py中的WeixinMomentItem类导入进来,这点要特别小心别被遗漏了。之后修改start_requests方法,具体的代码实现如下图。
3、修改parse方法,对导航数据包进行解析,代码实现稍微复杂一些,如下图所示。
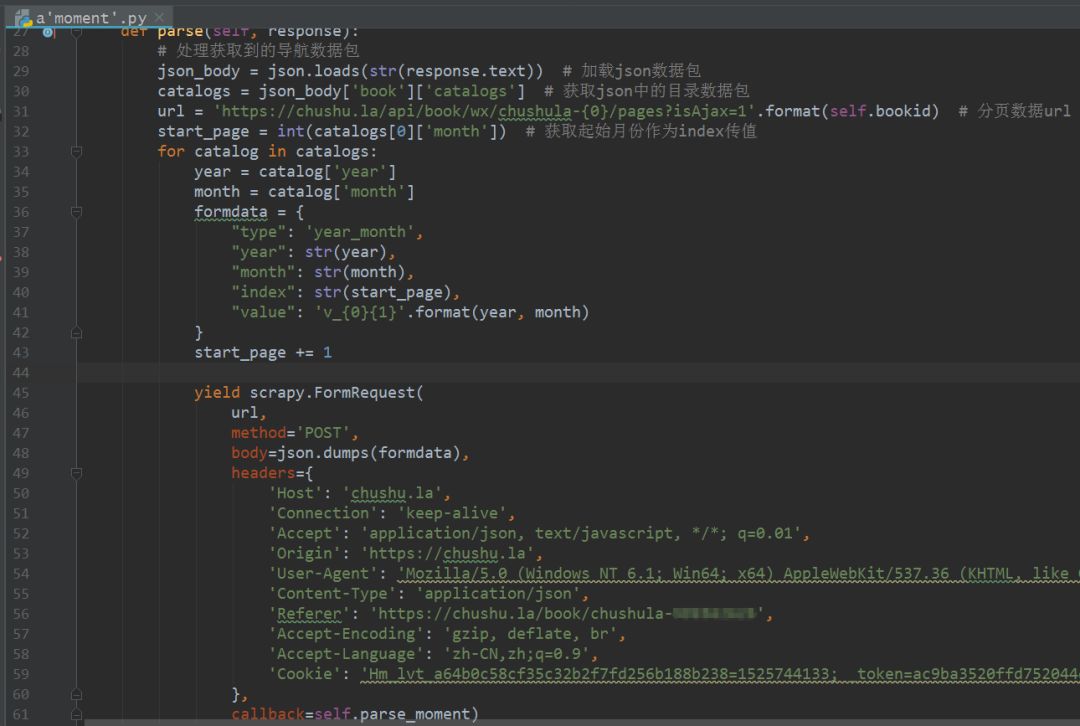
l需要注意的是从网页中获取的response是bytes类型,需要显示的转为str类型才可以进行解析,否则会报错。
l在POST请求的限定下,需要构造参数,需要特别注意的是参数中的年、月和索引都需要是字符串类型的,否则服务器会返回400状态码,表示请求参数错误,导致程序运行的时候报错。
l在请求参数还需要加入请求头,尤其是Referer(反盗链)务必要加上,否则在重定向的时候找不到网页入口,导致报错。
l上述的代码构造方式并不是唯一的写法,也可以是其他的。
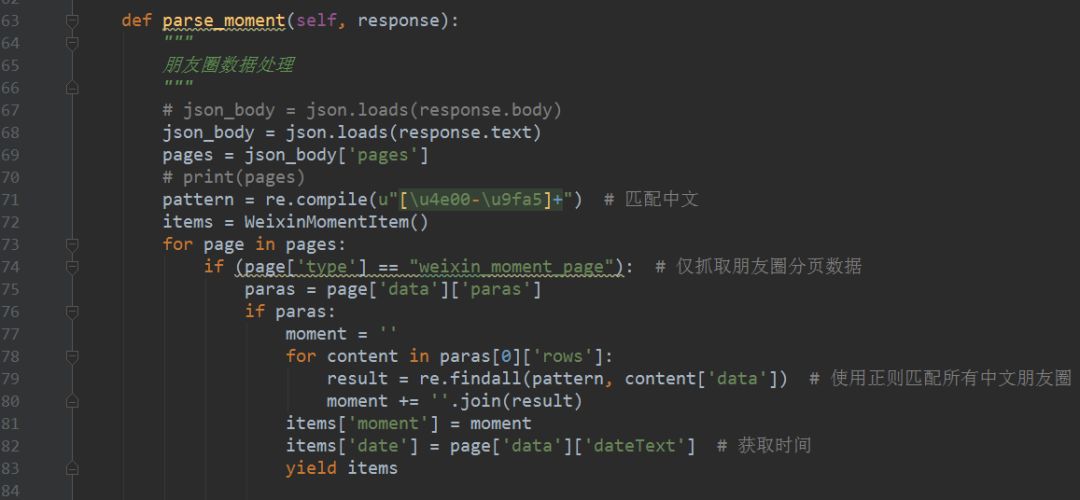
4、定义parse_moment函数,来抽取朋友圈数据,返回的数据以JSON加载的,用JSON去提取数据,具体的代码实现如下图所示。
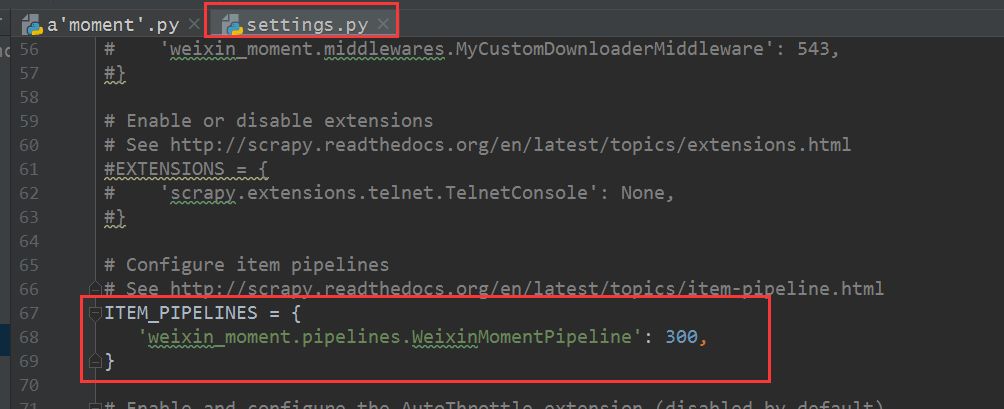
5、在setting.py文件中将ITEM_PIPELINES取消注释,表示数据通过该管道进行处理。
6、之后就可以在命令行中进行程序运行了,在命令行中输入
scrapy crawl moment -o moment.json
,之后可以得到朋友圈的数据,在控制台上输出的信息如下图所示。
7、尔后我们得到一个moment.json文件,里面存储的是我们朋友圈数据,如下图所示。
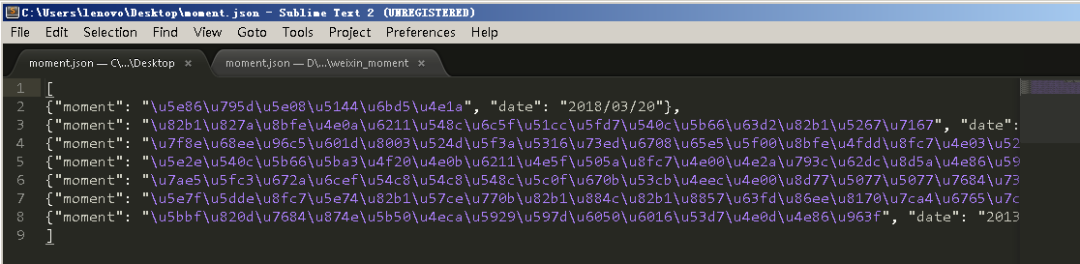
8、嗯,你确实没有看错,里边得到的数据确实让人看不懂,但是这个并不是乱码,而是编码的问题。解决这个问题的方式是将原来的moment.json文件删除,之后重新在命令行中输入下面的命令:
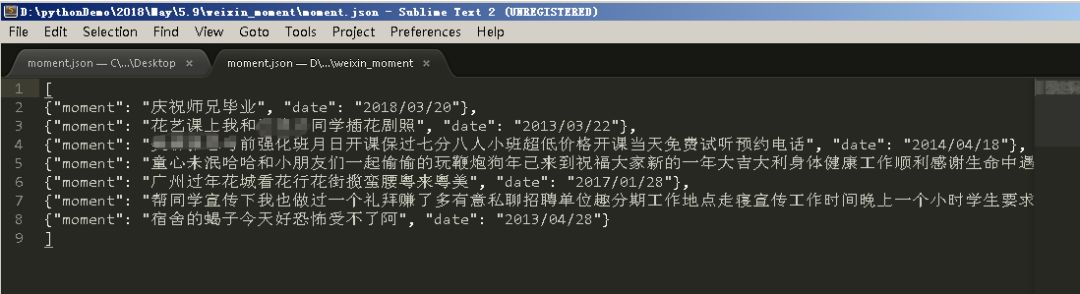
scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,
此时可以看到编码问题已经解决了,如下图所示。
-
利用Python编写简单网络爬虫实例2023-02-24 690
-
python网络爬虫概述2022-03-21 2465
-
怎么用RK3288 android去解决微信朋友圈视频不能播放的问题呢2022-02-18 2020
-
Python爬虫简介与软件配置2022-01-11 1430
-
汽车芯片有多缺货,广汽老总亲自发朋友圈找ST芯片2021-08-17 2356
-
用Python写网络爬虫2021-06-01 848
-
Python爬虫:使用哪种协议的代理IP最佳?2020-06-28 2314
-
微信朋友圈评论表情包功能已暂停2019-12-25 3295
-
新版微信将支持朋友圈评论使用表情包2019-12-23 2729
-
华为技术实力得到更多朋友圈的认可2019-05-31 1273
-
微信广告团队发布公告 朋友圈广告@好友评论互动能力全量开放2019-04-18 1365
-
无人机,AppleWatch和朋友圈竟然是哆啦A梦发明的!2017-03-10 2422
-
单身狗不哭,用段子霸占朋友圈!2017-02-14 6117
-
张小龙朋友圈致敬乔布斯,微信小程序给了安卓手机更多便利2017-01-09 1535
全部0条评论

快来发表一下你的评论吧 !
