

AI网络国产化破局未来可期
描述
近日,Hot Chips 2025大会聚焦高性能计算与网络技术的突破性进展,国际厂商密集发布新一代网络产品,折射出AI大模型浪潮下对算力&网络架构的迫切需求。在这场围绕高性能、高吞吐、低延时发展的性能竞赛中,AMD、NVIDIA都结合自身发展路线推出创新网络解决方案从而勾勒出AI原生网卡的主流技术路线趋势。
UEC Ready的关键功能成为主流
高性能网卡厂商的必选项
AMD作为UEC联盟的主要发起单位之一发布了AMD Pensando Pollara 400网卡,声称其是符合超以太网联盟(UEC)规范的AI NIC,全面支持UEC Ready RDMA。尽管NVIDIA并未声称其ConnectX-8 SuperNIC 参照UEC路线设计,但从网卡的性能及功能来看,两者均最终实现多路径传输、自适应路由、拥塞控制等维度的多项AI网络原生无损网络功能。
多路径传输
NVIDIA 在其AI Networking白皮书中曾重点提及传统数据中心的应用程序会产生大量的小数据流,这使得网络流量的统计平均值能够反映整体情况。在这种背景下,基于简单静态哈希的路由算法,如等价多路径(ECMP,Equal Cost Multi-Path),足以应对常见的网络流量问题。然而,人工智能工作负载的特性却截然不同。它们通常会产生少量的大数据流,被称为“大象流”(elephant flows)。这些大象流会占用大量的链路带宽,如果多个大象流被路由到同一链路,就会导致严重的拥塞和高延迟。
因此,在设计AI NIC过程中率先提出引入自适应路由算法并运用数据包喷洒技术实现AI网络的多路径传输功能。
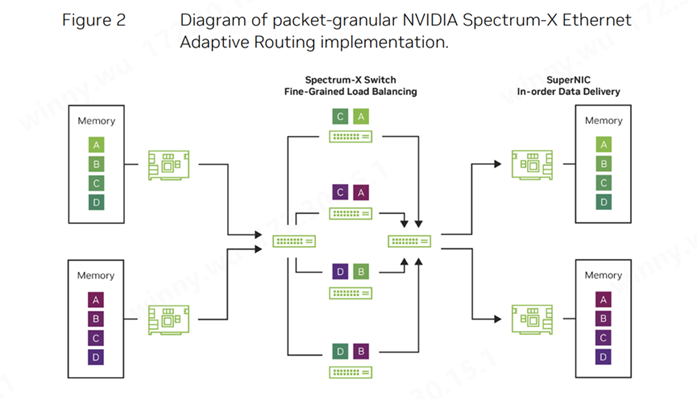
(来源: 英伟达 AI Networking白皮书)
AMD 在Hotchips 2025大会上同样提及有损RDMA的ECMP Hash冲突痛点并参照UEC 1.0规范通过数据包喷洒实现多路径传输。与此同时,AMD网卡标记UDP端口号/UEC路径熵值以控制路径选择并根据ECN和修剪数据包反馈跟踪路径状态。
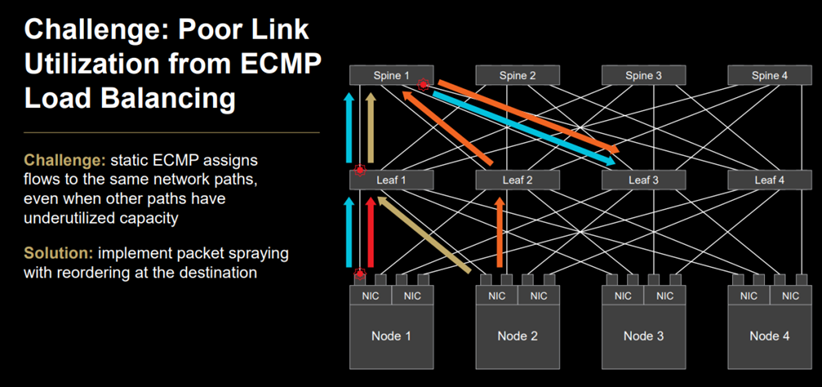
(图: AMD解释ECMP Hash冲突挑战)
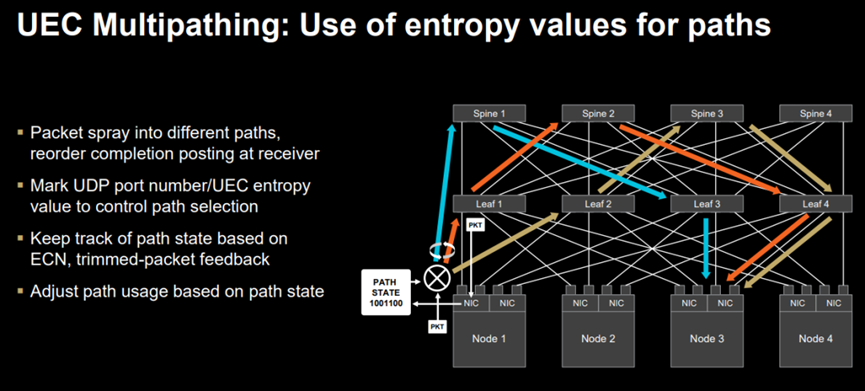
(图:AMD 使用包喷洒技术实现多路径传输)
尽管英伟达和AMD在实现流量控制过程中采用的技术存在一些差异,但最终也以数据包喷洒技术实现多路径传输为网络控制目的。多路径的存在使得具备该性能的网卡能够提供极快的丢包替换和超快的流量控制,即使在应用程序调度不佳或网络链路偶尔出现波动的情况下,也能确保流畅的流量传输。
拥塞控制
AI和HPC应用经常采用集合通信在多个节点之间同步信息,当多个发送方同时向单个接收方发送数据流,并且任何一个发送方都将发送完当前所有的数据流后,才开始发送后续的数据流。由于同时发送过多的数据流,会造成接收方的交换机缓冲区过载,使得接收方无法正常接收数据,即会产生Incast现象,而这种网络拥塞现象将大大影响并增加尾延迟。
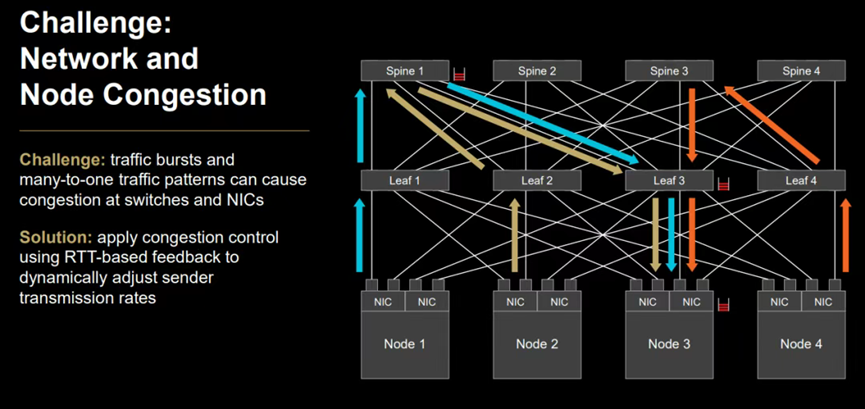
(图:AMD 解释拥塞控制)
AMD AI 网卡采用基于UEC标准的UEC-CC拥塞控制技术从而解决拥塞控制问题。据UEC 1.0标准,UEC-CC 采用基于时间的机制,具备亚500纳秒精度的传输时延测量能力,独立测量数据包的前向路径和反向路径,这意味着网卡之间需要进行绝对时间同步。双向测量可以准确地将拥塞归因于发送方和接收方。如果启用了 UEC-CC,交换机需要支持 ECN(显式拥塞通知),并且预计将使用现代 ECN 变体:在每个流量类别上单独设置拥塞标志,并在数据包传输前立即进行测量。这种设置提供了最新的拥塞信息,并针对每个流量类别进行差异化处理,从而达到优化拥塞控制功能。
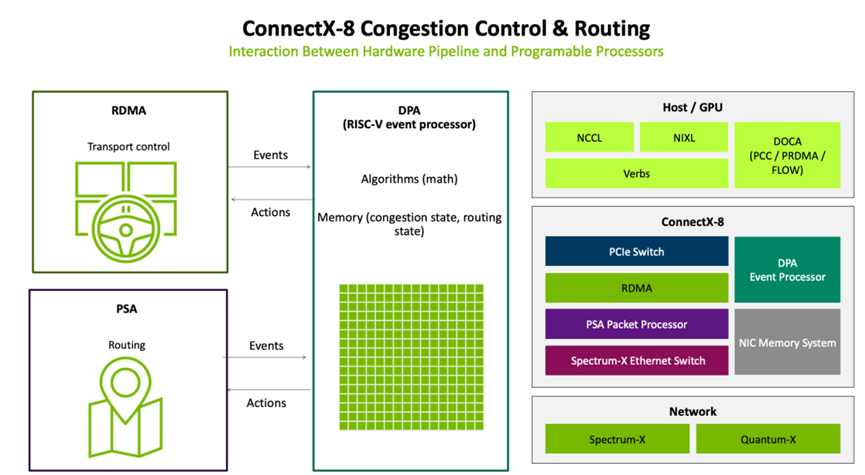
英伟达的CX-8 SuperNIC 则使用RISC-V DPA processor来实现拥塞控制功能。在Transport层的Event和路由层的Event都会由DPA处理。在本次Hotchips 2025的演讲中,其并未披露其DPA的细节,但大概率集成了类似UEC的拥塞控制功能。
选择性重传
在传统传输协议,如TCP需要严格的传输顺序,会采用了Go-Back-N机制。而一个RDMA消息通常包含多个数据包,只要有一个数据包错误,就必须从这个数据包起的所有数据包都要重传。在 AI 工作负载中,大量的GPU或者Accelerator间通信是“集合”通信操作的一部分,其中 All-Reduce 和 All-to-All 是主要的集合通信类型。这类通信快速完成的关键是从 A 到 B 的快速批量传输,AI 应用程序关心给定消息的最后部分何时到达目的地。所以对AI网络而言,这让原有的丢包和其处理机制将传输错误放大,大量的重传加剧了网络拥塞,降低AI网络传输效率。
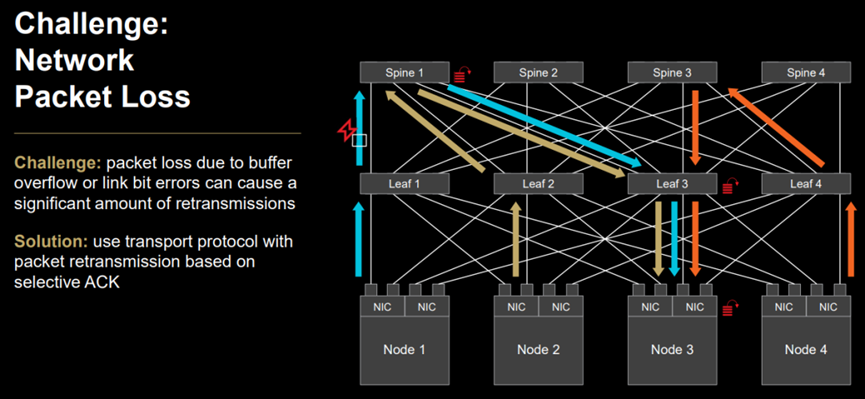
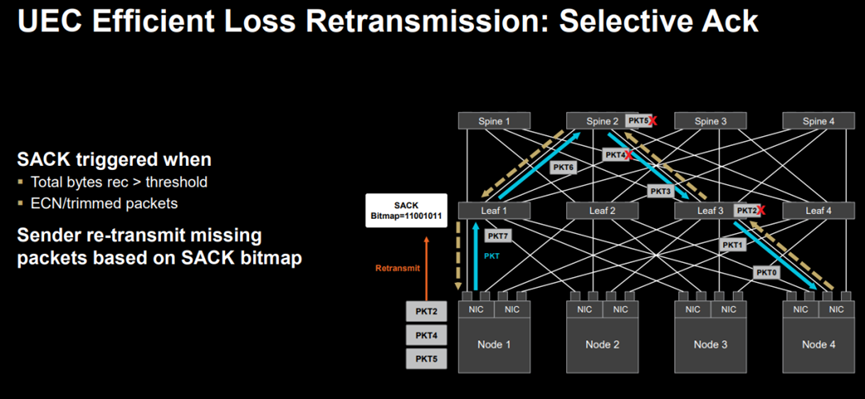
(图: AMD 描述网络丢包及其选择性重传解决方案)
AMD AI NIC 落实了UEC中的选择性重传机制,高性能的RDMA会判断出整个消息中哪个报文被网络丢弃,基于UEC RDMA的网卡通知发送端重传这个报文,而非将所有传输包都需重传。这种选择性重传机制大大改善了AI网络的传输效率,提升AI 大模型训推效能。
上述一系列的高性能RDMA功能是面向AI大规模原生网络Scale Out的关键解决方案,也成为下一代主流AI网卡的必备功能。奇异摩尔的Kiwi SNIC 满足上述面向 AI 原生的 Adv. RDMA 功能,不限于多路径传输、选择性重传、高性能拥塞控制管理技术等。
高性能网卡的额外特性
Nvidia ConnectX-8 SuperNIC
集成PCIe Switch功能
这一代ConnectX-8 超级网卡从ConnectX-7的400G跃升至800G,并集成了PCIe Switch,与Spectrum-X Switch、NVLink协同工作。硬件性能方面,CX-8 的800 Gb/s的RDMA硬件管线和其通过内置的PCIe Gen6 Switch芯片,可支持多达48条PCIe Gen6通道,解决了多设备互联的带宽瓶颈问题。
AMD 网卡引入P4可编程架构
实现网络功能定制化
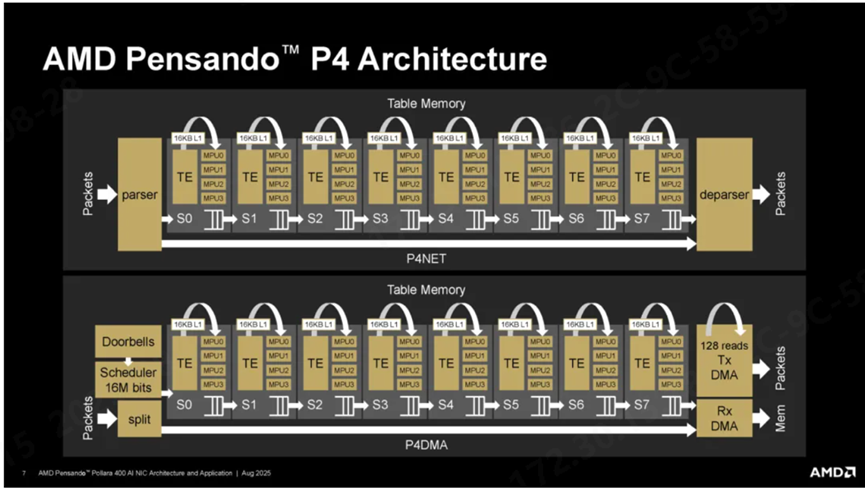
(来源: AMD)
AMD网卡的P4可编程架构中,表引擎(TE)和匹配处理单元(MPU)为核心组件,提供了灵活的字段操作指令和高效的数据包处理能力。官方数据显示,在RoCEv2测试中,相较于4Q pairs和1Q pair的性能分别提升了25%和40%。
我们知道ASIC架构的网卡相较于FPGA在性能及性价比上都更适合超大规模网络的互联,但是在面向应用快速发展的情况下,灵活性有所不足。基于可编程架构的 ASIC,打破了固有架构ASIC灵活性不足的局限。通过植入可编程引擎可以灵活应对AI算法、系统对于网络持续演进的需求,重构 ASIC芯片可编程可定制的技术范式。
奇异摩尔Kiwi SNIC 超级网卡同样基于可编程ASIC架构,内置HPDE高性能可编程数据DSA。HPDE基于可定义可扩展的网络加速指令集,通过重编译来灵活支持新的协议标准和加速算法,这种高性能可编程数据处理引擎不仅支持先进拥塞控制算法,实现可编程包头识别及处理、链接跟踪功能并具有很强的灵活性来应对软硬件升级。
国产化AI网络自主自控未来可期
在2025中国算力大会上,工业和信息化部明确表示将有序引导算力设施建设,深入开展算力强基"揭榜"行动,聚焦计算、存储、网络等重点方向。这一战略部署将加速国产AI网络芯片、操作系统等核心技术的研发突破,减少对外部技术的依赖。这一政策导向为国产化AI网络产品的自主自控发展奠定了坚实基础
奇异摩尔作为AI网络互联全栈式互联产品提供商也在积极探索AI网络芯片的多元化的集成技术路径。展望未来,随着Scale out和Scale up网络的进一步融合,奇异摩尔的NDSA统一架构平台将积极发挥其网络+计算的双优优势,从而进一步实现网卡功能集成IO Die芯粒 /集成Switch等多种创新技术路径,构建更高性能、更高效能、更灵活的网络基础设施,以满足国产AI的飞速发展需求。
关于我们
AI网络全栈式互联架构产品及解决方案提供商
奇异摩尔,成立于2021年初,是一家行业领先的AI网络全栈式互联产品及解决方案提供商。公司依托于先进的高性能RDMA 和Chiplet技术,创新性地构建了统一互联架构——Kiwi Fabric,专为超大规模AI计算平台量身打造,以满足其对高性能互联的严苛需求。我们的产品线丰富而全面,涵盖了面向不同层次互联需求的关键产品,如面向北向Scale-out网络的AI原生超级网卡、面向南向Scale-up网络的GPU片间互联芯粒、以及面向芯片内算力扩展的2.5D/3D IO Die和UCIe Die2Die IP等。这些产品共同构成了全链路互联解决方案,为AI计算提供了坚实的支撑。
-
Neway微波产品的国产化替代方案2025-12-18 861
-
PCB抄板如何炼制进口备件国产化改型升级2014-04-28 3154
-
部分芯片国产化---求路人指路2015-01-04 4519
-
压力传感器的国产化关键是什么?2019-10-08 2751
-
如何选择国产化替代FPGA产品?2021-03-02 4728
-
【全国产化系列】Firefly推出多款全国产化核心板2021-06-15 3166
-
max1978国产化2022-06-27 3929
-
全国产化全志A40i核心板,照亮电力设备国产化之路2022-09-16 51418
-
请查收“国产化率认证报告”(100%)——RK3568J工业核心板2023-06-15 6354
-
光刻胶国产化项目落地咸阳,未来可期!2018-07-19 8009
-
网络安全实现全面国产化任重道远2019-12-25 5395
-
芯片制造的国产化任重道远2023-08-09 5182
-
全球硅片景气上行,国产厂商加速破局.zip2023-01-13 420
-
破局!连接器国产化替代加速逆袭2025-04-10 1021
-
全国产化!这款AI智能模组很硬核2025-06-16 1221
全部0条评论

快来发表一下你的评论吧 !
