

AMD 7nm Versal系列器件NoC的使用及注意事项
描述
AMD 7nm Versal系列器件引入了可编程片上网络(NoC, Network on Chip),这是一个硬化的、高带宽、低延迟互连结构,旨在实现可编程逻辑(PL)、处理系统(PS)、AI引擎(AIE)、DDR控制器(DDRMC)、CPM(PCIe/CXL)等模块之间的高效数据交换。
NoC的出现,替代了传统PL内部布线实现复杂总线互连的方式,通过专用硬化通道提升吞吐量、降低延迟、减少逻辑资源占用,并且能实现跨Die(SSIT封装)的高速通信。
NoC架构与特性
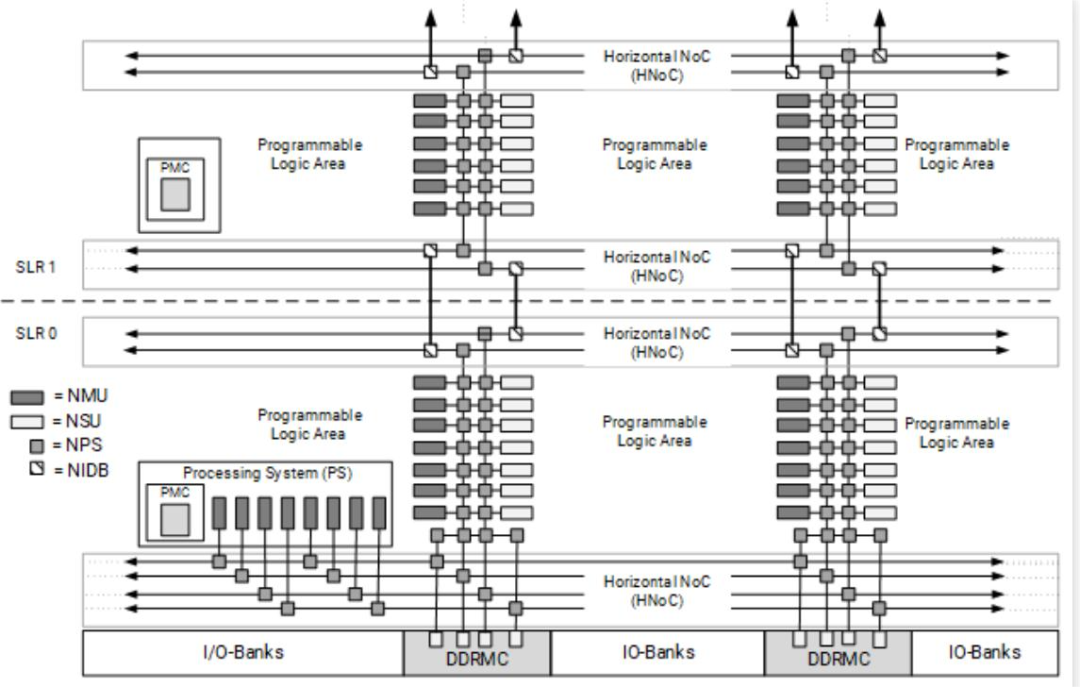
NoC包含以下主要组件:
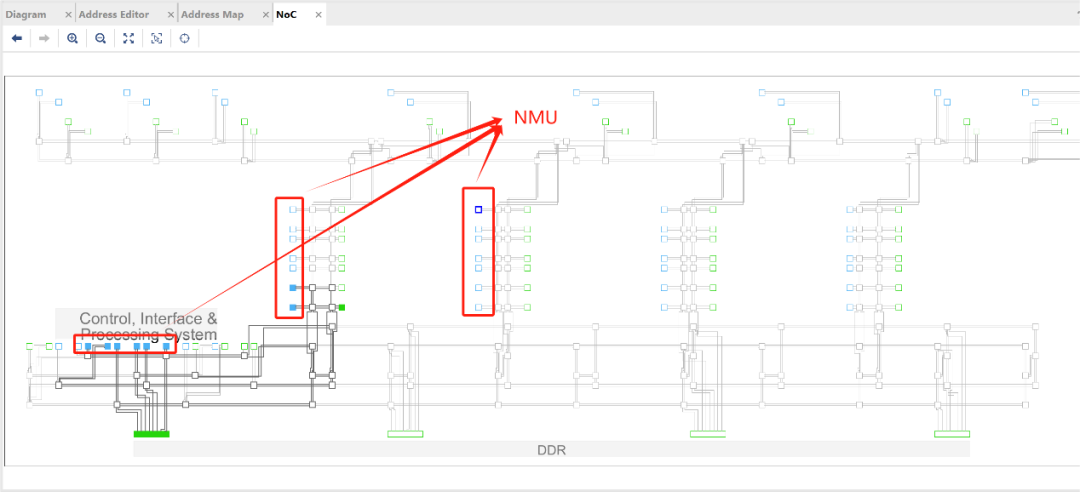
NMU(NoC Master Unit):将AXI请求转换为NoC数据包(NPP),支持时钟域转换与速率匹配;
NSU(NoC Slave Unit):接收并解析NoC数据包(NPP),转换为AXI协议;
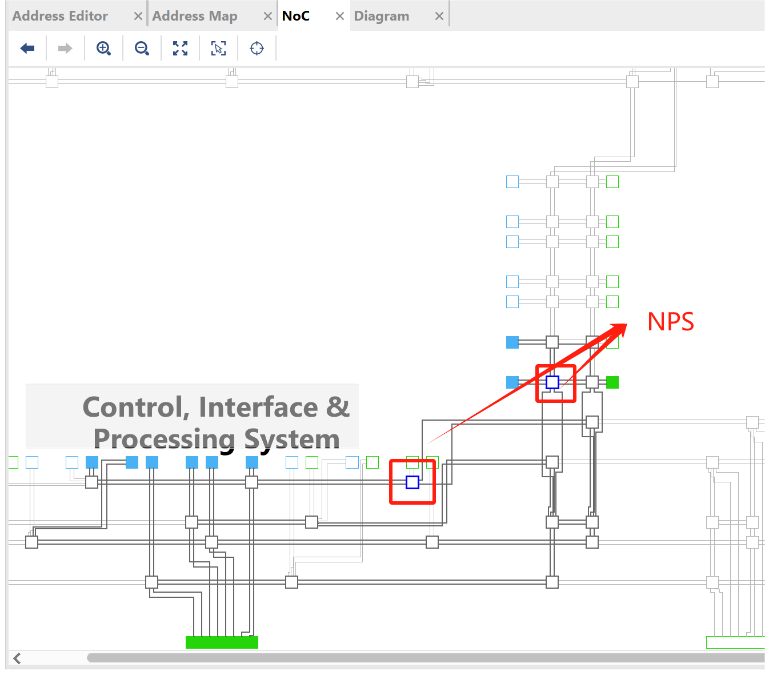
NPS(NoC Packet Switch):全双工交换机,连接多个NoC节点;
NIDB(NoC Inter-Die Bridge):跨Die的垂直NoC桥接模块。
核心特性
水平(HNoC)与垂直(VNoC)通道:减少PL内布线压力,提高拓展能力;
AXI接口灵活配置:支持32位~512位AXI Mem位宽,以及128位~512位AXI4-Stream;
自动交错访问:跨多个DDR控制器分配请求,提升带宽利用率;
QoS(服务质量):提供基于延迟/带宽的优先级控制;
跨Die通信:多Die设计中提供高效数据通道;
硬化路径固定延迟:相比可编程互连,延迟更可预测,利于实时应用。
此文结合Vivado工程,快速熟悉NoC的使用
Vivado中的NoC使用步骤:
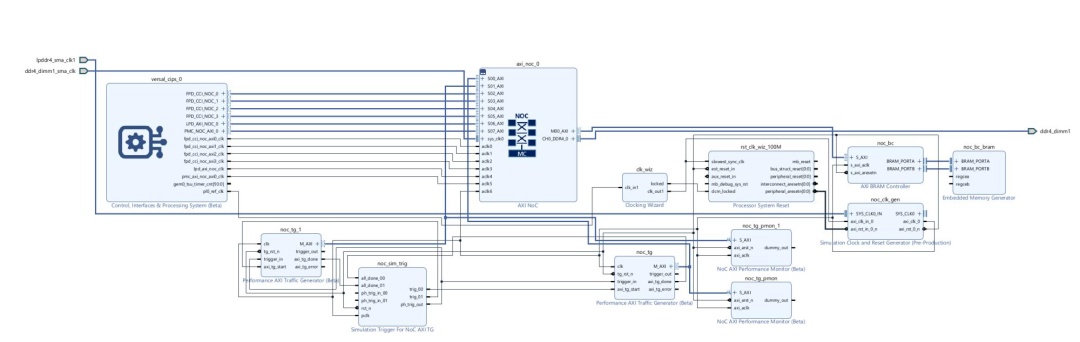
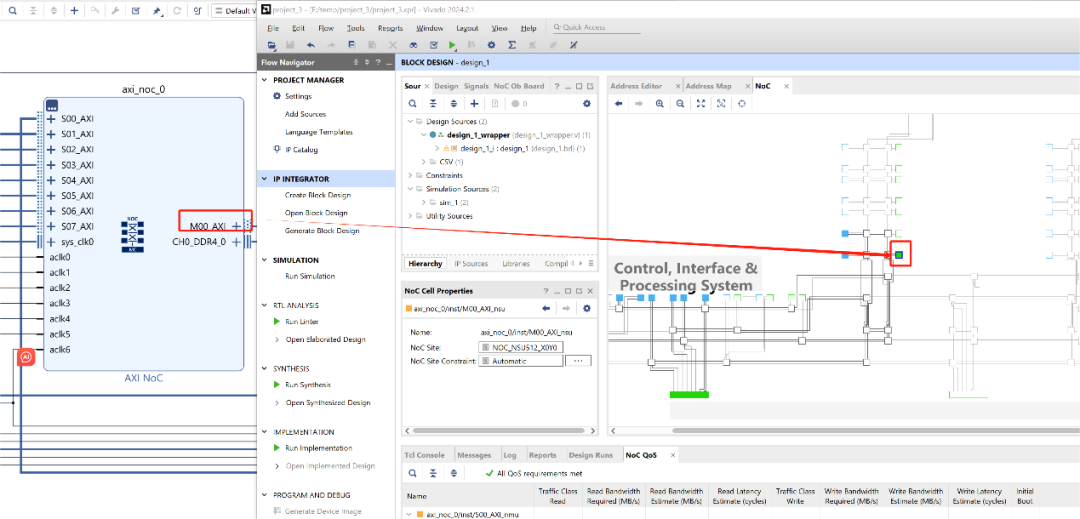
新建工程 & BD→添加Versal NoC IP
配置AXI\_Slave(NMU)与AXI\_Master(NSU)
连接DDR控制器、CPM、AI Engine等模块
在NoC Compiler中查看拓扑,配置QoS、带宽、路由路径
必要时在XDC中固定NMU/NSU位置以减少路径延迟
分析带宽与延迟,迭代优化
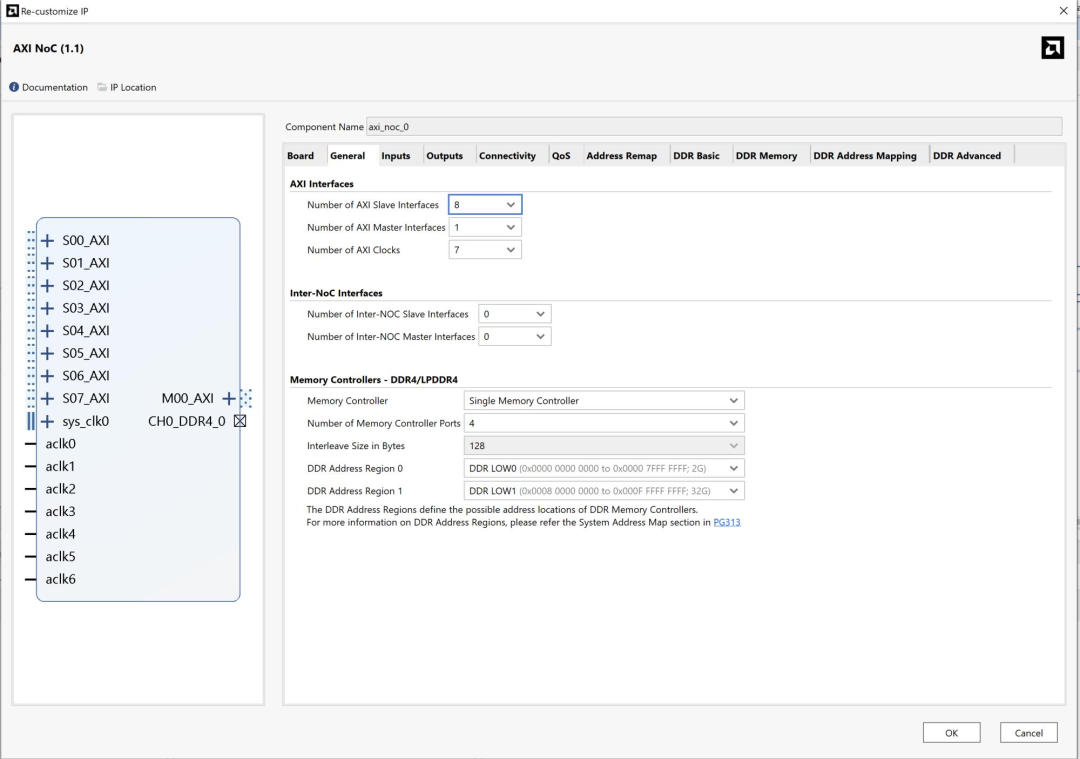
可以看到界面中有AXI_Slave与AXI_Master两种接口,分别对应NMU与NSU。
NoC内部的组件
1、NoC Master Unit (NMU)
NMU的作用是将AXI协议转换为NoC数据包协议(NPP),同时,NMU还支持AXI端口和NoC之间的异步时钟域转换与速率匹配。
下图为Vivado工程中NMU的示例:
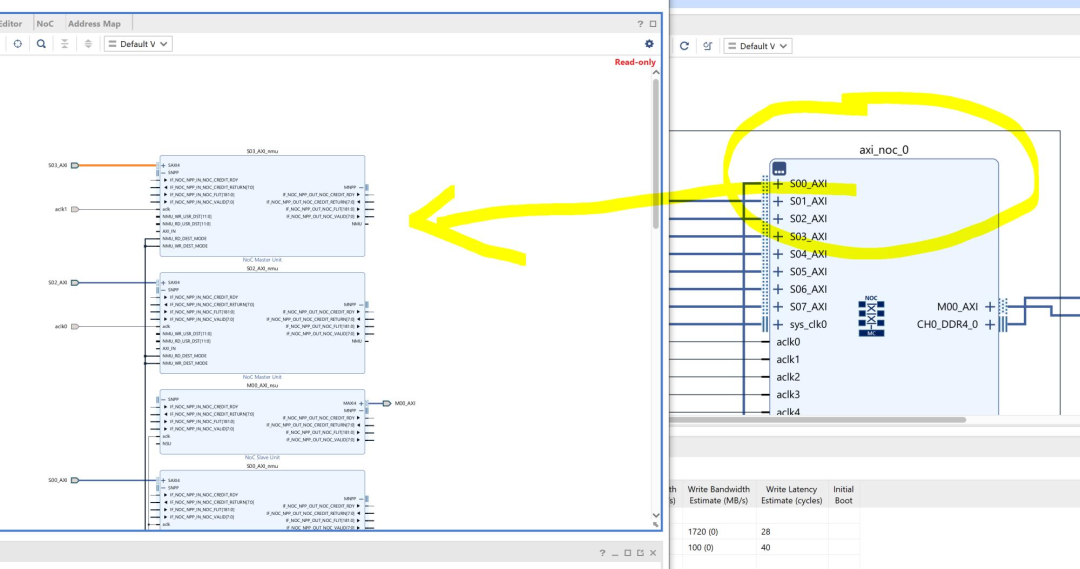
NMU内部结构:
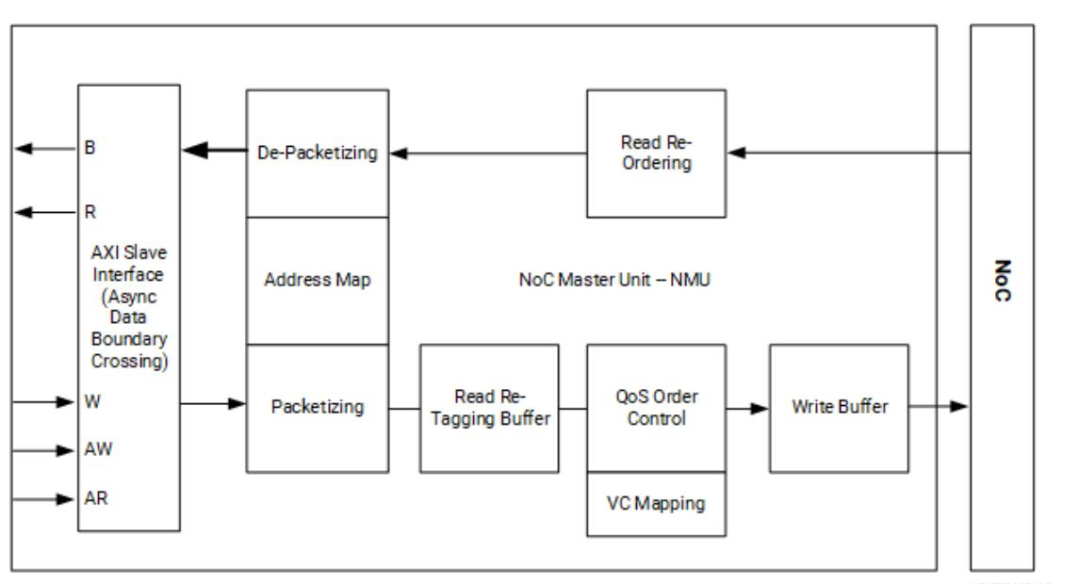
当AXI请求进入NMU时钟域时,将执行数据分组,读写事务被分解为更小的传输(此过程称为chopping)。
NPP写入的最大大小为256字节。超过256字节的AXI写入可以跨越多个NPP写入。De-Packetizing&Packetizing会将粒度大于或等于256字节的事务切分为256字节的传输。例如,一个从0x0开始的1K传输事务将分为4 packet进行传输:0-255、256-511、512-767、768-1023。
Re-tagging模块在读取时重新标记以允许无序传输并防止互连阻塞。
在对外的AXI接口上支持配置32位~512位,在AXI4-Stream上支持从128位~512位的可配置数据宽度接口。AXI数据宽度通过参数传播从连接的IP,无需手动指定位宽。
2、NoC Slave Unit (NSU)
NSU的主要功能是接收和响应来自NoC的数据包,这些数据包寻址到NSU数据包接口,旨在发送到对应的AXI端口。
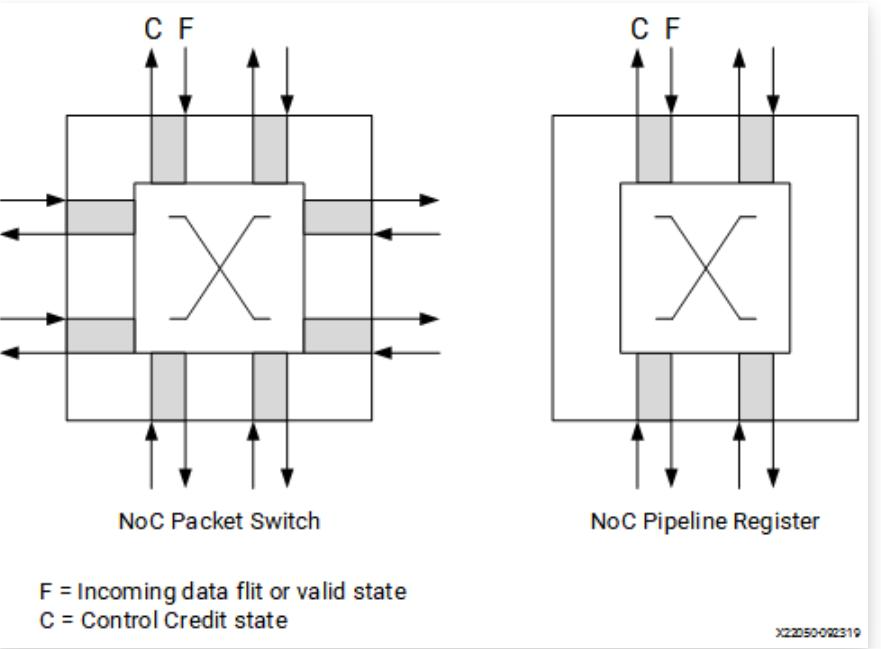
3、NoC Packet Switch (NPS)
连接NoC块以形成完整NoC网络交换。每个NPS都是全双工4x4 Switch,通过Switch至少有两个延迟周期。
NSU512(PL) NSU512(PL)
4、NoC Inter-Die Bridge (NIDB)
在多个SSIT芯片之间桥接垂直NoC(VNoC)。
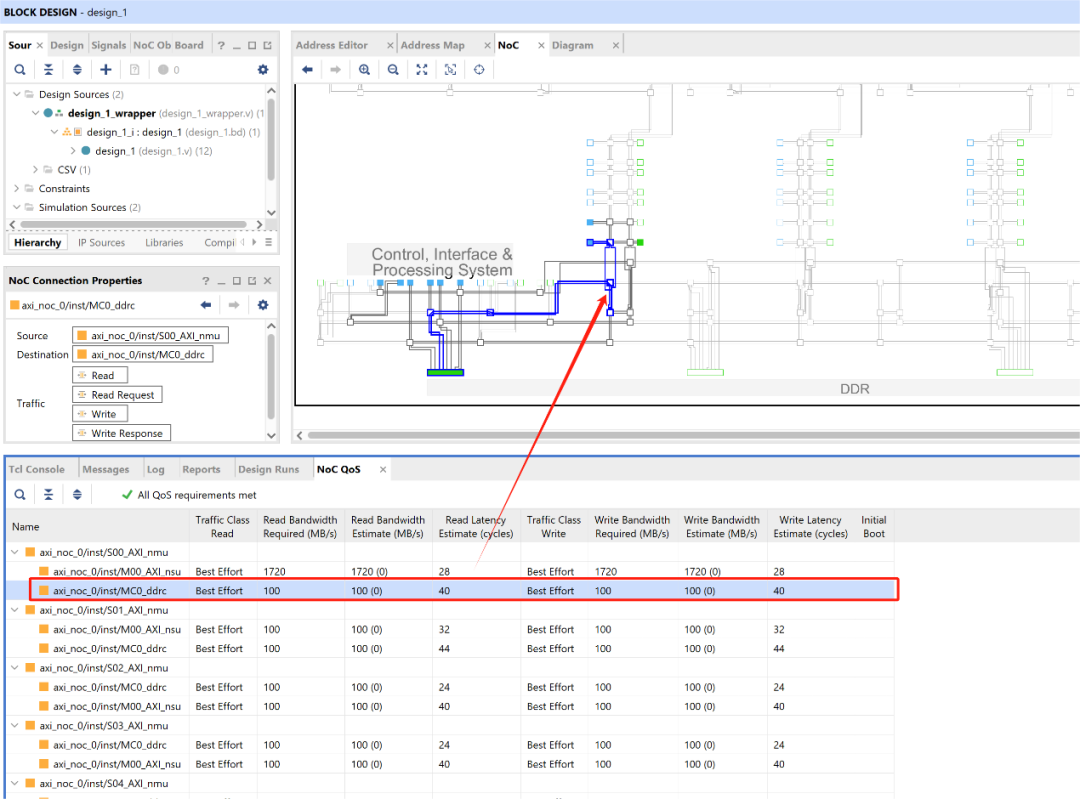
Quality of Service(QoS)
Traffic Class与Read and Write Bandwidth
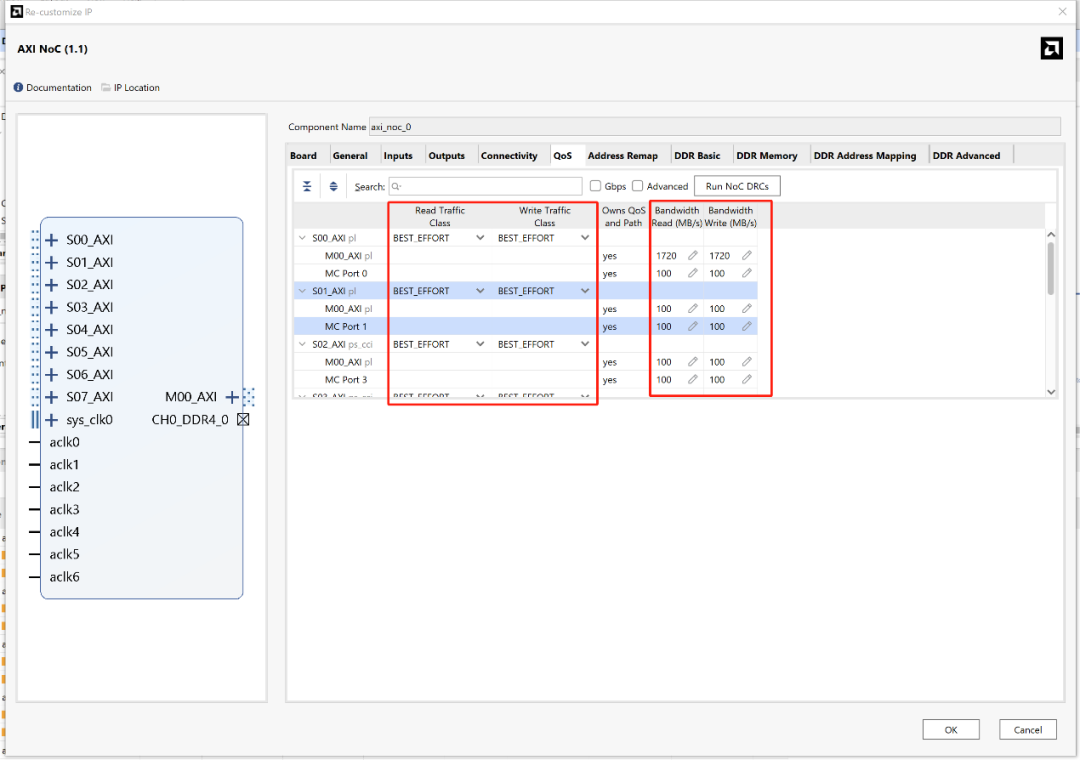
1、流量类别(Traffic Class)
定义了连接上的流量在NoC编译器和硬件中的优先级。流量类在NMU上设置,适用于从该NMU开始的所有路径。Traffic Class支持如下3种模式:
Low Latency:尽量减少结构延迟,DDR仲裁中优先级最高;
Isochronous:保证最大延迟;DDR队列中设定超时提前处理;
Best Effort:最低优先级,适合非关键流量。
2、带宽需求(Bandwidth Requirement)
单独设置读/写带宽(单位MB/s或Gb/s);
Vivado NoC Compiler会基于此进行资源分配与仲裁优化。
性能优化建议
关键流量优先保障:通过QoS将低延迟或同步流量优先级调高;
减少跨交换机跳数:布局时尽量缩短NMU→NSU的路径;
合理位宽分配:带宽与功耗需权衡,避免过度配置浪费资源;
多Die优化:跨Die数据尽量走专用VNoC通道,减少延迟;
路径可视化:在NoC Compiler拓扑图中检查关键路径是否经过不必要的节点。
在Vivado BD的NoC界面,可以看到DDRNMUNSUNPSQoS等。
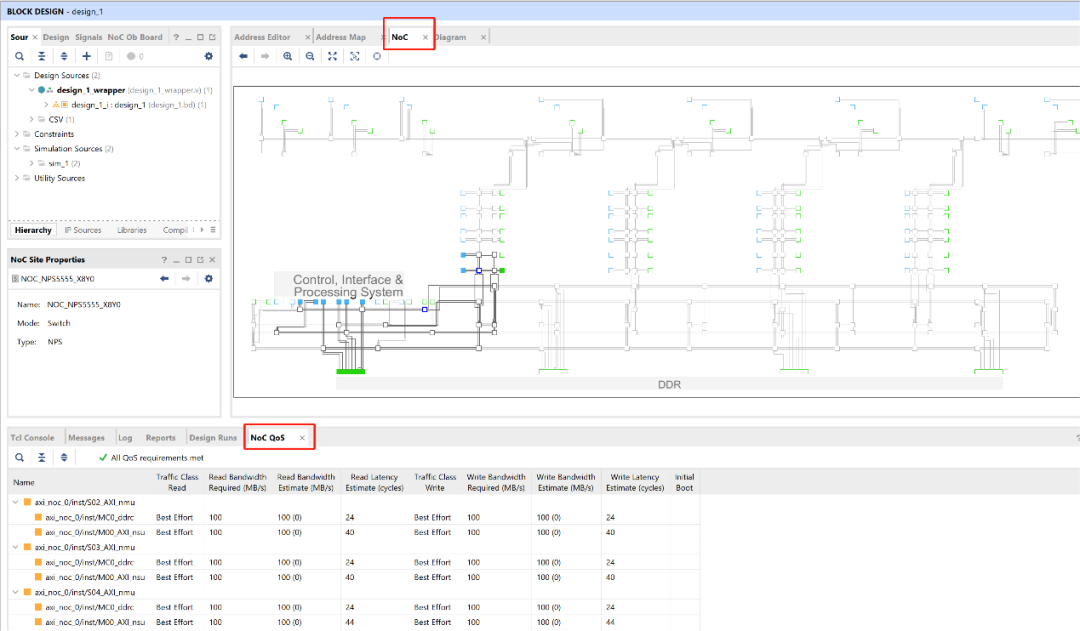
点击如下QoS选择卡中的条目,可以看到此路径下的NoC拓扑。
关于安富利
安富利是全球领先的技术分销商和解决方案提供商,在过去一个多世纪里一直秉持初心,致力于满足客户不断变化的需求。通过遍布全球的专业化和区域化业务覆盖,安富利可在产品生命周期的每个阶段为客户和供应商提供支持。安富利能够帮助各种类型的公司适应不断变化的市场环境,在产品开发过程中加快设计和供应速度。安富利在整个技术价值链中处于中心位置,这种独特的地位和视角让其成为了值得信赖的合作伙伴,能够帮助客户解决复杂的设计和供应链难题,从而更快地实现营收。
-
基于AMD Versal器件实现PCIe5 DMA功能2025-06-19 2298
-
AMD 7nm芯片的封测厂商通富微电介绍2020-12-30 4645
-
随着AMD 7nm制程芯片的加速落地,AMD将爆发更强悍的性能2018-06-14 1222
-
AMD:7nm明年有望出现2018-07-06 1111
-
AMD公开VEGA GPU架构使用7nm工艺2018-06-29 5379
-
AMD 7nm处理器和Intel 7nm处理器有什么区别?2018-07-23 20662
-
Q3季度AMD芯片均价大涨40% 7nm正在给AMD带来丰厚回报2019-11-01 848
-
AMD或使用三星7nm制程来制造RX 5500系列显卡2019-12-18 3383
-
AMD Radeon Pro W5700系列专业卡开售,核心基于7nm Navi 102019-12-25 3998
-
超越苹果和海思,AMD在台积电7nm产能占比第一2020-01-03 4239
-
AMD 7nm U/H系列处理器支持面容和指纹登陆2020-01-07 3868
-
AMD推出锐龙4000系列APU处理器 7nm锐龙APU尤其重要2020-01-09 7784
-
AMD加速甩掉14nm工艺,IO核心有望使用台积电7nm工艺2020-09-24 2692
-
消息称AMD明年成7nm最大客户:暴增80%2020-12-21 2332
-
AMD Versal自适应SoC器件Advanced Flow概览(下)2025-01-23 2068
全部0条评论

快来发表一下你的评论吧 !
