

传统图像与视频压缩技术
电子说
描述
2018年6月14日,图鸭与论智联合举办了一场线上公开课深度学习之视频图像压缩。讲师为周雷博士,图鸭科技深度学习算法研究员。以下为论智整理的听课笔记。因水平有限,难免有错漏不当之处,仅供参考。
传统图像与视频压缩技术
首先,我们简单回顾下传统图像与视频压缩技术。
JPEG
以下为JPEG编解码流程示意图。
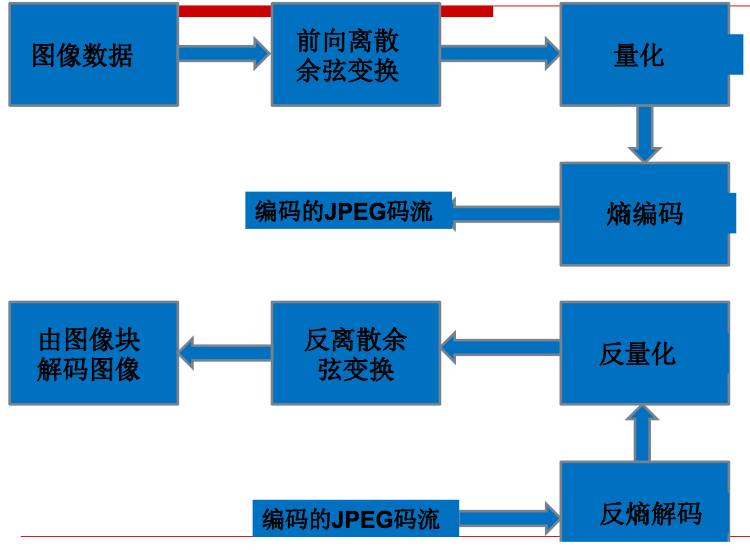
从上图我们可以看到,图像数据编码过程如下:
离散余弦变换。简单来说,离散余弦变换是一种矩阵运算。
经过离散余弦变换后,高频数据和低频数据分流了,矩阵左上方是高频数据(较大的数值),右下方是低频数据(较小的数值)。这样我们就可以对其进行量化了,在JPEG中是除以量化步长再取整。
量化之后对其进行熵编码,得到压缩表示。
解码的过程与编码过程相逆,经过反熵编码、反量化、反离散余弦变换重建图像。
JPEG2000
JPEG2000和JPEG的最大差别是使用了离散小波变换。此外还加上了一些预处理步骤。
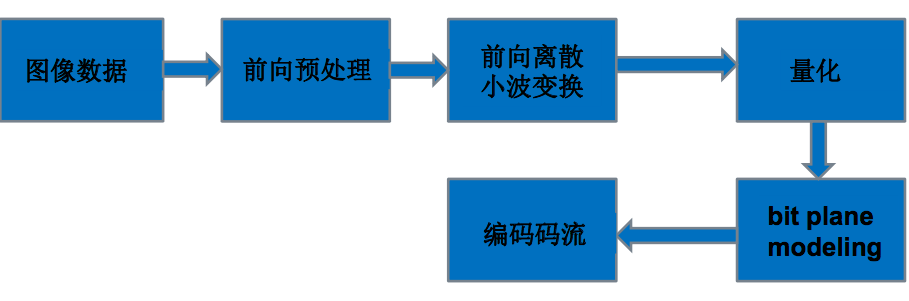
JPEG2000编码流程示意图
WebP
WebP是来源于VP8的图片压缩格式。主要特色是基于块预测。
BPG
和WebP类似,BPG同样源于视频编码技术(HEVC)。BGP的主要特点如下:
HEVC
HEVC的编码示意图如下:
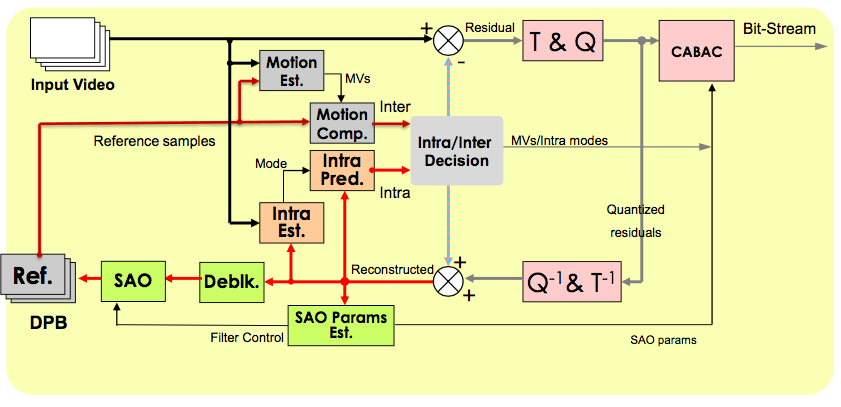
上图中,Ref.表示参考样本。T & Q表示转换、量化过程,Q-1 & T-1为其逆过程。Deblk.为Deblocking(去区块)的缩写。HEVC会将影像分为区块再进行编码,因此重建时会在区块边缘出现不连续的现象,称为区块效应。去区块过程可以减轻区块效应。SAO为Sample Adaptive Offset(样本自适应偏移量)的缩写,通过分析去区块后的数据与原始数据的差异,补偿量化过程造成的损失,使其尽可能接近原始数据。
CABAC为自适应二进制算术编码。算术编码利用符号出现的概率将符号序列编码为一个数字。
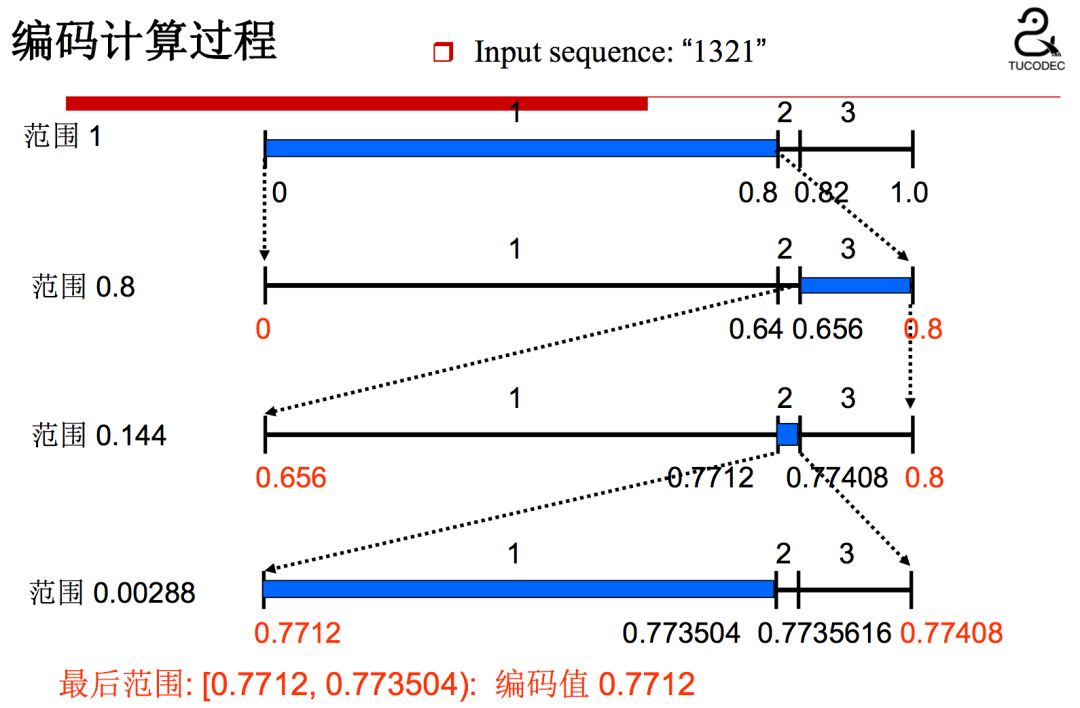
相应的解码过程:
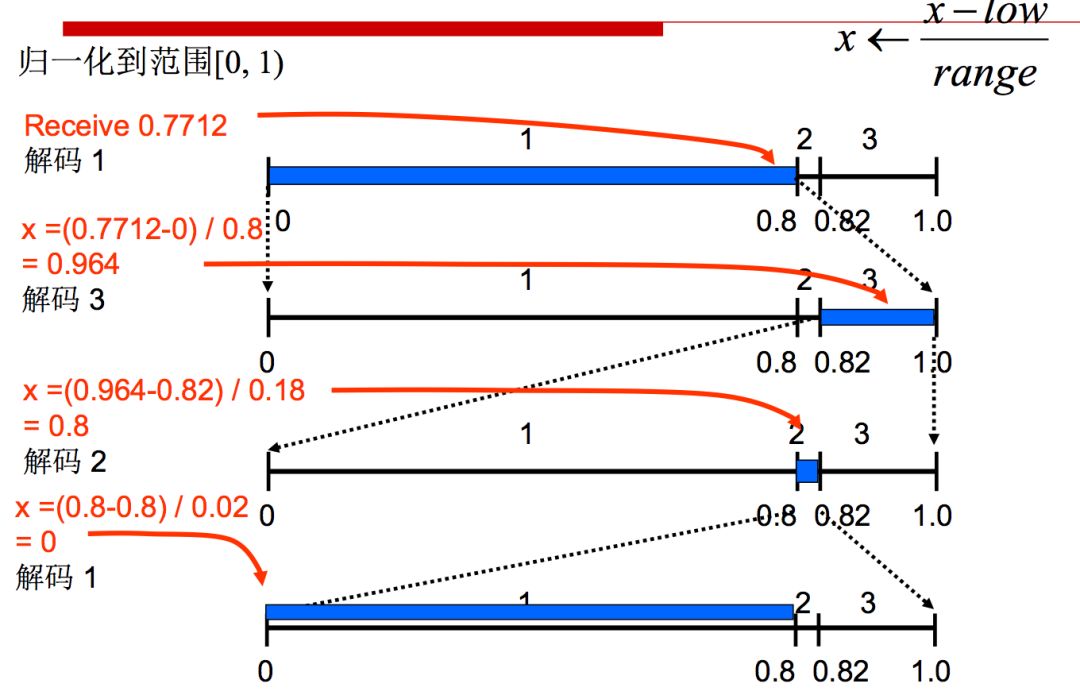
从以上的编解码过程中,我们可以看到,先验概率估计的精确程度对编码的效率影响很大。HEVC使用动态更新的概率模型实现自适应二进制算术编码。
除了帧内估计、预测(参见前面提到的BPG)之外,HEVC视频编码还需考虑运动估计等帧间的关系。
深度学习图像视频压缩框架
深度学习图像压缩框架
下为深度学习图片压缩的典型框架示意图:
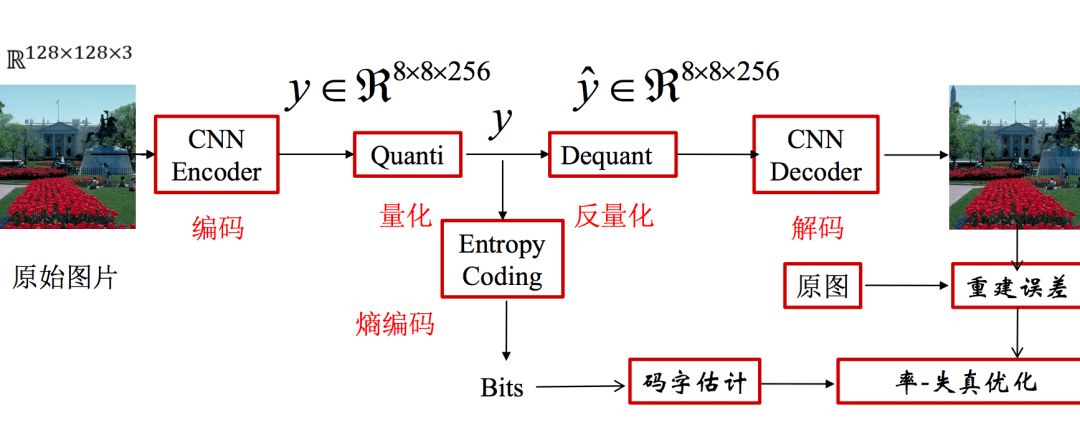
上图中每个模块的具体作用,可以参考如何设计基于深度学习的图像压缩算法中的解释。
图像压缩数据集
设计好网络模型后,需要使用图像进行训练。由于图像压缩属于无监督学习,无需人工标注,因此数据集是比较容易搜集的。无论是从网上爬取,还是自行使用相机拍摄,都不难得到大量高清图片。
常用的测试集有:
Kodak PhotoCD数据集,图像分辨率768x512,约40万像素;
Tecnick数据集,约一百四十万像素。
CVPR 2818 CLIC数据集,图像类别广泛,分辨率不等(512至2048),文件尺寸不等(几百K到几M)。
深度学习视频压缩框架
深度学习视频压缩与图像压缩的主要差别在于增加了帧间预测/差值。
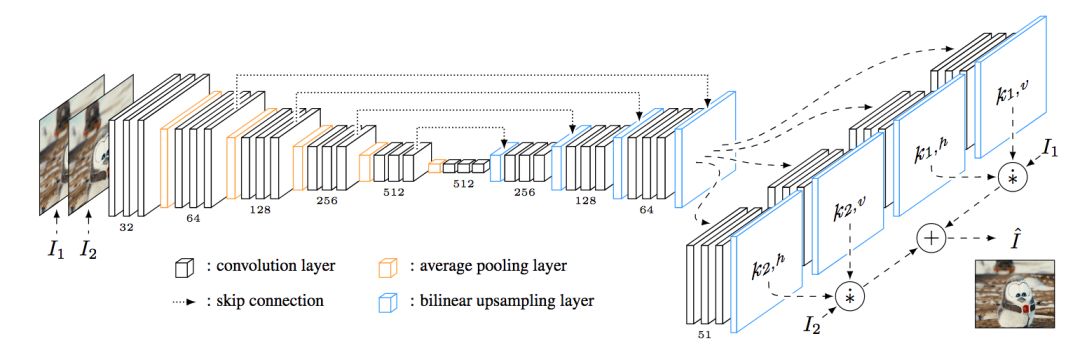
基于卷积网络进行帧间预测
帧间预测能极大得减少帧间冗余。以1个参考帧,预测N-1帧为例,帧间预测的约束为参考帧和预测码字远小于每帧单独压缩的码字:
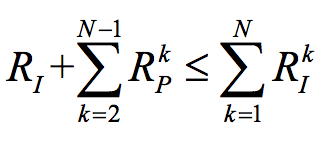
深度学习图像视频压缩进展介绍
深度学习图像压缩的主要发展方向:
RNN
CNN
GAN
这部分内容可以参考公开课ppt以及概览CVPR 2018神经网络图像压缩领域进展一文。
视频压缩方面,近年来的研究热点是将CNN与现有的视频编码器相结合。
编码单元选择
Liu Z、Yu X、Chen S等在2016年发表了CNN oriented fast HEVC intra CU mode decision,使用CNN学习预测编码单元模式的分类(2N x 2N或N x N)。
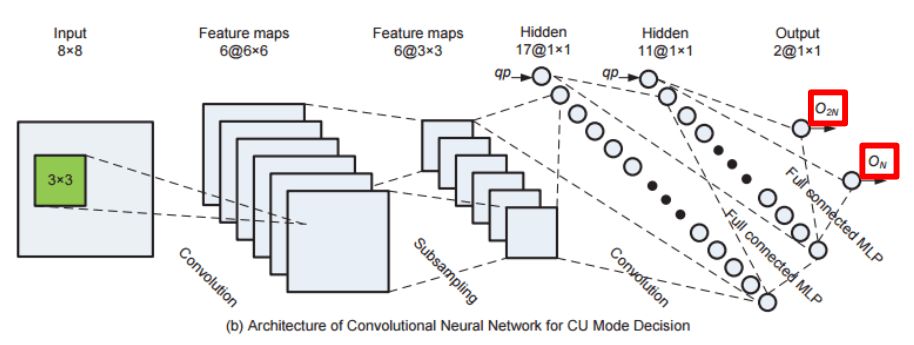
O2N、ON输出为码率失真代价
下采样编码
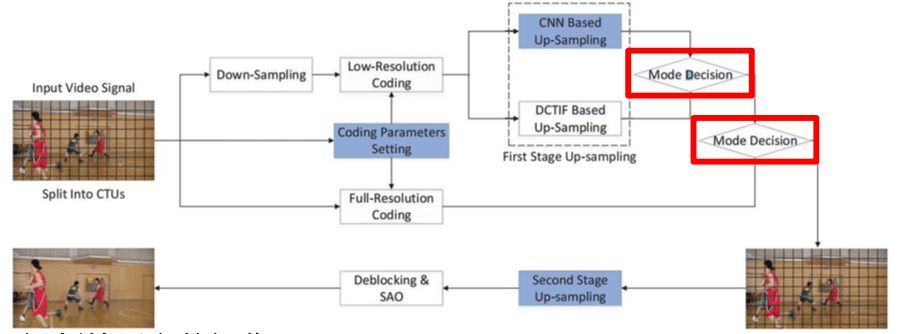
Jiahao Li等在2018年发表的Fully Connected Network-Based Intra Prediction for Image Coding对视频帧进行了分块处理,对适合进行下采样的块执行下采样操作,而对不适合进行下采样的块不执行下采样操作。之后,对下采样的块根据情况分别使用CNN或DCTIF进行上采样,以重建图像。为了达到更好的效果,亮度通道和色度通道使用了不同的网络架构。
视频帧环路滤波和后处理
Park W S和Kim M在2016年发表的CNN-based in-loop filtering for coding efficiency improvement中,使用CNN提升了HEVC的环路滤波(包括去区块滤波和SAO滤波)的效果。
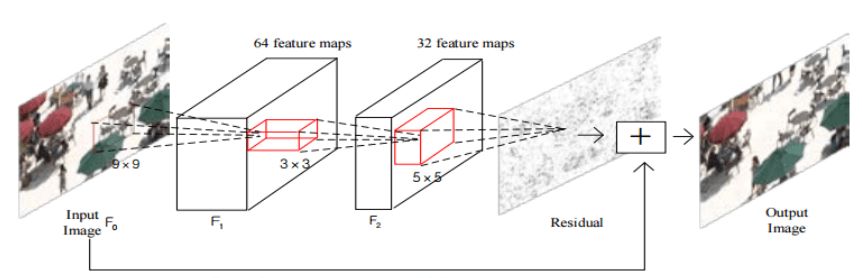
类似地,Yuanying Dai等在2016年发表的A Convolutional Neural Network Approach for Post-Processing in HEVC Intra Coding,使用CNN网络改进了HEVC的后处理过程。
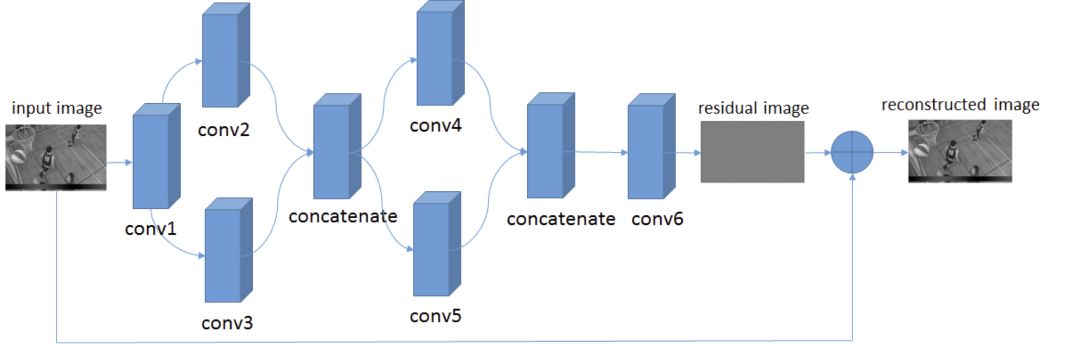
深度学习视频压缩的优势和劣势
使用深度学习进行单纯的图像压缩,应用场景有一定局限性。深度学习在视频压缩领域潜力更大。深度学习在视频压缩领域的主要优势在于:
能够实现更好的变换学习,从而取得更好的效果。
端到端的深度学习模型能够自行学习,而传统的视频压缩工作需要手工设计很多东西。
传统的视频压缩方法通常通过一些启发式的方法进行帧间预测,从而减少帧间冗余。而深度学习能够基于光流等进行预测。
另一方面,基于深度学习进行视频压缩也会遇到很多挑战。比如控制实现帧间预测占用的比特。
图鸭科技技术介绍
CVPR 2018 CLIC
在CVPR 2018学习图像压缩挑战上,图鸭团队为三个赢家之一,MOS、MS-SSIM两项指标均为第一。
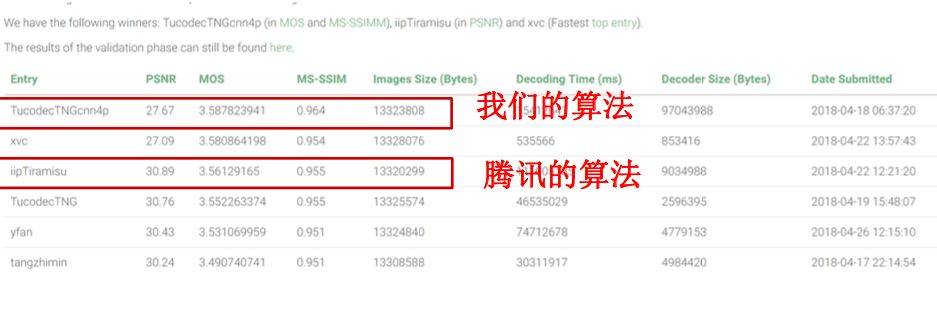
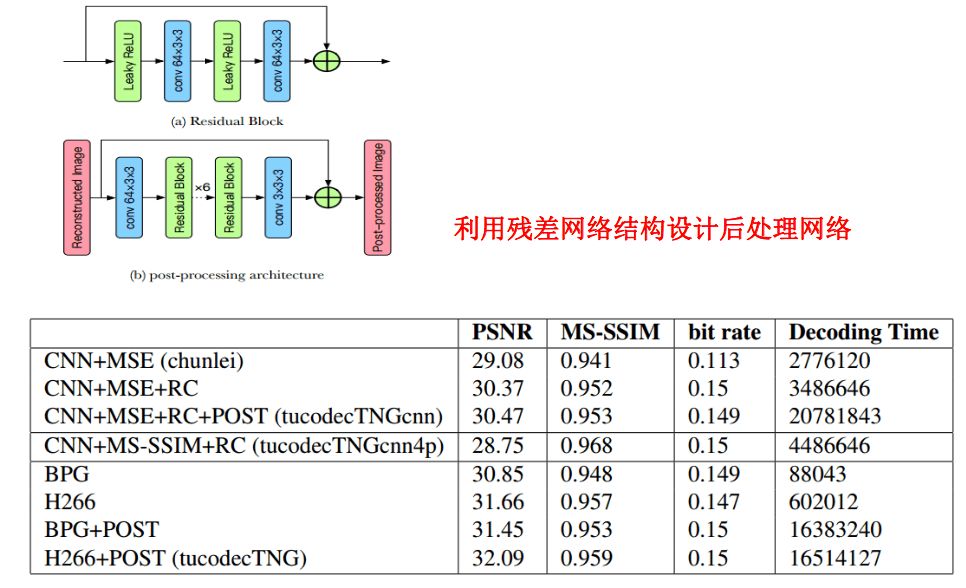
TucodecTNGcnn4p基于端到端的深度学习算法,其中使用了层次特征融合的网络结构,以及新的量化方式、码字估计技术。网络使用了卷积模块和残差模块,损失函数纳入了MS-SSIM。
基于深度学习超分辨率重建图像
在这一领域,图鸭科技重点关注低码率下的超分辨率重建。因为低码率下图像难免有比较多的失真,应用超分辨率重建技术能缓解这些图像上的瑕疵,取得更好的显示效果。而高码率图像保留了原图更多的细节,相对而言不是非常适合应用超分辨率技术。
基于深度学习的视频压缩
如前所述,图鸭科技认为相对图像压缩,深度学习在视频压缩领域潜力更大。目前图鸭科技在基于深度学习的视频压缩方面,已经能够取得与x265媲美的效果。
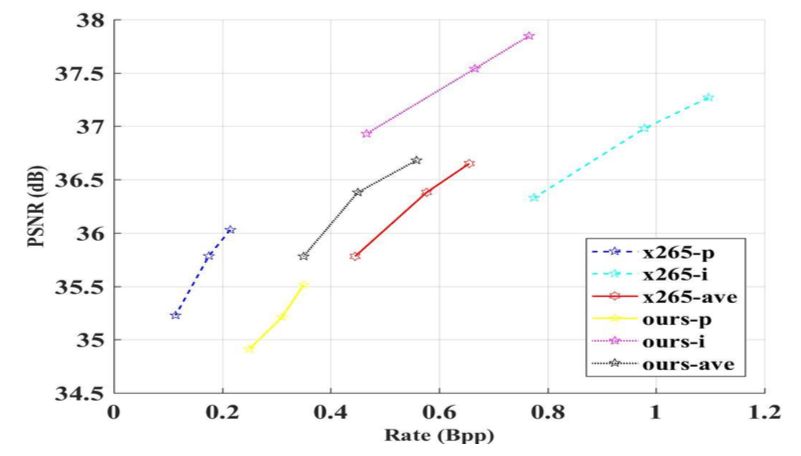
基于深度学习的结构化存储
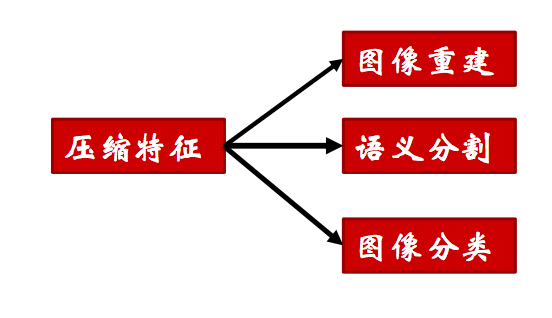
相比传统方法,深度学习编码图像的算力负担较重。然而,另一方面,图像的压缩特征不仅可以用于重建图像,还可以为语义分割、图像分类提供帮助。
问答环节
基于GAN进行图像压缩
GAN主要用于图像生成领域。但在进行图像压缩时,GAN会遇到一个问题,就是它会改变一些细节(生成一些新的细节)。因此,GAN这一的技术方向的选择常常取决于项目需求。例如,对于人脸图像来说,如果感兴趣区域是人脸,那么对感兴趣区域以外的区域可以使用非常低的码率压缩,重建图像时利用GAN生成细节。
量化方法的选择
建议大家参考相关论文自行选择。因为量化方法的选择往往还和网络中的其他模块相关。例如,如果编码器部分选用的激活输出的是二值(0、1),那么量化其实就不是那么重要了。
压缩时间
一般而言,基于深度学习的压缩算法,和传统算法相比,在CPU上压缩时间处于劣势。不过也有例外。比如,在图鸭科技的测试中,在CPU上,基于CNN的算法实际上比H266要快。H266虽然属于传统算法,但是复杂度其实很高。
未来随着GPU、专用深度学习芯片的算力提升,压缩时间不会成为应用深度学习压缩算法的最大障碍。
-
视频压缩算法的特点和处理流程是怎样的?2021-06-08 1640
-
怎么在FPGA设计中使用先进的视频压缩技术?2021-04-08 1760
-
视频压缩是什么?视频压缩有什么好处?2020-08-07 35948
-
基于SOC架构的高清视频压缩技术2020-02-20 2775
-
视频压缩介绍(二)2019-03-02 1019
-
视频监视领域的视频压缩与数据流2019-01-09 1011
-
视频监控领域的视频压缩与数据流2019-01-03 1471
-
基于Android系统的H.264视频压缩技术实现2015-11-18 814
-
数字图像与视频压缩编码技术发展趋势2013-09-25 2530
-
视频压缩技术2010-09-30 2021
-
视频压缩IPcore设计2009-11-30 801
-
嵌入式视频图像系统的压缩算法2009-03-30 1458
全部0条评论

快来发表一下你的评论吧 !
