

深度学习模型优于人类医生?
电子说
描述
前几天,德国和法国的几位研究人员在Oxford Academic上发表了一篇名为Man against machine: diagnostic performance of a deep learning convolutional neural network for dermoscopic melanoma recognition in comparison to 58 dermatologists的文章,这个长长长长的标题告诉我们,这又是一篇让人去跟机器比赛的故事,目的是看谁识别皮肤黑色素瘤的准确度更高。最终结果表明深度学习模型优于人类医生。

但今天,澳大利亚的医学博士、放射科医生Luke Oakden-Rayner在推特上质疑论文的严谨性,认为结论过于草率,低估了人类表现。到底双方哪种说法更合理呢?我们先看看这篇论文到底讲了什么。
CNN vs 人类
过去几十年,黑色素瘤成为威胁公共安全的一大主要挑战,连续攀升的发病率以及死亡率,让早期发现及预防成为诊断的关键。多项分析表明,皮肤镜的应用大大提高了诊断准确率。然而,每位医师接受的训练不同,水平也参差不齐,目前黑色素瘤的平均诊断准确度还不到80%。
最近几年,一些自动计算机图像分析技术的出现,意在帮助提高医疗诊断准确率和效率。但这些方法都有限制,它们都使用人类规定的皮肤镜诊断标准进行的判断,例如是否有多色、特殊形态例如条纹状和结节状,或不规则血管结构。
2017年,Esteva等人发表论文,宣布他们创建了一种基于卷积神经网络的深度学习模型,可以对图片进行分类,其中CNN无需被人类的标准所限制,它可以将数字图片分解成像素级水平,并最终进行诊断。这篇论文也被看作是革命性的作品。
而本次德国和法国的研究者目的是训练、验证并测试一个深度学习CNN,让它对皮肤镜成像进行诊断分类,判断是黑色素瘤还是良性的痣,并将结果和58位皮肤科医生相比较。
具体方法
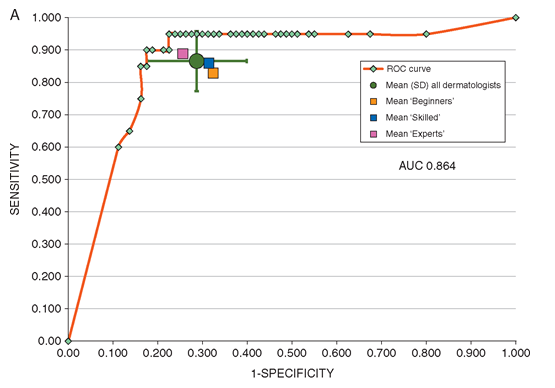
谷歌的Inception v4 CNN架构是用皮肤镜图像和对应的诊断结果训练并验证的。在横向的人类医生验证中有100张图片组成的测试集(其中第一步只用皮肤镜观察,第二步会加上诊断信息和图片)。对输出进行测量的标准主要有敏感性(sensitivity)、特异度(specificity)和CNN对病变处的诊断分类的ROC曲线的AUC值与读者研究中58名人类医生的对比。
次要评估指标包括皮肤科医生在管理决策时的诊断表现,以及在两个不同阶段上诊断的差异。除此之外,CNN的性能还会与2016年国际生物医学成像研讨会(ISBI)挑战赛上排名前五的算法进行比较。
对比结果
在人类医生的第一阶段表现中,他们的得分较接近平均水平,在对病变的分类上,敏感性为86.6%(±9.3%),特异度为71.3%(±11.2%)。第二阶段增加了更多信息后,敏感性上升至88.9%(±9.6%,P=0.19),特异度升为75.7%(±11.7%,P<0.05)。
而CNN的ROC曲线在第一阶段中,特异度就高于人类医生,为82.5%。而CNN的ROC AUC分数也比医生的平均ROC面积要高,为0.86 vs 0.79,P<0.01。CNN的最终分数与2016 ISBI挑战赛上前三的算法分数接近。
结论
在包括30名专家的58位皮肤科医生团队中,这是我们首次将CNN与人类进行对比。大多情况下,CNN的表现要优于人类医生。研究者并不否认医生的经验和努力,而是认为在CNN图像分类技术的帮助下,诊断率会更高。
AI赢了?
这篇论文发表后,获得了许多大V转发,其中就包括卷积网络之父Yann LeCun。

虽然只重复了一遍对比结果,LeCun的转发也获得了300多点赞。
同时,华盛顿邮报、医学网站等媒体也纷纷报道了这一结果,声称“AI打败了人类”,但有人却针对其中的统计方法提出了质疑。
论文很好,但有瑕疵
今天,放射科专家、医学博士Luke Oakden-Rayner在推特上表示:这篇论文有瑕疵!简单地说,他认为论文研究者低估了人类医生的表现。论智君将具体原因编译如下:
我认为,研究者们在对比人类和机器时用的是两种不同的指标!对机器用的是AUC,对人类用的是“ROC区域”得出的平均敏感性和特异度。除了指标不同,“ROC区域”整体就比AUC要低。实际上,皮肤科医生表现的越好,它就越偏离假设的AUC。
根据论文数据,我们可以也计算一下模型的“ROC区域”,结果如下,跟人类的分数一样都是79。

在特异度方面,对比的缺陷就更不易察觉了。专家医生分布在ROC曲线上,所以平均敏感性和特异度把医生的平均值放在了曲线内,同时模型还是在曲线上测试的。再说一遍,人类被低估了。下面是ROC曲线的其中一个例子,粉点是平均分。
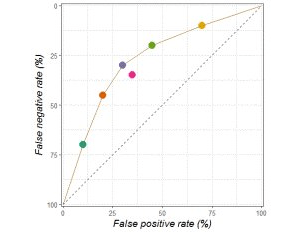
另外,我不确定研究者是否选择了合适的操作点(OP),在CNN和医生对比的过程中,研究人员似乎是基于测试数据进行选择的。在它们的ROC中,一个合理选择的OP大大降低了敏感性和特异度的值。下图中紫色的点是他们的OP,黑色的点只是靠近OP所在区域。
注意这个ROC曲线看起来有点奇怪,因为前部支持的点很少,也就是说这个区域比上部更缺少数据支持。
最后,我不清楚他们是怎么计算p-value的。在给定操作点(平均医生的敏感性)的情况下,研究者认为特异度在小于0.01的p-value下更好,但是在ROC数字表现在曲线上时置信区间竟然有68%!即使是图表解释的有问题,或者存在±2的标准差,95%的数值还是在曲线上的。我不知道这跟p-value<0.01有什么关系。
要说明的是,我并不全盘否定这篇论文,我认为这种讨论很有意义。只是其中有一些我认为不严谨的地方,希望我的建议有用。
结语
说到最后,其实是在对比方式上存在质疑。也许论文的研究者需要考虑一下他们的统计测试是否公平,因为只对医生们的检测敏感性和特异度取平均值说服力还是不够。这也给我们提了醒,在阅读论文时不要一味地迷信,要勤于思考,在发现论文闪光点的同时还要确保逻辑上的准确。
-
AI大模型与深度学习的关系2024-10-23 3699
-
深度学习中的模型权重2024-07-04 5457
-
深度学习的模型优化与调试方法2024-07-01 2486
-
大语言模型:原理与工程实践+初识22024-05-13 1613
-
基于深度学习的情感语音识别模型优化策略2023-11-09 1625
-
什么是深度学习算法?深度学习算法的应用2023-08-17 3050
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2028
-
大模型为什么是深度学习的未来?2023-02-16 2801
-
深度学习模型是如何创建的?2021-10-27 2290
-
labview调用深度学习tensorflow模型非常简单,附上源码和模型2021-06-03 39839
-
深度模型中的优化与学习课件下载2021-04-07 1170
-
谷歌深度学习如何处理人类语言?2021-03-01 1709
-
如何使用深度学习实现语音声学模型的研究2020-05-09 1102
-
“人工智能医生”会取代人类医生吗?2019-02-21 4537
全部0条评论

快来发表一下你的评论吧 !
