

全新轻量级ViSTA-SLAM系统介绍
描述
无需相机内参、极致轻量的前端(前端模型大小仅为同类35%),实时单目视觉SLAM,ViSTA-SLAM。与现有方法相比,ViSTA-SLAM不仅更轻、更快,在相机跟踪和密集3D重建质量方面也均表现出色。
• 文章:
ViSTA-SLAM: Visual SLAM with Symmetric Two-view Association
• 作者:
Ganlin Zhang, Shenhan Qian, Xi Wang, Daniel Cremers
• 论文链接:
https://arxiv.org/abs/2509.01584
• 编译:
INDEMIND
Github仓库:
https://github.com/zhangganlin/vista-slam
01本文核心内容
经典视觉SLAM方法大致可分为两类,第一类是基于特征的SLAM;第二类称为直接法。这两类方法通常都采用前端(基于特征或直接法)和后端进行优化,最常见的是联合优化位姿和结构的光束平差法。然而,它们都严重依赖于精确的相机内参。
基于深度学习的SLAM方法虽然强大,但大多数方法仍然需要精确的相机内参,并且由于计算量大,很多方法难以实现真正的实时性能。
而随着3D基础模型的出现,出现了几种无需内参的SLAM框架,旨在无需校准即可生成密集输出。例如,Spann3R以及其他一些方法将两视图的DUSt3R模型扩展到序列输入,直接在统一的全局坐标系中回归点云。然而,尽管这些方法解决了某些经典限制,但它们仍存在显著的缺陷:
当前的双视图模型采用不对称架构,将两个视图的点图回归到第一个视图的坐标,这使得在后端优化(例如闭环检测)中难以解耦视图。
纯回归方法利用先前的记忆来预测即将到来的帧,但存在漂移问题,并且一旦轨迹变长就会开始遗忘。
SLAM3R等方法基于当前的双视图模型,继承了具有两个独立解码器的不对称架构,导致模型规模较大。基于子地图的方法则采用规模更大的多视图模型来构建子地图,这进一步增大了前端模型的规模。
为了解决这些问题,我们提出了ViSTA-SLAM,这是一种基于对称双视图关联的新型实时单目视觉SLAM管道。其核心是一个轻量级的对称双视图关联(STA)模型前端,它以两张RGB图像作为输入,同时回归出它们各自局部坐标系中的两个点图,以及它们之间的相对相机姿态。在训练过程中,我们对相对姿态施加循环一致性约束,并对点图施加几何一致性约束,以提高准确性和稳定性。与之前的3D模型不同,STA对其输入完全对称:不指定任何视图为参考,对两个视图应用相同的编码器-解码器架构。在后端,我们执行Sim(3)姿态图优化,并结合闭环来减少漂移并确保全局一致性。为了进一步增强鲁棒性,每个视图都由多个节点而非单个节点表示,这些节点通过仅含尺度的边连接,以处理不同前向传递中的尺度不一致。
这种对称设计使得我们的前端比现有方法轻量得多,STA是我们的模型大小仅为MASt3R的64%,VGGT的35%。与先前将多个视图组合到单个子图节点的方法不同,我们的方法为每个视图在位姿图中分配单独的节点。利用STA前端生成的局部点图,每个节点都可以独立表示,仅通过相对变换与其他节点相连。与基于子图的方法相比,这种设计产生了更灵活的图结构和更强的鲁棒性。这种灵活性和轻量级架构的结合是我们选择对称双视图模型作为前端的原因。
主要贡献如下:
• 我们设计并训练了一个轻量级、对称的双视图关联网络作为前端,仅以两张RGB图像作为输入,并回归它们在局部坐标系中的点图以及相对相机位姿。
• 我们构建了一个具有闭环的Sim(3)位姿图,并使用Levenberg-Marquardt算法对其进行优化,以实现快速且稳定的收敛。
• 通过整合这些组件,我们提出了一种实时的单目密集视觉SLAM框架,无需任何相机内参即可运行。我们的方法在真实世界的7-Scenes和TUM-RGBD数据集上实现了最先进的性能,无论是相机轨迹估计还是密集的3D重建。
02方法架构
作为一个单目密集SLAM(图2),我们的目标是使用密集点云同时在线跟踪相机姿态并重建记录的场景。为了实现这一目标,我们提出了一种轻量级且新颖的对称两视图关联模型作为我们管道的前端,该模型提取两个相邻输入帧的相对姿态和局部点图,通过优化结合回环闭合来减少漂移累积。
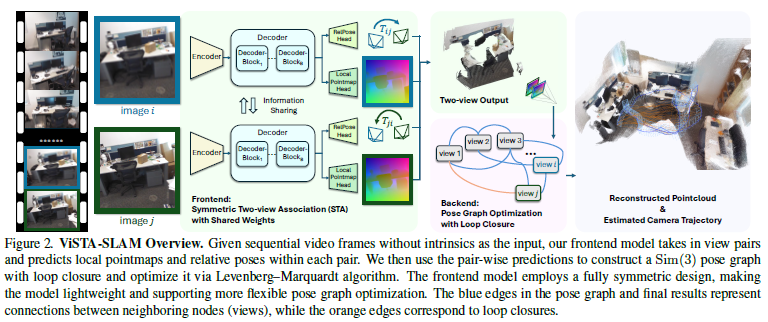
对称双视图关联模型
在经典的单目SLAM管道中,双视图估计是最重要的组成部分之一,因为它建立了几何约束,从而允许进一步优化。在本工作中,我们遵循相同的原则;然而,我们没有依赖传统方法,而是提出了一种基于深度学习的对称双视图关联(STA)模型,该模型在SLAM过程中无需相机内参。
STA是一个深度神经网络,输入是任意两张RGB图像,输出是这两张图之间的相对相机位姿,以及一个局部的点云地图。
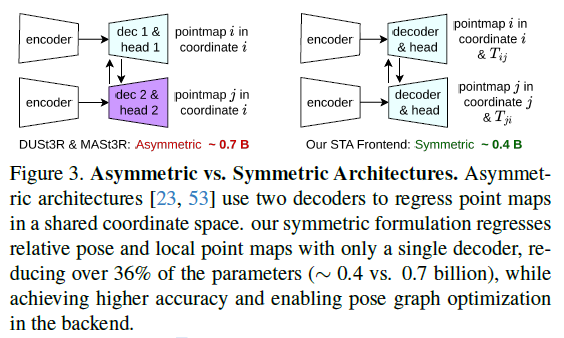
如图3所示,以往的非对称(Asymmetric)架构,通常需要两个独立的解码器来分别预测两张视图在同一个共享坐标系下的点云。而ViSTA-SLAM的对称(Symmetric)架构,则 仅用一个解码器 来回归局部点云图,同时预测出相对位姿。这种设计有两大好处:
极致轻量: 由于共享了大部分网络结构,并且减少了一个解码器,其模型参数量大幅降低。作者指出,其前端模型大小仅为0.4B参数,相比之前SOTA方法的0.7B,减少了超过65%。
约束更优: 对称的设计使得从(图A, 图B)预测的位姿,与从(图B, 图A)预测的位姿天然地互为逆矩阵,这为后端的位姿图优化提供了更规整、更优质的约束。
后端位姿图优化
前端提供了大量的、两两视图间的局部运动估计。后端的目标就是将这些“碎片化”的信息拼成一幅完整的“拼图”。
ViSTA-SLAM的后端构建了一个 Sim(3)位姿图。在图中,每个相机视图是一个节点,而由前端STA模型估计出的相对位姿则构成了连接节点的边。构建这样一个图的好处是,可以通过图优化算法(如Levenberg–Marquardt)来调整所有节点的位姿,使其全局误差最小,从而有效抑制单步估计误差累积而产生的“漂移”。
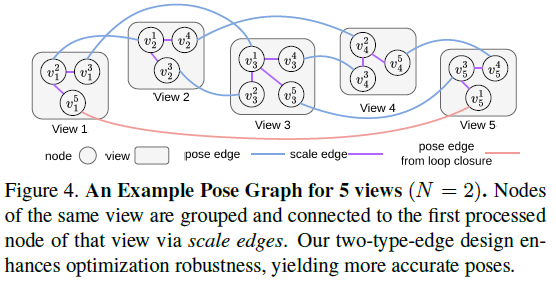
后端还集成了 回环闭合(Loop Closures) 检测。当系统检测到相机回到了一个曾经到过的地方时,就会在位姿图中当前节点与历史节点之间增加一条强力的“回环边”(上图中的橙色边)。这条边会像一个“锚”一样,将整个轨迹拉回到正确的位置上,极大地消除累积误差。
03实验评估
相机轨迹评估
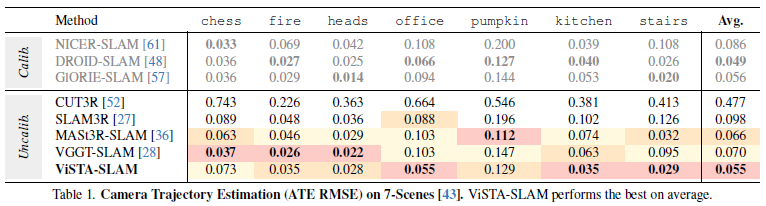
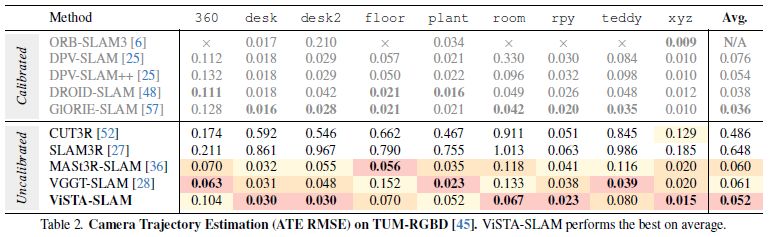
在表1和表2中,我们报告了ATE均方根误差。ViSTA-SLAM在两个数据集上均取得了最佳的平均性能,分别比当前的最先进方法MASt3R-SLAM高出17%(0.055对比0.066)和13%(0.052对比0.060),并且超越了一些校准方法,如Deep patch visual SLAM。在TUM-RGBD360场景中,ViSTA-SLAM的表现稍逊,这是由于主要的相机旋转运动导致前端模糊和性能下降。其他方法如VGGT-SLAM要么采用更复杂的多视角前端,要么采用更密集的优化来减少这种影响。纯回归方法由于存在遗忘效应,在相机运动幅度大且序列长的情况下难以保持一致的配准。
在图5中,我们展示了在7-Scenes办公室和TUMRGBD房间上不同方法估计的轨迹。CUT3R在长序列上存在严重的遗忘问题;SLAM3R在具有挑战性的TUM-RGBD房间场景中点配准效果不佳,因此无法生成正确的相机位姿。与纯回归方法相比,MASt3R-SLAM和VGGT-SLAM表现良好,而ViSTA-SLAM则实现了更高的轨迹精度。
密集重建评估
在表3中,我们对各种方法的重建质量进行了评估。
凭借精确的相机位姿和一致的局部点云,ViSTA-SLAM在所有方法中实现了最佳的切比雪夫距离。尽管采用了轻量级的两视图前端,但ViSTA-SLAM结合定制的Sim(3)位姿图优化,在精度(0.45对比0.52)方面显著优于多视图前端方法,同时在完整性方面达到或超过了它们。
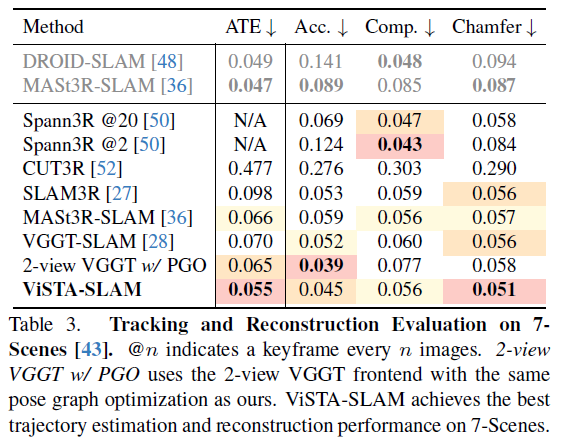
为了证明我们轻量级前端的有效性,我们添加了另一个强大的基准,用两视图的VGGT替换我们的STA模型作为前端,并进行相同的姿态图优化。ViSTA-SLAM在切比雪夫距离、完整性和绝对轨迹误差方面仍表现出色,突显了我们的轻量级对称前端在SLAM任务中优于像VGGT这样的大型多视图模型。
在图6中,我们展示了在7-Scenes的redkitchen、TUM-RGBD房间和BundleFusion的apt1场景中的定性重建结果。CUT3R由于遗忘问题无法正确重建,而SLAM3R在相机视角变化较大的场景中表现不佳。MASt3R-SLAM和VGGT-SLAM在物体边界处产生伪影,无法清晰区分前景和背景,并且在不同视图之间出现错位。相比之下,ViSTA-SLAM通过训练期间的几何一致性约束克服了这些挑战。值得注意的是,VGGT-SLAM在apt1场景中途失败,因为后端优化发散,这源于基于RANSAC的3D单应性估计不稳定,可能会采样平面区域并造成歧义。在他们提出的SL(4)姿态图优化中。
模型大小与速度
我们在表4中比较了各方法的前端模型大小和处理速度。由于我们的对称设计,解码器和回归头仅使用现有前馈模型参数的一半。因此,我们的模型更加紧凑:仅为MASt3R(用于MASt3R-SLAM)的64%,VGGT(用于VGGT-SLAM)的35%。
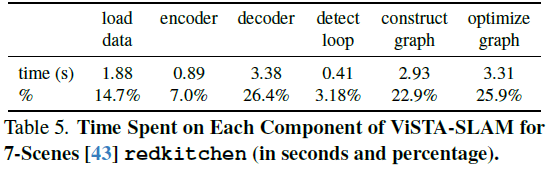
速度评估进一步证实了ViSTA-SLAM实现了实时性能。得益于紧凑的前端和稀疏的位姿图,我们的方法在运行时间方面极具竞争力——比纯回归方法CUT3R和SLAM3R更快,与VGGT-SLAM相当。值得注意的是,VGGT-SLAM每32个关键帧才进行一次推理,减少了总的推理步骤。当用两视图的VGGT替换我们的STA模型,每次输入两视图信息时,运行速度显著变慢,这进一步证明了我们轻量级前端的有效性。表5展示了主要流水线组件所花费的运行时间百分比。解码两视图信息和位姿图优化占据了处理时间的主导地位。

04总结
我们提出了一种新颖的单目无内参SLAM,即ViSTA-SLAM,其前端采用轻量级的对称两视图关联模型,后端则采用具有闭环的Sim(3)位姿图优化。实验结果表明,ViSTA-SLAM在相机跟踪精度和3D重建质量方面表现出色。同时,与当前最先进的方法相比,它更轻量,运行速度更快或相当。
-
百度智能云推出全新轻量级大模型2024-03-22 1516
-
轻量级数据库有哪些2023-08-28 7863
-
轻量级”的电源系统,该如何设计2023-05-20 1602
-
“轻量级”的电源系统,该如何设计?2023-04-05 1509
-
PSoC NeoPixel Easy轻量级库2022-11-17 972
-
轻量级Kubernetes-K3S工具介绍2022-06-21 4010
-
轻量级的ui框架如何去制作2021-07-14 1255
-
轻量级深度学习网络是什么2020-04-23 3149
-
轻量级Agent平台怎么测试?2019-09-27 3289
-
10个轻量级框架2019-07-17 2533
-
创建51轻量级操作系统2016-09-29 4244
-
轻量级工作流引擎架构设计2011-04-12 1071
-
基于Linux的轻量级嵌入式GUI系统及实现2009-08-31 868
-
一种嵌入式Linux轻量级GUI系统设计2009-04-20 495
全部0条评论

快来发表一下你的评论吧 !
