

如何基于Tf-Idf词向量和余弦相似性根据字幕文件找出相似的TED演讲
电子说
描述
编者按:数据科学顾问Gunnvant Saini讲解了如何基于Tf-Idf词向量和余弦相似性根据字幕文件找出相似的TED演讲。
好吧,我喜欢TED演讲,谁不喜欢呢?当我查看Kaggle上的TED数据集(rounakbanik/ted-talks)时,有不少发现。首先,由于数据集包含许多TED演讲的字幕,因此我们有了一个非常丰富、语言学上结构良好的语料。其次,由于该语料具备良好的语言学属性,它很可能和Reuters 20 News Group或者古登堡语料库差不好。这让我灵机一动:
我有许多TED演讲的字幕数据,我能尝试找到一种根据演讲相似性推荐TED演讲(就像TED官网做的那样)的方法吗?
当然,TED官网所用的推荐系统,会比我这里演示的复杂得多,同时涉及一些用户交互的历史数据。
本文想要演示如何仅仅基于内容生成推荐。当你不具备任何用户交互数据时,比如在刚开始的时候,这一技术变得极为重要,它有助于向消费者提供内容相关的上下文推荐。
数据
字幕储存于transcript一列,每行对应一个演讲。
import pandas as pd
transcripts=pd.read_csv("E:\Kaggle\ted-data\transcripts.csv")
transcripts.head()
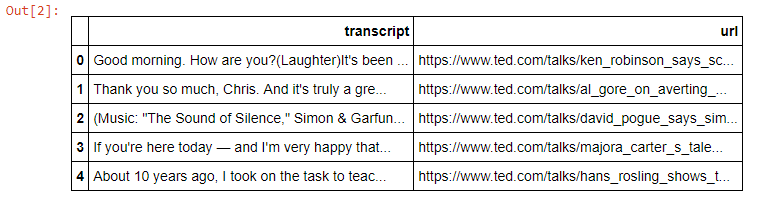
可以看到,从url很容易就能提取演讲的标题。我的目标是使用字幕文本创建相似性的测度,然后为给定演讲推荐4个最相似的演讲。
transcripts['title']=transcripts['url'].map(lambda x:x.split("/")[-1])
transcripts.head()
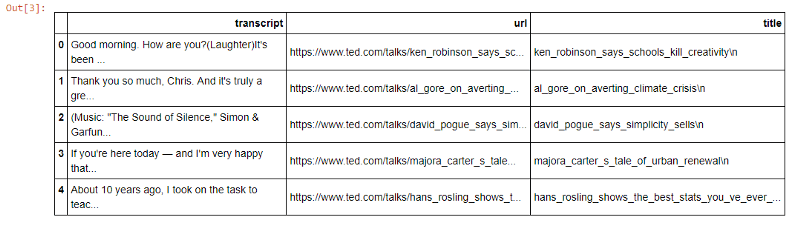
好了,数据预处理完毕,我可以开始创建推荐系统了:
为字幕创建向量表示
为上一步创建的向量表示创建一个相似性矩阵
基于某种相似性测度,为每个演讲选定4个最相似的演讲
使用Tf-Idf创建词向量
由于我们的最终目标是基于内容相似性推荐演讲,我们首先要做的就是为字幕创建便于比较的表示。其中一种方法是为每个字幕创建一个tfidf向量。但是,到底什么是tfidf呢?让我们先讨论下这个概念。
语料库、文档和频次矩阵
为了表示文本,我们将把每个字幕看成一个“文档”,然后将所有文档的集合看成一个“语料库”。然后,二维码将创建一个向量,表示每个文档中词汇出现的次数,像这样:
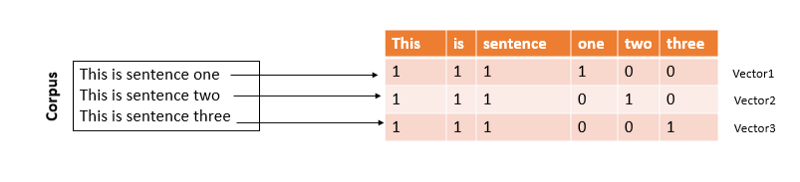
这些向量组成了一个矩阵,称为频次矩阵(count matrix)。不过,这样的表示方式有一个问题。比如,“one”在文档1中只出现过一次,但在其他文档中均未出现,所以“one”是一个重要的词汇。但是如果我们查看文档1的频次向量,“one”的权重和“This”、“is”等词一样,都是1. 而Tf-Idf可以解决这一问题。
词频-逆向文档频率(Tf-Idf)
为了理解Tf-Idf如何帮助识别词汇的重要性,让我们询问自己几个问题,如何决定一个词汇是否重要?
如果这个词汇在文档中多次出现?
如果这个词汇很少在语料库中出现?
同时满足1和2?
如果一个词汇在某个文档中频繁出现,但在语料库中的其他文档中很少出现,那么该词汇对这个文档很重要。词频(term frequency)衡量词汇在给定文档中出现的频繁程度,而逆向文档频率(inverse document frequency)衡量词汇在语料库中出现的罕见程度。两者之积Tf-Idf衡量词汇的重要程度。使用sklearn机器学习框架,创建Tf-Idf向量表示非常直截了当:
from sklearn.feature_extraction import text
Text=transcripts['transcript'].tolist()
tfidf=text.TfidfVectorizer(input=Text,stop_words="english")
matrix=tfidf.fit_transform(Text)
现在我们已经解决了如何在词向量中体现词汇重要性的问题,我们将开始考虑下一个问题,如何个找到给定文档的相似文档(在我们的例子中是TED演讲字幕)?
查找相似文档
通常,我们使用余弦相似度,衡量Tf-Idf向量的接近程度。也就是说,我将基于Tf-Idf向量创建一个余弦矩阵,表示文档两两之间的相似程度:
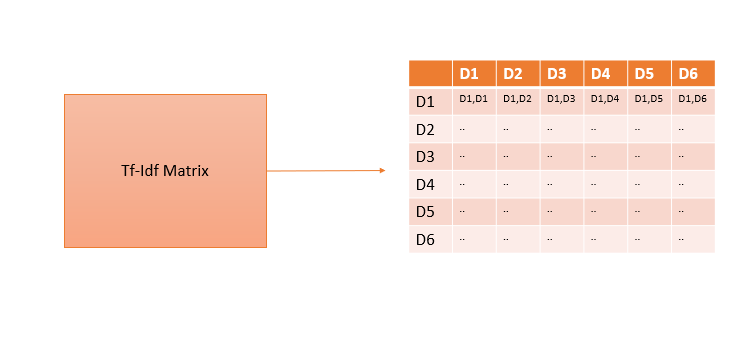
同样,使用sklearn做这个非常直接:
from sklearn.metrics.pairwise import cosine_similarity
sim_unigram=cosine_similarity(matrix)
创建了相似度矩阵后,我只需查询这一矩阵,在每一行找出4个余弦相似度最高的列,就可以为每个文档(字幕)选出最相似的4个文档了。
def get_similar_articles(x):
return",".join(transcripts['title'].loc[x.argsort()[-5:-1]])
transcripts['similar_articles_unigram']=[get_similar_articles(x) for x in sim_unigram]
让我们看下效果,比如,随便挑一个演讲,看看哪4个演讲和它最相似:
transcripts['title'].str.replace("_"," ").str.upper().str.strip()[1]
'AL GORE ON AVERTING CLIMATE CRISIS'
transcripts['similar_articles_unigram'].str.replace("_"," ").str.upper().str.strip().str.split(" ")[1]
['RORY BREMNER S ONE MAN WORLD SUMMIT',
',ALICE BOWS LARKIN WE RE TOO LATE TO PREVENT CLIMATE CHANGE HERE S HOW WE ADAPT',
',TED HALSTEAD A CLIMATE SOLUTION WHERE ALL SIDES CAN WIN',
',AL GORE S NEW THINKING ON THE CLIMATE CRISIS']
显然,从标题上看,这些演讲的主题是相似的。
-
基于结构相似性可靠性监测结果2024-02-05 356
-
PyTorch教程15.7之词的相似性和类比2023-06-05 711
-
一种基于TF-IDF的Webshell文件检测方法2021-04-26 903
-
TF-IDF的基础模型和使用教程和算法代码免费下载2020-05-21 598
-
如何使用会话时序相似性进行矩阵分解数据填充2019-01-23 1071
-
计算文本相似度几种最常用的方法,并比较它们之间的性能2018-06-30 54679
-
基于节点相似性社团结构划分2018-01-10 775
-
云模型重叠度的相似性度量算法2018-01-07 1058
-
TF-IDF算法的改进及在语义检索中应用2018-01-02 1246
-
基于Document Triage的TF-IDF算法2017-12-27 481
-
一中余弦相似度的改进方法2017-11-01 1114
-
TF-IDF测量文章的关键词相关性研究2016-01-26 3155
-
基于相似性的图像融合质量的客观评估方法2009-10-31 531
-
影像匹配中几种相似性测度的分析2009-01-09 833
全部0条评论

快来发表一下你的评论吧 !
