

RNN及其变体LSTM和GRU
电子说
描述
对于文本和语音这样的序列化数据而言,循环神经网络(RNN)是非常高效的深度学习模型。RNN的变体,特别是长短时记忆(LSTM)网络和门控循环单元(GRU),在自然语言处理(NLP)任务中得到了广泛应用。
然而,尽管在语言建模、机器翻译、语言识别、情感分析、阅读理解、视频分析等任务中表现出色,RNN仍然是“黑盒”,难以解释和理解。
有鉴于此,香港科技大学的Yao Ming等提出了一种新的可视化分析系统RNNVis,基于RNNVis,可以更好地可视化用于NLP任务的RNN网络,理解RNN的隐藏记忆。
在介绍RNNVis系统之前,先让我们温习一下RNN及其变体LSTM和GRU.
RNN及其变体
循环神经网络
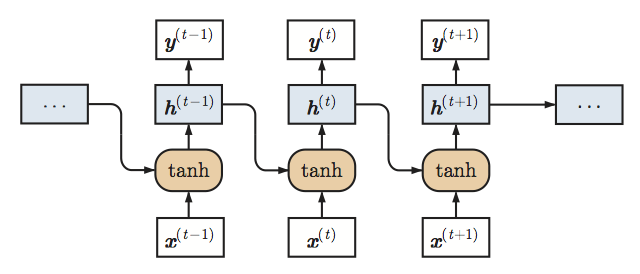
如上图所示,原始RNN接受序列化输入{x(0), ..., x(T)},并维护一个基于时间的隐藏状态向量h(t)。在第t步,模型接受输入x(t),并据下式更新隐藏状态h(t-1)至h(t):

其中,W、V为权重矩阵而f是非线性激活函数。上图中,f为tanh.
h(t)可直接用作输出,也可以经后续处理后用作输出。比如,在分类问题中,对隐藏状态应用softmax运算后输出概率分布:
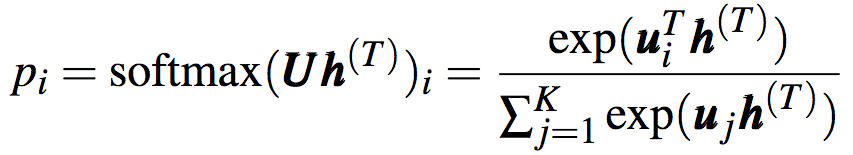
长短时记忆网络
和原始RNN不同,LSTM除了维护隐藏状态h(t)外,还维护另一个称为细胞状态(cell state)的记忆向量c(t)。此外,LSTM使用输入门i(t)、遗忘门f(t)、输出门o(t)显式地控制h(t)、c(t)的更新。三个门向量通过如下方法计算:
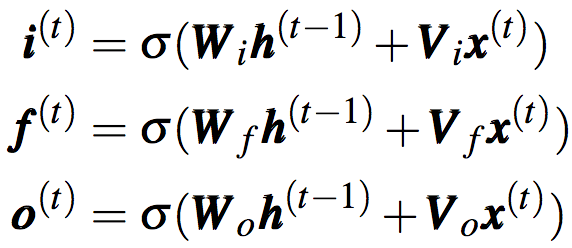
细胞状态和隐藏状态则通过如下方法计算:
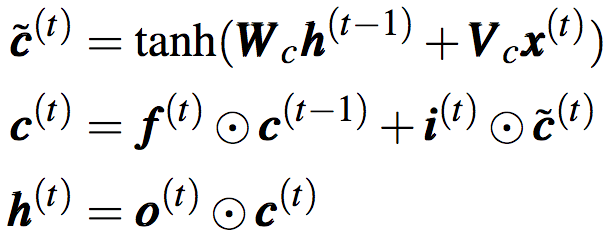
上面的第一个公式为候选细胞状态。
基于细胞状态和门向量,相比原始RNN,LSTM能维持更久的信息。
门控循环单元
相比LSTM,GRU要简单一点。GRU只使用隐藏状态向量h(t),和两个门向量,更新门z(t)、重置门r(t):

在更新隐藏状态之前,GRU会先使用重置门计算候选隐藏状态:
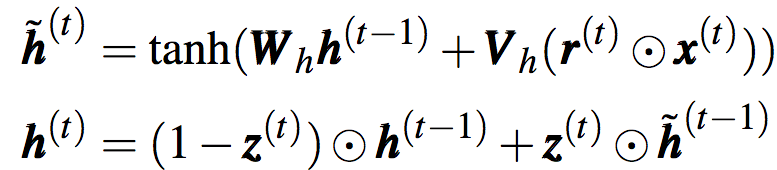
多层模型
为了增加表示能力,直接堆叠RNN网络可得到多层RNN模型:
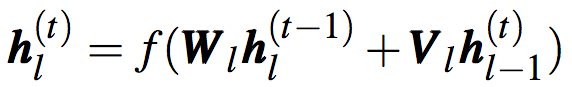
其中,h0(t) = x(t)
类似地,LSTM和GRU也可以通过堆叠得到多层模型。
协同聚类可视化二分图
还记得我们之前提到,对隐藏状态进行后续处理(例如softmax)可以输出分类的概率分布吗?
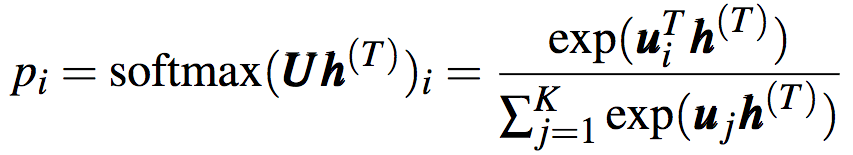
上式可以分解为乘积:
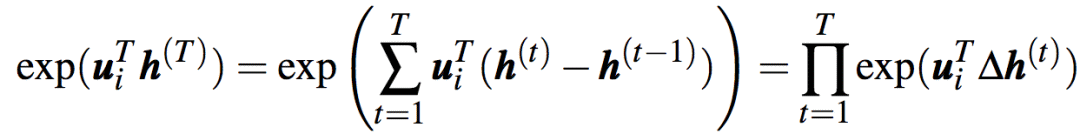
其中,∆h(t)可以解读为模型对输入单词t的反应。
相应地,模型对输入单词w的反应的期望可以通过下式计算:
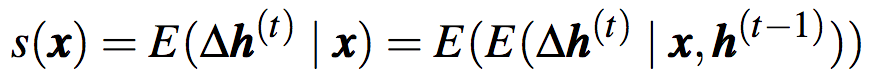
其中,x为单词w的嵌入向量,s(x)i表示hi和w之间的关系。s(x)i的绝对值较大,意味着x对hi较重要。基于足够的数据,我们可以据下式估计反应的期望:
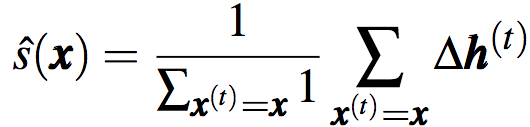
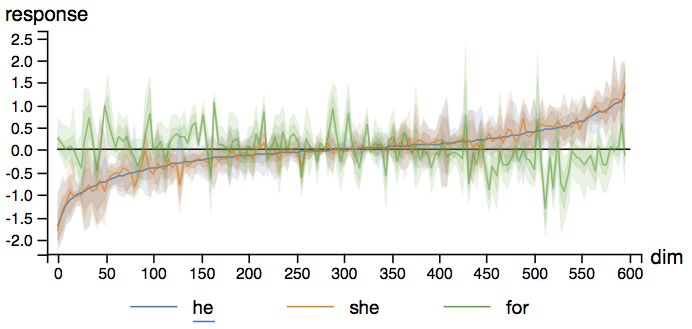
下图为一个双层LSTM对三个不同的单词的反应分布。该LSTM每层有600个细胞状态单元,基于Penn Tree Bank(PTB)数据集训练。我们可以看到,模型对介词(“for”)和代词(“he”、“she”)的反应模式大不相同。
基于前述期望反应,每个单词可以计算出n个隐藏单位的期望反应,同时,每个隐藏单元可以计算出对n个单词的期望反应。如果将单词和隐藏单元看作节点,这一多对多关系可以建模为二分图G = (Vw, Vh, E)。其中,Vw和Vh分别为单词和隐藏节点的集合。而E为加权边:
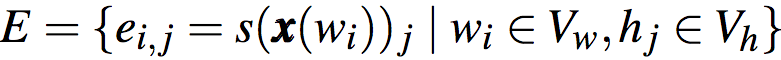
要可视化分析二分图,很自然地就想到使用协同聚类。

从上图我们可以看到,功能类似的单词倾向于聚类在一起。
RNNVis
以上述可视化分析技术为核心,论文作者构建了RNNVis可视化系统:
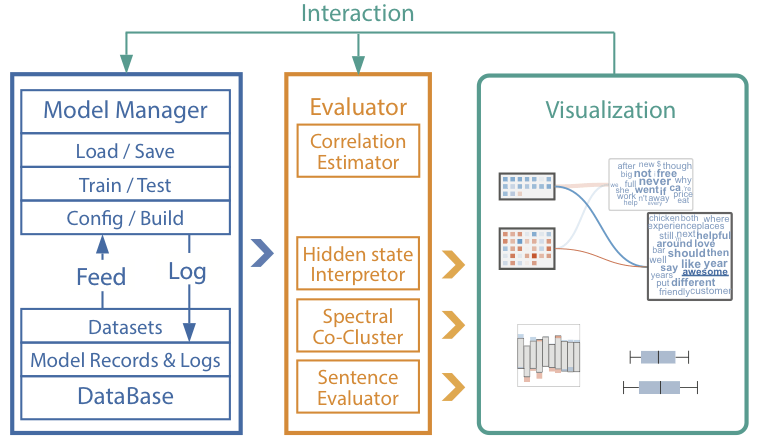
如上图所示,RNNVis包含3个主要模块:
模型管理器 使用TensorFlow框架构建、训练和测试RNN模型。用户可以通过编辑配置文件修改模型的架构。
RNN评估器 分析训练好的模型,提取隐藏状态中学习到的表示,并进一步处理评估结果以供可视化。同时,它也能够提供单词空间中每个隐藏状态的解释。
交互式可视化 用户可以在主界面点击单词或记忆单元,以查看详情。另外,用户也可以调整可视化风格。
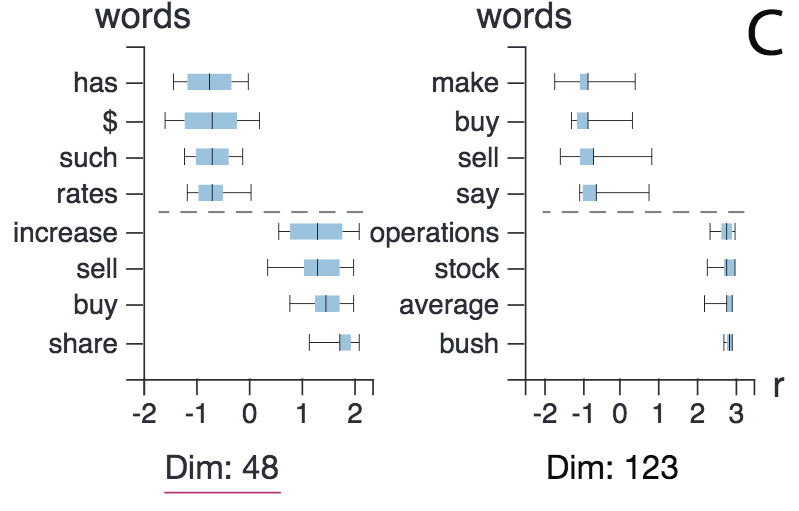
上图为详情页面。箱形图显示,第48维和第123维都捕捉到了像“buy”(“买”)和“sell”(“卖”)这样的动词,尽管两者的符号不同。另外,这一详情界面也表明,LSTM网络能够理解单词的语法功能。
比较不同模型
除了用于理解单个模型的隐藏记忆,RNNVis还可以用来比较两个模型:
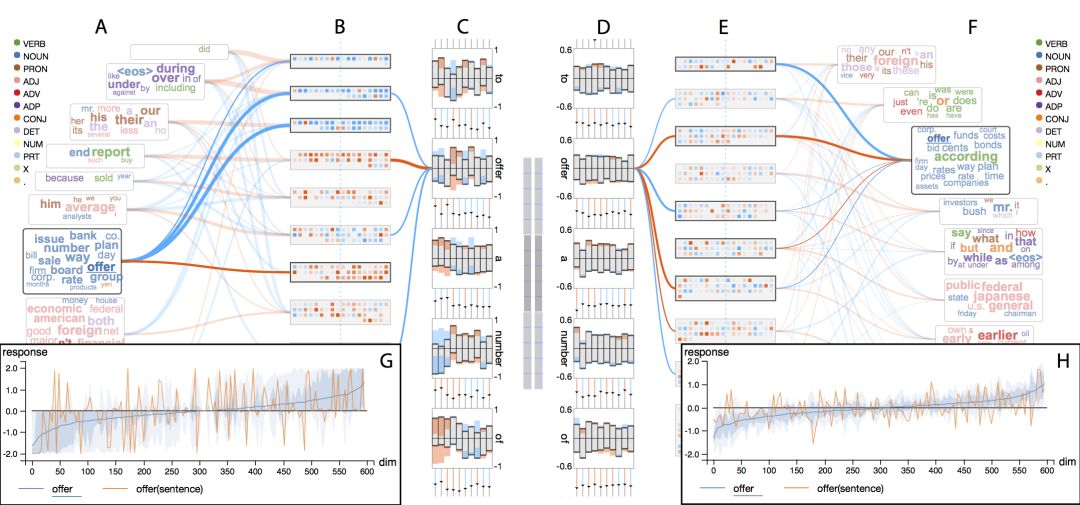
上图比较了原始RNN和LSTM。无论是记忆单元的饱和度(B和E),还是具体的响应历史(C和D),都反映了RNN比LSTM更密集地更新隐藏记忆。换句话说,LSTM对输入的反应更加稀疏。详情页面基于单个单词的比较也印证了这一点(G和H)。
LSTM相比RNN更“懒惰”,这可能是它在长期记忆方面胜过RNN的原因。
比较同一模型的不同层
除了用来比较不同模型,RNNVis还可以用来比较同一模型的不同层。
对CNN的可视化研究揭示了,CNN使用不同层捕捉图像中不同层次的结构。初始层捕捉较小的特征,例如边缘和角落,而接近输出的层学习识别更复杂的结构,以表达不同的分类。

图片来源:arXiv:1710.10777
而关于RNN及其变体不同层的作用,研究较少。一个自然的假想是初始层学习抽象表示,而后续层更多地学习特定任务的表示。
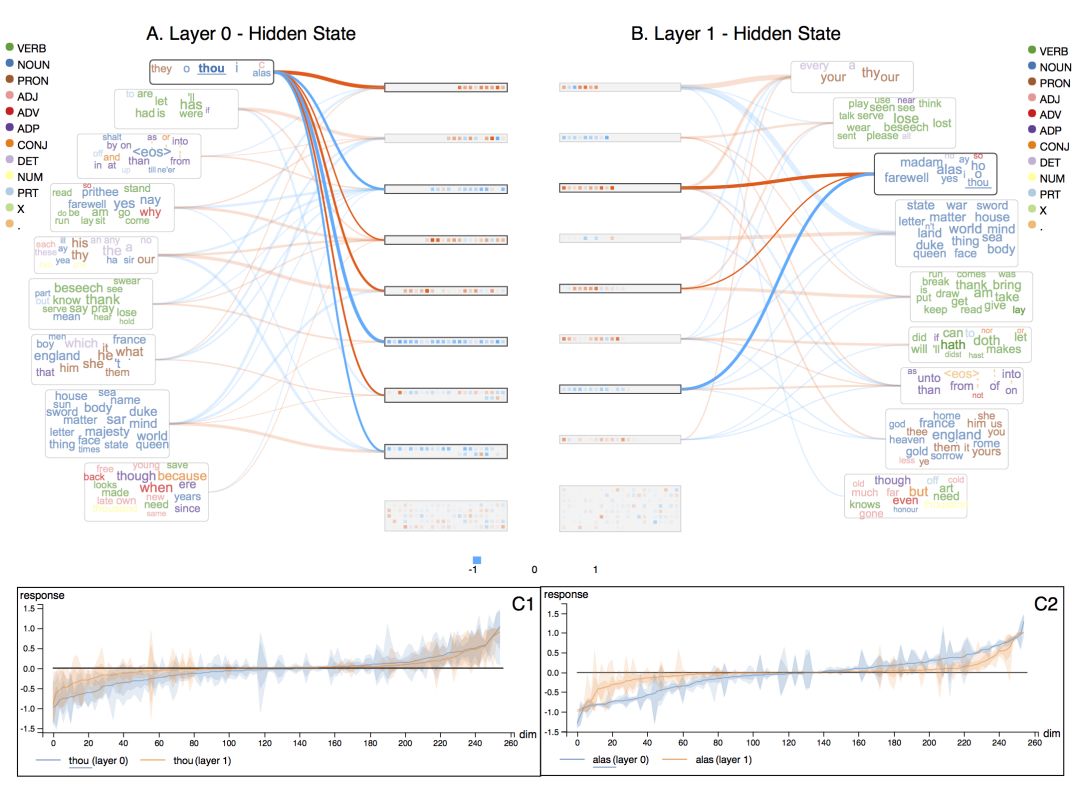
从上图我们可以看到,第0层的“记忆芯片”的尺寸比第1层更均匀。另一方面,第1层的单词云中单词的颜色更一致。也就是说,第1层的单词云的质量比第0层更高。这意味着第0层对不同单词的用法的把握更模糊,而第1层在识别不同功能的单词方面更聪明。
分别点击两层中的单词“thou”,我们可以看到,相比第0层(C1),第1层对单词“thou”的反应更稀疏(C2)。在其他单词上也有类似的现象。对于语言建模而言,这样的稀疏性有助于最后层,在最后层,输出通过softmax直接投影到一个巨大的单词空间(包含数千单词)。
如此,我们通过可视化印证了之前的假想,模型使用第一层构建抽象表示,使用最后一层表达更为任务相关的表示。
案例研究
论文作者通过两个案例试验了RNNVis的效果。
情感分析
论文作者使用的数据集是Yelp Data Challenge,该数据集包含四百万餐馆点评及评分(一分到五分)。评分正好可以视为点评的标签。为了简化问题,论文作者预处理了五个标签,将其归并为两个标签,其中,一分、二分映射为“消极”,四分、五分映射为“积极”,三分的点评不计在内。同样是为了简化问题,只使用了原数据集的一个子集,2万条长度小于100个单词的点评。然后按照80/10/10的百分比分割训练/验证/测试集。
所用网络为单层GRU,包含50个细胞状态,在验证集和测试集上分别达到了89.5%和88.6%的精确度。
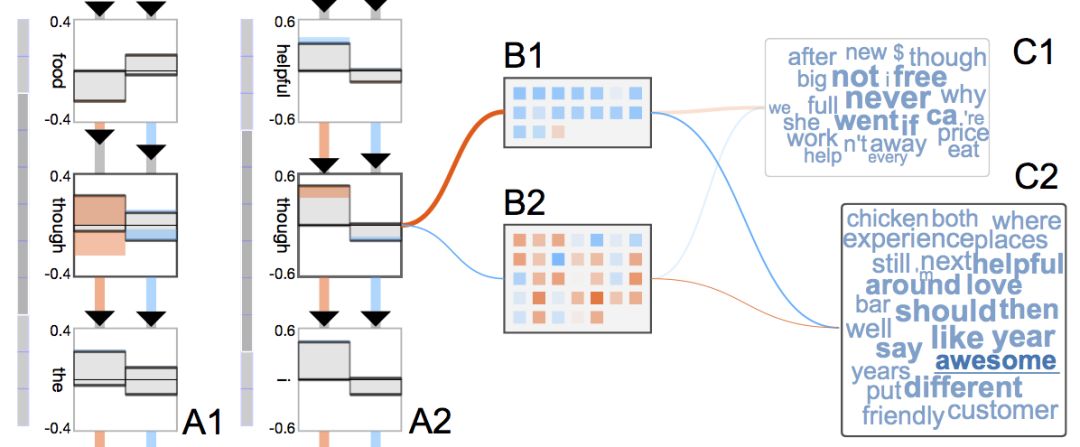
从上图的单词云可以看到,GRU可以理解单词的极性。上面的云包含“never”、“not”之类的消极单词,而下面的云包含“love”、“awesome”、“helpful”之类的积极单词。
另外,上图分析的是两个不同的转折句:
I love the food, though the staff is not helpful. (我喜欢食物,不过服务人员不热情。)
The staff is not helpful, though I love the food. (服务人员不热情,不过我喜欢食物。)
从上图可以看到,GRU对同一个单词“though”的反应不同,第一个句子中的“though”导致隐藏状态的更新更多,也就是说,GRU对消极情绪更敏感。
另一方面,数据集中许多消极单词,比如“bad”(“糟”)和“worst”(“最糟”)并没有出现在可视化之中。
这两点暗示GRU在积极点评和消极点评上的表现可能不一样。论文作者检查了数据集,发现数据集并不均衡,积极点评与消极点评的比例接近3:1。基于过采样技术,得到了均衡的数据集。在该数据集上重新训练的GRU模型,表现提升了,在验证集和测试集上分别达到了91.52%和91.91%的精确度。
可视化新模型后,单词云(C)包含更多情绪强烈的单词,比如消极单词云中的“rude”(粗鲁)、“worst”(最糟)、“bad”(糟),和积极单词云中的“excellent”(极好)、“delicious”(美味)、“great”(棒)。详情页面(A)显示,模型对“excellent”和“worst”具备完全相反的反应模式。
莎士比亚著作
论文作者使用莎士比亚的著作(包含一百万单词)构建了一个语言建模数据集(词汇量一万五千)。数据集按80/10/10百分比分为训练/验证/测试数据集。
研究人员使用小、中、大三个规模的LSTM网络。
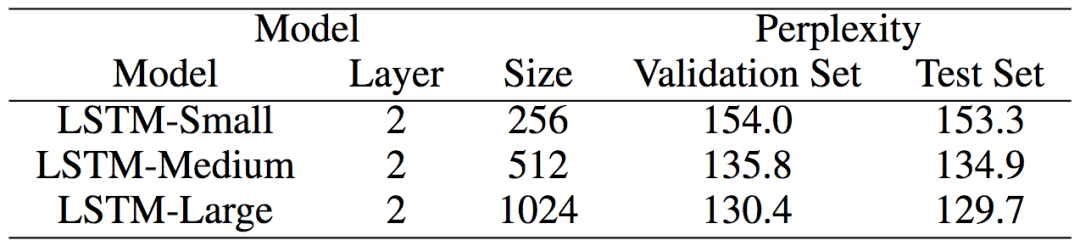
下面的评估和可视化结果属于中等规模的LSTM网络,不过,其他两个LSTM网络上的结果与此类似。
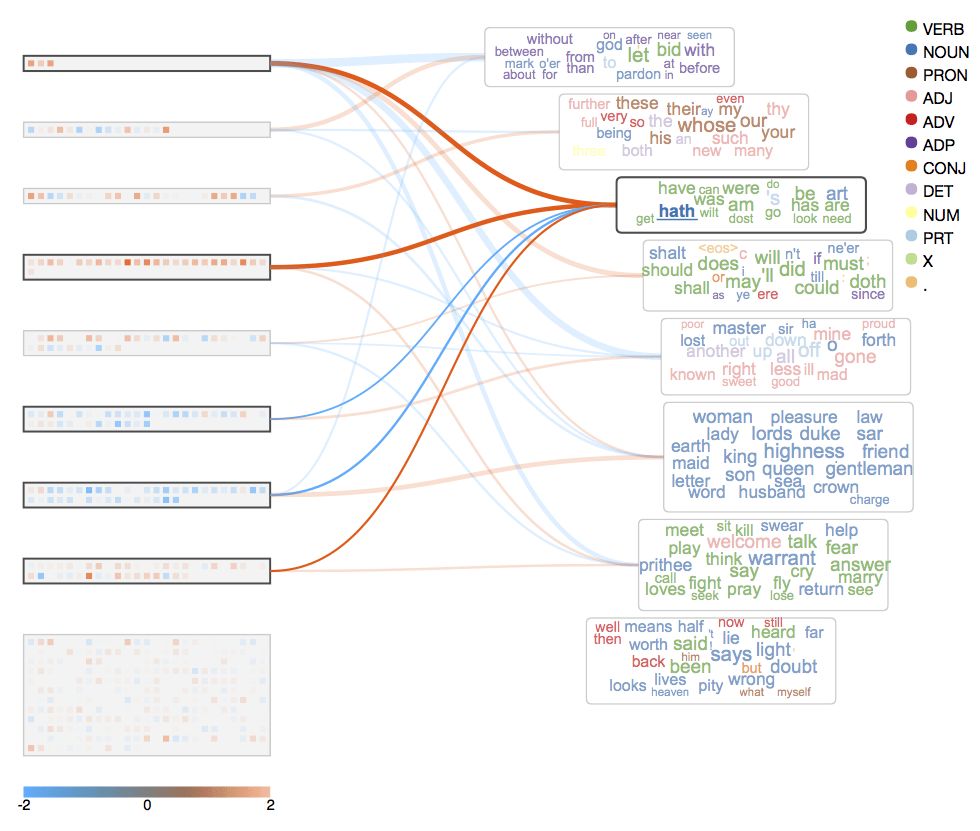
莎士比亚的语言混杂了新旧两个时期的英语。而从上图我们可以看到,“hath”、“dost”、“art”和“have”、“do”、“are”位于同一片单词云中。这说明,模型能够学习这些用途相似的助词,不管它们是来自古英语还是现代英语。详情界面印证了这一点,成对的新词和旧词具有相应的反应模式。

上图中有一个例外,是“thou”和“you”。这是因为在莎士比亚时期,“thou”和“you”的用法有细微的差别,“thou”为单数,常用于非正式场合,而“you”为复数,更正式、更礼貌。
以后的工作
论文作者计划部署一个RNNVis的线上版本,并增加更多RNN模型的量化指标以提升可用性。
由于可视化分析技术基于文本的离散输入空间,RNNVis只适用于分析用于文本的RNN系列模型。分析用于音频应用的RNN模型尚需构建可解释的表示。
当前RNNVis的瓶颈在于协同聚类的效率和质量,可能导致交互时的延迟。
另外,目前RNNVis还不能可视化一些特化的RNN变体,比如记忆网络(memory network)或注意力模型(attention model)。支持这些RNN变体需要对RNNVis进行扩展。
-
神经网络中最经典的RNN模型介绍2021-05-10 12163
-
FPGA也能做RNN2018-07-31 0
-
放弃 RNN 和 LSTM 吧,它们真的不好用2018-04-25 20591
-
循环神经网络(RNN)和(LSTM)初学者指南2019-02-05 948
-
一种具有强记忆力的 E3D-LSTM网络,强化了LSTM的长时记忆能力2019-09-01 11038
-
循环神经网络LSTM为何如此有效?2021-03-19 2857
-
深度分析RNN的模型结构,优缺点以及RNN模型的几种应用2021-05-13 24310
-
RNN以及LSTM2022-03-15 1890
-
GRU是什么?GRU模型如何让你的神经网络更聪明 掌握时间 掌握未来2024-06-13 1754
-
如何理解RNN与LSTM神经网络2024-07-09 651
-
使用LSTM神经网络处理自然语言处理任务2024-11-13 399
-
LSTM神经网络的优缺点分析2024-11-13 1385
-
LSTM神经网络与传统RNN的区别2024-11-13 341
-
RNN与LSTM模型的比较分析2024-11-15 490
全部0条评论

快来发表一下你的评论吧 !
