

一种思考数学表达式的轻松方法——计算图
电子说
描述
编者按:反向传播是一种训练人工神经网络的常见方法,它能简化深度模型在计算上的处理方式,是初学者必须熟练掌握的一种关键算法。对于现代神经网络,通过反向传播,我们能配合梯度下降大幅提高模型的训练速度,在一周时间内就完成以往研究人员可能要耗费两万年才能完成的模型。
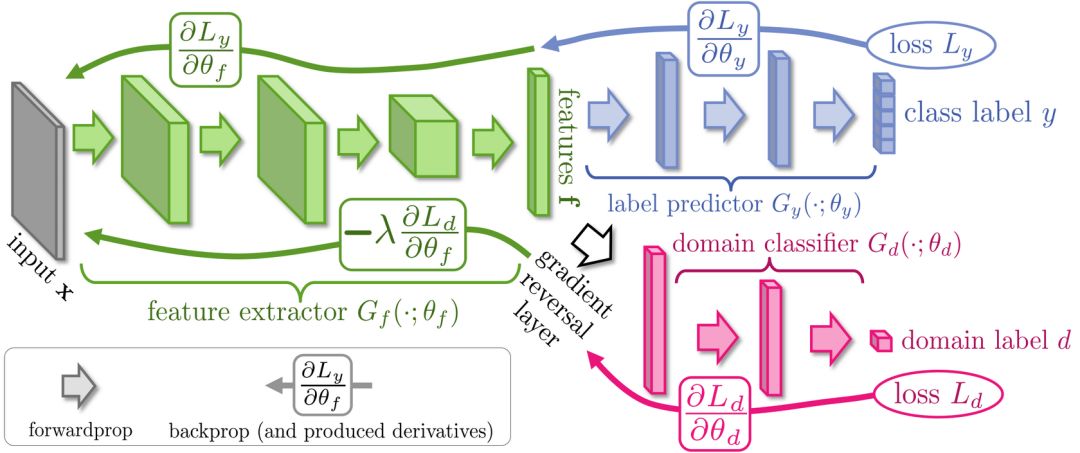
除了深度学习,反向传播算法在许多其他领域也是一个强大的计算工具,从天气预报到分析数值稳定性——区别只在于名称差异。事实上,这种算法在几十个不同的领域都有成熟应用,无数研究人员都为这种“反向模式求导”的形式着迷。
从根本上说,无论是深度学习还是其他数值计算环境,这是一种方便快速计算的方法,也是一个必不可少的计算窍门。
计算图
谈及计算,有人可能又要为烦人的计算公式头疼了,所以本文用了一种思考数学表达式的轻松方法——计算图。以非常简单的e=(a+b)×(b+1)为例,从计算角度看它一共有3步操作:两次求和和一次乘积。为了让大家对计算图有更清晰的理解,这里我们把它分开计算,并绘制图像。
我们可以把这个等式分成3个函数:
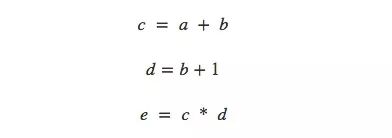
在计算图中,我们把每个函数连同输入变量一起放进节点中。如果当前节点是另一个节点的输入,用带剪头的线表示数据流向:
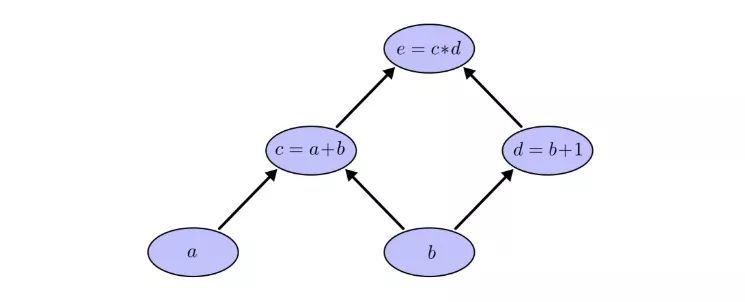
这其实是计算机科学中的一种常见描述方法,尤其是在讨论涉及函数的程序时,它非常有用。此外,现在流行的大多数深度学习开源框架,比如TensorFlow、Caffe、CNTK、Theano等,都采用了计算图。
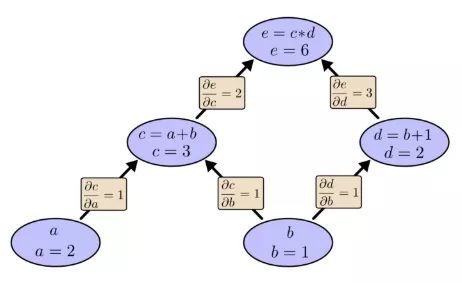
仍以之前的例子为例,在计算图中,我们可以通过设置输入变量为特定值来计算表达式。如,我们设a=2,b=1:
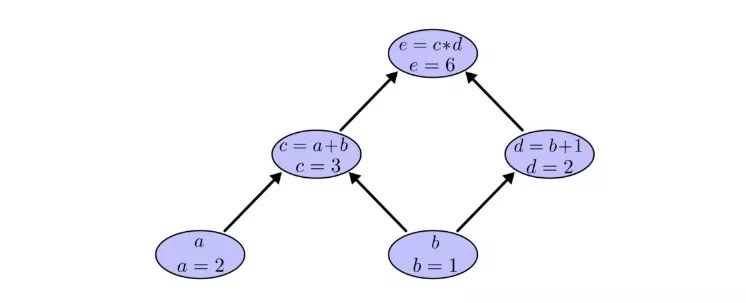
可以得到e=(a+b)×(b+1)=6。
计算图上的导数
如果要理解计算图上的导数,一个关键在于我们如何理解每一条带箭头的线(下称“边”)上的导数。以之前的连接a节点和c=a+b节点的边为例,如果a对c有影响,那这是个怎么样的影响?如果a变化了,c会怎么变化?我们称这为c关于a的偏导数。
为了计算图中的偏导数,我们先来复习这两个求和规则和乘积规则:
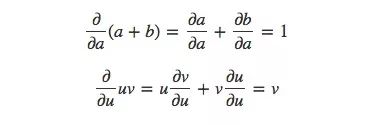
已知a=2,b=1,那么相应的计算图就是:
现在我们计算出了相邻两个节点的偏导数,如果我想知道不直接相连的节点是如何相互影响的,你会怎么办?如果我们以速率为1的速度变化输入a,那么根据偏导数可知,函数c的变化速率也是1,已知e相对于c的偏导数是2,那么同样的,e相对a的变化速率也是2。
计算不直接相连节点之间偏导数的一般规则是计算各路径偏导数的和,而同一路径偏导数则是各边偏导数的乘积,例如,e关于b的偏导数就等于:
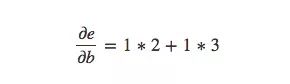
上式表示了b是如何通过影响函数c和d来影响函数e的。
像这种一般的“路径求和”规则只是对多元链式规则的不同思考方式。
路径分解
“路径求和”的问题在于,如果我们只是简单粗暴地计算每条可能路径的偏导数,我们很可能会最后得到一个“爆炸”的和。
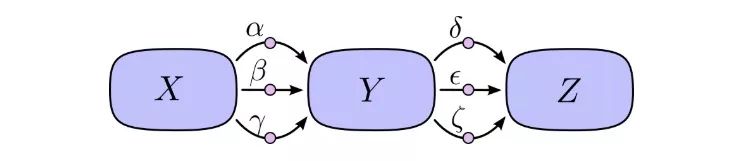
如上图所示,X到Y有3条路径,Y到Z也有3条路径,如果要计算∂Z/∂X,我们要计算的是3×3=9条路径的偏导数的和:
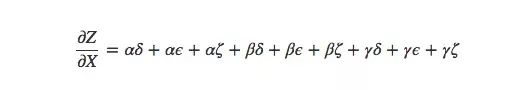
这还只是9条,随着模型变得越来越复杂,相应的计算复杂度也会呈指数级上升。因此比起傻乎乎地一个个求和,我们最好能记起一些小学数学知识,然后把上式转为:
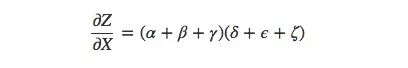
是不是很眼熟?这就是前向传播算法和反向传播算法中最基础的一个偏导数等式。通过分解路径,这个式子能更高效地计算总和,虽然长得和求和等式有一定差异,但对于每条边它确实只计算了一次。
前向模式求导从计算图的输入开始,到最后结束。在每个节点上,它汇总了所有输入的路径,每条路径代表输入影响该节点的一种方式。相加后,我们就能得到输入对最终结果的总的影响,也就是偏导数。
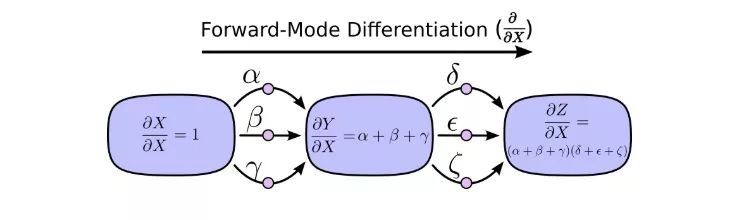
虽然你以前可能没想过从计算图的角度来进行理解,但这样一看,其实前向模式求导和我们刚开始学微积分时接触的内容差不多。
另一方面,反向模式求导则是从计算图的最后开始,到输入结束。对于每个节点,它做的是合并所有源自该节点的路径。
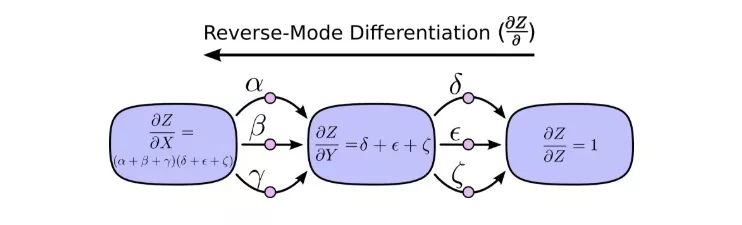
前向模式求导关注的是一个输入如何影响每个节点,反向模式求导关注的是每个节点如何影响最后那一个输出。换句话说,就是前向模式求导是在把∂/∂X塞进每个节点,反向模式求导是在把∂Z/∂塞进每个节点。
大功告成
说到现在,你可能会想知道反向模式求导究竟有什么意义。它看起来就是前向模式求导的一个奇怪翻版,其中会有什么优势吗?
让我们从之前的那张计算图开始:

我们先用前向模式求导计算输入b对各个节点的影响:
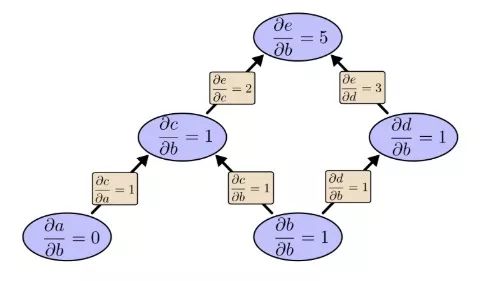
∂e/∂b=5。我们把这个放一边,再来看看反向模式求导的情况:
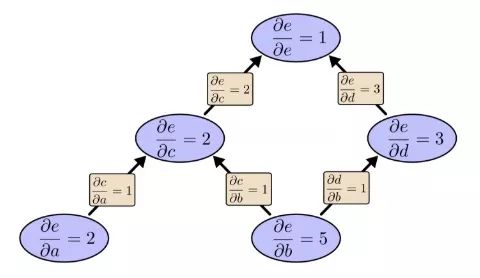
之前我们说反向模式求导关注的是每个节点如何影响最后那个输出,根据上图可以发现,图中偏导数既有∂e/∂b的,也有∂e/∂a的。这是因为这个模型有两个输入,而它们都对输出e产生了影响。也就是说,反向模式求导更能反映全局输入情况。
如果说这是一个只有两个输入的简单例子,两种方法都无所谓,那么请想象一个有一百万个输入、只有一个输出的模型。像这样的模型,我们用前向模式求导要算一百万次,用反向模式求导只要算1次,这就高下立判了!
在训练神经网络时,我们把cost(描述网络表现好坏的值)视作一个包含各类参数(描述网络行为方式的数字)的函数。为了提升模型性能,我们要不断改变参数对cost函数求导,以此进行梯度下降。模型的参数千千万,但它的输出只有一个,因此机器学习对于反向模式求导,也就是反向传播算法来说是个再适合不过的应用领域。
那有没有一种情况下,前向模式求导能比反向模式求导更好?有的!我们到现在谈的都是多输入单输出的情形,这时反向更好;如果是一输入多输出、多输入多输出,前向模式求导速度更快!
这不是太普通了吗?
当我第一次真正理解反向传播算法时,我的反应是:哦,就是最简单的链式法则!我怎么花了这么久才明白?事实上我也不是唯一出现这种反应的人,的确,如果问题是你能从前向模式求导中推出那种更聪明的计算方法,这就没那么麻烦了。
但我认为这比看起来要困难得多。在反向传播算法刚发明的时候,人们其实并没有十分关注前馈神经网络的研究。所以也没人发现它的衍生品有利于快速计算。但当大家都知道这种衍生品的好处后,他们又开始反应过来:原来它们有这样的关系!这之中有一个恶性循环。
更糟糕的是,在脑子里推一推算法的衍生工具是很普遍的,一旦涉及用它们训练神经网络,这几乎就等同于洪水猛兽。你肯定会陷入局部最小值!你可能会浪费巨大的计算成本!人们只有在确认这种方法有效后,才会乖乖闭嘴去实践。
小结
衍生工具比你想象中的更易于挖掘,也更好用,我希望这是本文为你带来的主要经验。虽然事实上这个挖掘过程并不容易,但在深度学习中领会这一点很重要,换一个角度,我们就能发现不同的风景。同样的话也适用于其他领域。
还有其他经验吗?我认为有。
反向传播算法也是了解数据流经模型过程的有利“镜头”,我们能用它知道为什么有些模型会难以优化,如经典的递归神经网络中梯度消失的问题。
最后,读者可以尝试同时结合前向传播和反向传播两种算法来进行更有效的计算。如果你真的理解了这两种算法的技巧,你会发现其中会有不少有趣的衍生表达式。
-
Java Lambda表达式的新特性2023-09-30 3377
-
什么是正则表达式?正则表达式如何工作?哪些语法规则适用正则表达式?2023-11-03 6224
-
如何从一个简单的数学表达式创建一个Saber模型?2023-12-05 1574
-
【LabVIEW懒人系列教程-小白入门】1.7LabVIEW数据操作之表达式2020-07-29 2413
-
基因表达式编程的2种解码方法2009-04-10 674
-
深入浅出boost正则表达式2010-09-08 552
-
一种面向数学检索的LaTeX数学表达式解析与索引方法2017-12-22 1049
-
Python正则表达式指南2021-03-26 1019
-
基于运算符信息的数学表达式检索技术2021-04-29 977
-
Lambda表达式详解2023-02-09 2129
-
表达式与逻辑门之间的关系2023-02-15 2932
-
C语言的表达式2023-02-21 2794
-
一文详解Verilog表达式2023-05-29 4070
-
zabbix触发器表达式 基本RS触发器表达式 rs触发器的逻辑表达式2023-08-24 2575
-
怎么去选择使用gm的三种表达式呢?2023-09-17 17915
全部0条评论

快来发表一下你的评论吧 !
