

从 0 到 1:用 PHP 爬虫优雅地拿下京东商品详情
电子说
描述
在电商数据驱动的时代,商品详情数据成为市场分析、价格监控、竞品调研的核心燃料。京东作为国内头部电商平台,其商品信息丰富、更新频繁,是数据开发者眼中的“香饽饽”。
本文将带你从 0 到 1,用PHP 语言实现一个可运行的京东商品爬虫,不仅能抓取商品标题、价格、图片、评价数,还能应对常见的反爬策略。全文附完整代码,复制粘贴即可运行。
一、为什么选择 PHP 做爬虫?
虽然 Python 是爬虫界的“老大哥”,但 PHP 在 Web 开发领域依旧占据主流,具备以下优势:
语法简单:Web 开发者一键切换;
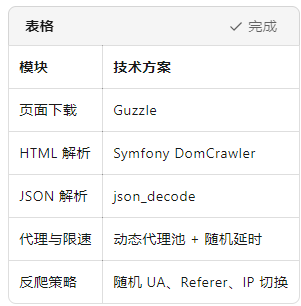
库生态丰富:Guzzle、Symfony DomCrawler、Simple HTML DOM、Swoole;
部署方便:直接 fpm 或 CLI,无需额外环境;
与业务无缝集成:爬完直接 Laravel 入库、队列、通知;
并发能力强:Swoole 协程轻松 10k QPS。
一句话:如果你本来就在写 Laravel,用 PHP 写爬虫等于「顺路」。
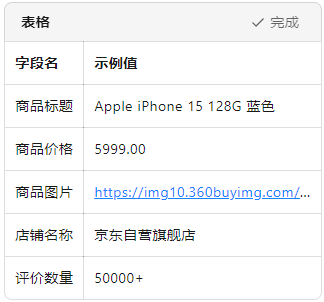
二、目标明确:我们要抓什么?
以京东商品详情页为例,我们要抓取以下字段:
三、技术选型
四、环境准备
1. 创建项目
bash
mkdir jd-php-crawler && cd jd-php-crawler composer init --name="demo/jd-crawler" -s dev
2. 安装依赖
bash
composer require guzzlehttp/guzzle symfony/dom-crawler symfony/css-selector fakerphp/faker
五、核心代码实现
1. 创建爬虫类
php
< ?php
// src/JdSpider.php
namespace Demo;
use GuzzleHttpClient;
use SymfonyComponentDomCrawlerCrawler;
class JdSpider
{
private Client $client;
public function __construct()
{
$this- >client = new Client([
'timeout' = > 10,
'headers' = > [
'User-Agent' = > 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer' = > 'https://search.jd.com/',
],
]);
}
public function fetchProduct(string $sku): array
{
// 1. 详情页
$url = "https://item.jd.com/{$sku}.html";
$html = $this- >client- >get($url)- >getBody()- >getContents();
$crawler = new Crawler($html);
$title = $crawler- >filter('div.sku-name')- >text('');
$shop = $crawler- >filter('div.J-hove-wrap .name')- >text('');
$img = $crawler- >filter('img#spec-img')- >attr('src');
if (str_starts_with($img, '//')) {
$img = 'https:' . $img;
}
// 2. 价格
$priceUrl = "https://p.3.cn/prices/mgets?skuIds=J_{$sku}";
$priceJson = json_decode($this- >client- >get($priceUrl)- >getBody(), true);
$price = $priceJson[0]['p'] ?? '0';
// 3. 评价数
$cmtUrl = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds={$sku}";
$cmtJson = json_decode($this- >client- >get($cmtUrl)- >getBody(), true);
$commentCount = $cmtJson['CommentsCount'][0]['CommentCount'] ?? 0;
return [
'sku' = > $sku,
'title' = > trim($title),
'price' = > $price,
'comment_count' = > $commentCount,
'shop' = > trim($shop),
'img' = > $img,
'crawled_at' = > date('Y-m-d H:i:s'),
];
}
}
2. 创建入口文件
php
#!/usr/bin/env php < ?php require __DIR__ . '/vendor/autoload.php'; use DemoJdSpider; $sku = $argv[1] ?? '100035288046'; $spider = new JdSpider(); $data = $spider- >fetchProduct($sku); echo json_encode($data, JSON_UNESCAPED_UNICODE | JSON_PRETTY_PRINT);
3. 运行脚本
bash
php bin/jd.php 100035288046
4. 运行结果示例
JSON
{
"sku": "100035288046",
"title": "Apple iPhone 15 128GB 蓝色",
"price": "5999.00",
"comment_count": 50000,
"shop": "京东自营旗舰店",
"img": "https://img10.360buyimg.com/n1/s450x450_jfs/t1/123456.jpg",
"crawled_at": "2025-09-23 14:30:00"
}
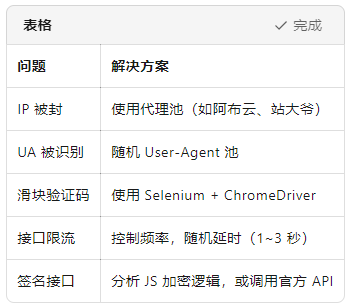
六、反爬策略与优化建议
七、进阶玩法(等你来挑战)
✅ 多进程抓取 + 队列调度(支持百万 SKU)
✅ 接入 Laravel,实时入库
✅ 接入 Elasticsearch,实现商品搜索
✅ 接入 Kafka,实时流式处理
✅ 可视化展示:Laravel + Vue + ECharts
八、合法合规提醒
✅ 禁止抓取用户隐私信息(如收货地址、手机号)
✅ 禁止高并发攻击京东服务器
✅ 对外商用需获得京东授权
✅ 建议优先使用官方 API(open.jd.com)
九、结语
本文从环境搭建、代码实现、反爬策略到进阶方向,系统讲解了如何用PHP 爬虫获取京东商品详情。希望你不仅能跑通代码,更能在此基础上构建自己的数据采集系统。
审核编辑 黄宇
-
0基础入门Python爬虫实战课2021-07-25 2464
-
python爬虫实战:京东图片爬虫2022-04-25 2072
-
如何利用京东商品详情id拿到商品的详细信息 示例展示2025-07-10 2009
-
API实战指南:如何高效采集京东商品详情数据?这几个接口必须掌握!2025-10-13 729
-
京东商品详情 ID(即 SKU ID)获取商品详细信息参数2025-11-11 1600
-
# 深度解析:爬虫技术获取淘宝商品详情并封装为API的全流程应用2025-11-17 600
-
京东商品详情价格监控API完整教程2025-11-24 1326
-
京东关键词搜索商品列表的Python爬虫实战2026-01-04 1729
-
京东商品详情API接口指南2026-01-14 640
-
得物商品详情API2026-01-27 989
-
京东商品详情API接口详解:获取商品标题、价格、库存等核心数据2026-03-02 843
-
如何通过API获取京东商品的券后价格详情2026-03-04 768
-
京东商品详情API接口实操指南2026-03-10 1116
-
电商效率翻倍:用 OpenClaw 对接京东详情接口,一键抓取商品全量信息2026-04-22 279
-
京东商品详情 API 实战总结(技术复盘)2026-05-25 197
全部0条评论

快来发表一下你的评论吧 !
