

如何设计机器人处理器?
电子说
描述
机器人是否需要专用的芯片支持?要想开发机器人芯片,首先必须弄清楚是否有这方面的需求。一方面,尽管今天能实用的机器人数量还比较少,但在可预期的未来,很多人相信会诞生一批经济适用、量大面广的现象级产品,就像无人机、无人车一样,由于其功能的丰富,其总数量甚至会达到百亿级,超过个人电脑、手机的数量。如此庞大的应用空间,按照过去计算机的发展经验,必然伴生孕育着新型计算系统,所以未来机器人系统需要芯片这一点比较肯定。接着,另外一个问题,是否需要设计专用芯片?今天现行的如CPU、DSP、GPU、神经网络或他们的组合是否就够用了?这个问题还需要从机器人的功能角度出发去分析。一方面,我们会赋予机器人更多的智能能力,使他能够听说看甚至决策;另一方面,机器人也将具有越来越强运动能力。而这些都是现行芯片所解决不好的,我们认为今天机器人无法大规模普及,和他们的能力不足直接相关,而这种能力除了算法方面的改进外,性能的大幅提升也是必要的。因此,我们认为需要设计面向机器人的专用芯片,以解决机器人在应用中的若干问题,为未来机器人的大发展提供硬件基础。
现行机器人的计算系统
当前已存在着很多不同种类的机器人,这些机器人均已集成了不同类型的计算系统。在传统工业控制系统中,可编程逻辑控制器(PLC)使用较广,但在服务类机器人中,更多基于嵌入式通用处理器,以方便集成计算机软件以及智能算法上的进步。本文以商业上应用较多的情感机器人、工业机器人和移动服务机器人为例,介绍这些机器人载体中所使用的计算系统,其他如军事机器人、太空机器人、特种机器人在底层计算系统上有类似之处,就不一一介绍:
情感机器人:情感机器人主要功能是和人进行语音和视觉上的交流,是目前较为常见的一类机器人,这类机器人通常具有较强的语音和视觉处理能力,但运动能力较弱。为了快速开发,情感机器人通常使用主流嵌入式芯片提供计算能力,如ARM、Intel ATOM处理器等。当然,对情感机器人而言,还需要具有联网功能,通过云计算模式提供语音交互、问题回答等功能。
工业机器人:工业机器人和情感机器人不同,这一类机器人通常限制在特定应用场景,和人交互不多,它们对对语音和视觉处理能力要求不高,但往往需要较强的实时运动控制功能,以完成特定任务。在工业机器人中,可编程逻辑控制器(PLC)使用较多,PLC是一种微处理器化的控制器,输出侧重于对电机等动力设备进行控制的模拟信号。PLC计算内核一般为单片机,51、PIC、AVR等单片机都有用于PLC中。PLC对单片机进行了二次开发,在稳定性和编程语言(使用电气工程师所熟悉的梯形图语言)等方面进行了优化。
移动服务机器人:常见的如扫地机器人、无人机、无人驾驶等,以完成特点服务功能,这类机器人的特点是应用场景复杂多变,运动能力强。需要具备自我定位导航能力和姿态控制能力。其背后使用的计算平台和移动速度以及应用场景密切相关。速度较慢,硬件平台使用嵌入式ARM芯片就可满足计算能力需求。移动速度较快的,如无人机和无人驾驶领域,往往对环境感知处理要求也比较高,目前通常基于GPU提供算力支持。 由于快速移动机器人对计算能力需求较大,这一领域一个趋势是专用ASIC芯片,如辅助驾驶Mobileye。最近,特斯拉也有相关专用芯片设计的计划,国内也有创业公司如地平线正在开展这方面工作。
云化的计算能力是未来机器人计算系统的一个发展方向。云端引擎具有三个主要好处:(1)能提供更强大的计算能力,接入云端的机器人自身不再需要装自带繁重的计算装备;(2)能提供大数据存储和分析能力,使机器人可以非常迅速地分享从大数据中挖掘出的规律和知识;(3)能提供多机协同能力。欧盟和美国在这方面部署了一些很有意思的研究工作。欧盟在2011年开展了RoboEarth研究项目,帮助机器人建立自己的互联网和知识库,为机器人提供一个巨大的网络和数据库来帮助其共享信息,并互相学习各自的行为、技能和环境,以达到一种经验共享、互相学习的理想状态。美国斯坦福大学等高校开展的RoboBrain项目,旨在建立一种新的、主要面向机器人的同时能供任何要执行的设备自由访问的大规模知识引擎,相当于建立一套面向机器人的搜索引擎。
另一方面,树莓派、Arduino等快速开发板,由于其极强的易开发性和接口丰富性,在一些较低计算量需求的控制场景也有应用。Intel中国研究院研发了基于FPGA的HERO机器人开发平台,开发者可以根据应用自己决定和设计逻辑。
智能机器人芯片的主要负载总结
芯片的设计取决于负载的特点。要想设计面向特定领域的芯片,首先要清楚芯片上运行的主要负载特点。智能机器人和传统计算机不太一样,除了需要较强的智能计算外,还需要较强的感知交互能力、姿态控制能力、运动能力等:
感知交互负载:机器人的感知信息往往是多通道的,包含语音、视觉、触觉、嗅觉等。感知信息的处理分为初级处理和智能处理两大类。初级处理主要是对传感器数据进行降噪、筛选等,主要用的算法核心包含傅里叶分析、小波变换等,智能处理主要是采用机器学习算法。交互则更多涉及语音、图像合成等几何计算算法以及深度神经网络处理。
姿态控制负载:在一些立体移动机器人系统中,需要有较强的姿态控制功能。以多轴无人机为例,主要算法包含:对姿态传感器进行去噪及融合的滤波算法,互补滤波和卡尔曼滤波用得较多;姿态算法,主要是根据滤波后的传感器信息计算出自身在地理空间坐标系中的三维位置,姿态平衡算法,一般采用PID(比例-积分-微分)算法进行反馈调节。算法的核心操作可以抽象为矩阵计算等。
移动导航负载:SLAM(同步定位导航)算法是机器人自主导航中使用较多的一类算法,根据前端传感器的不同,又可主要分为激光SLAM和视觉SLAM, SLAM通常可分为前端预处理、匹配、地图融合等三个大步骤。预处理主要是对激光、深度传感器等数据进行优化,主要算法包含滤波算法等;匹配是将局部环境数据匹配到已经建立的地图位置上,主要算法包含ICP(迭代最近点)、图优化Bundle Adjustment计算等;地图融合就是将新数据拼接到原始地图中完成更新,主要算法有Bag-of-Words(BOW) loop closure(回环)检测等。尽管有很多步骤,SLAM算法的核心操作主要还是集中在图形计算方面。
关节运动控制负载:机器人运动学是机器人运动控制的基础,包含正运动学和逆运动学。正运动学是给定每个关节变量(角度或长度),求解机器人的位姿;逆运动学,即给定机器人的位姿,求解机器人各个关节的关节变量。正逆运动学求解,核心操作是矩阵计算,但由于规模大,对于高自由度机器人情况更糟。逆运动学方程求解过程比较特殊,使用GPU并不是特别高效。
控制决策负载:机器人控制决策有两大类方法:基于专家系统和基于新型机器学习方法。强化学习方法由于考虑了与外界的交互作为系统优化指标,非常适合于机器人的控制决策中。在人机围棋大战中,Google的AlphaGo和AlphaZero就是采用了这一算法。在这一类负载中,核心操作主要是神经网络。
除了上述这些主要负载需求以外,机器人芯片还有些特别的需求,比如要求更高的安全性和可靠性。
我们在智能机器人芯片设计上的一些探索
中科院计算所从2015年开始研制面向智能机器人的芯片,进行了一些初步探索,总体目标是希望能为未来具有为丰富功能和更强智能能力的机器人提供通用高性能计算平台,下面就介绍我们在这方面取得的一些成果。
基于机器人负载特征的分析结论,我们设计了一个取名为Dadu的机器人智能处理器平台。这个名字最初来源于我们能支持大自由度的机器人,后来结合智能计算方面的扩展,形成了双核结构:一个智能核和一个运动核。智能核为一个低功耗神经网络处理器,其主要功能是加速视音频感知交互负载和基于神经网络的控制决策负载;运动核主要是一个高速的运动方程求解加速器和一些向量计算部件,其主要功能是加速逆运动方程求解和姿态控制及移动导航负载中用到的几何图形处理。
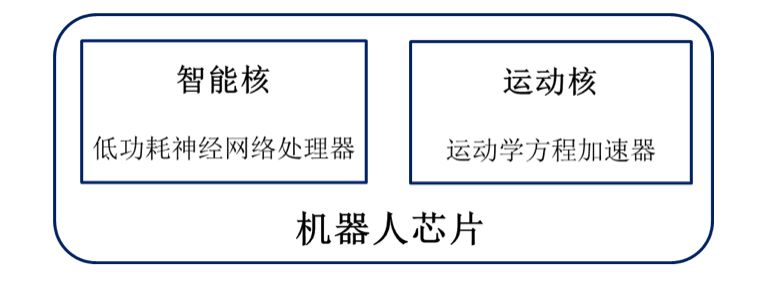
图1. Dadu智能机器人芯片
智能核
神经网络处理器是当前芯片领域的一个研究热点,商业上也已经有一些较为成熟的方案,如寒武纪的DianNao系列、Google的TPU系列、Intel的Movidius等。为了高效处理神经网络中大量的张量操作,处理器通常设计为脉动阵列结构、2D PE阵列结构和乘加树等结构。但由于神经网络拓扑结构创新活跃,新结构层出不穷,不同网络、不同层之间计算组织形式差异很大。当前,通用神经网络处理器设计存在较为严重的“利用率墙”的问题,也即:由于固定的硬件结构和新的神经网络数据流的不吻合,导致通用神经网络处理器的内部计算资源利用率低的问题,比如Google的TPU,在运行AlphaGo时,整个PE的利用率为46.2%,运行LSTM网络模型时,PE利用率更低,只有8.2%。
和TPU等定位不同,面向机器人的神经网络处理器设计更侧重于嵌入式、低功耗特性。提高并行效率,是打破利用率墙的重要手段,也是提高实际能效比的关键技术。我们在这方面做出了一些探索。
发表于2017年体系结构领域会议HPCA上的论文[1],我们首先从特征图(feature map)、神经元(Neuro)、神经突触(Synaps) 三个层次研究了并行化的方法,并进而提出了神经网络计算并行化划分的八种方法: SFSNSS(单特征图、单神经元、单神经突触)、SFMNSS、SFSNMS、SFMNMS、MFSNSS、MFSNMS、MFMNSS、MFMNMS。在此基础上,我们提出了一种强灵活性的硬件数据流架构(FlexFlow),它的主要原理是其同时支持多种并行方式,利用多种并行方式的互补效应来弥补单一并行方式的不足,从而实现了卷积神经网络的高效计算。
图2. Flexflow 结构
神经网络计算中的卷积操作和数据通常是按照卷积核粒度去组织的,不同神经网络、不同层的卷积核大小不一样,会导致利用率和数据复用有较大变化。存在两种数据级并行:卷积核内并行和卷积核间并行。卷积核内并行,是将属于相同卷积核位置但是不同输入图层的n个像素同时进行卷积运算。每个操作将若干个数据权重对加载到PE,在整个卷积核窗口(k×k)重复这个操作,最后累加这些运算结果得到和数。卷积核内并行,是将同一个输入图层中的一个或几个卷积核k×k窗口传送到PE并行计算。对于深度卷积神经网络的大部分层的图层数量都很多,采用卷积核间并行方式,PE 的利用率很高。但是,在神经网络的前几层层,输入图层数量较少,卷积核比较大,卷积步长一般远小于卷积核大小,从硬件利用率角度它们显然更适合于通过卷积核内并行化来加速。
我们提出了一种 C-Brain结构[2],通过自适应的卷积核并行,可根据配置,选择合适的卷积核并行方法,在硬件上有效支持前几层的核内并行,和后续层的核间并行,综合利用并行优势,有效提高了计算部件的利用率。同时采用“卷积核分割”的并行方法,使卷积核内并行方案易于将数据映射到硬件上,进一步提高了PE的利用率。
2. 运动核
机器人需要通过关节控制实现类似于人类肢体的一些功能,如移动、行走和抓取等等。在机器人学中,每个关节提供一个自由度。一般来讲,机器人的自由度越多(关节越多),机器人功能就越强大,运动就越灵活。工业机械臂一般只有6-7个自由度,而NASA的Valkyrie机器人具有44个自由度。如果实现一个像人一样灵活的机器人,就需要上百个自由度。
图3. 关节控制中的正运动学方程和逆运动学方程
机器人运动学包含正运动学和逆运动学,其中逆运动学是关节控制的关键。其要解决的问题是:给定机器人的位姿,求解机器人各个关节的关节变量。下图是逆运动方程求解的过程。
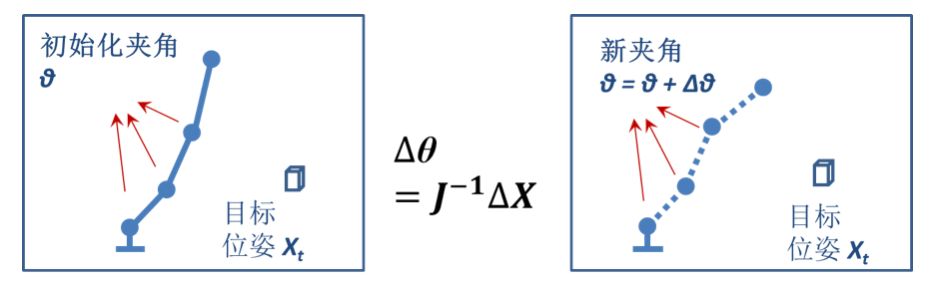
图4.逆运动学方程求解过程
可以看出,每次求解变化量,都是对变换矩阵求逆和矩阵乘的过程。目前,常用方法基于雅克比的求解,但是对大自由度机器人来讲,基于雅克比的方法非常耗时,不能满足机器人控制的实时性要求,最快的机器人逆运动学求解方法在求解100自由度机器人的逆运动学方程仍需要1秒钟左右的时间,很难满足机器人控制的实时性要求。为此,我们提出了两种方法:
Dadu-N:将逆运动学方程求解的过程近似为神经网络计算的过程。通过设计一个深度神经网络,将大量初始化位姿、目标位姿以及相应的夹角变化作为数据进行神经网路训练,得到一组权重。实际场景关节控制时,以初始位姿和目标位姿为输入数据,通过神经网络的推断过程,得到夹角变化数据。使用该方法的好处是,求解过程的复杂度和自由度无关,而只和选择的神经网络的复杂度有关,实现了计算复杂度和自由度解耦,自由度越高,加速比越大。
Dadu-S: 在上述雅克比求解过程中,主要耗时过程发生在矩阵J求逆。我们通过将雅克比矩阵求逆近似为对雅克比矩阵求转置: 来减少计算量,但该方法引入一个参数 ,需要通过多次迭代求出近似解,这一过程难以并行。我们改变直接求解的思路,采用 “投机求解”的思路。在每次迭代时,生成若干个参数值(投机值) , ,..., ,依据这些不同的参数值可以得到多个关节变量更新值θ,经过多次迭代最终找到满足精度要求的关节变量θ。由于多个参数值的计算及后续的关节变量更新值计算之间没有依赖,可以通过并行处理单元同时执行,从而加速求解速度。相比原雅克比转置法,该方法可以减少97%的迭代次数。
根据投机求解的方法[3],设计了相应的硬件加速器,用以提供更高的求解速度以及更高的能效比。该加速器可以在12ms内求解100自由度机器人的逆运动学问题,相比原方法可以提速1000倍,相比GPU版实现可以提速30倍左右。同时,相比GPU,该加速器的能效比可以提升700多倍。
结论
尽管机器人研究很热,但机器人处理器的研究尚处于萌芽阶段。本文介绍了我们在机器人智能处理器领域的一些探索性工作,应该说这项工作还比较初步,甚至“未来机器人领域会不会有一个被广泛接受的通用芯片形态”这个问题,我们目前都不能很好回答。但创新研究的一个目的就是解决探索未知世界道路上的不确定性,无论是科学价值还是应用前景,机器人智能芯片领域都值得探索。
-
机器人视觉——机器人的“眼睛”2015-01-23 6158
-
辰汉-如何实现服务机器人的运算与控制2017-06-09 3016
-
机器人传感器2018-01-03 3855
-
基于深度学习技术的智能机器人2018-05-31 6503
-
如何使用机器人录制和传输音频信号?2018-08-16 2978
-
基于ARM处理器的吸尘机器人硬件设计2018-11-06 2776
-
如何设计智能灭火机器人控制器?2019-07-31 4016
-
机器人系统是什么?2019-09-10 3409
-
ARM处理器的机器人硬件设计方法2020-05-20 2856
-
如何实现移动机器人的设计?2020-11-23 3335
-
机器人是什么?2022-03-31 22352
-
基于ARM处理器的吸尘机器人与硬件设计2017-09-24 998
-
高通机器人RB5平台将是无人机和自主机器人领域的变革者2020-07-08 2575
-
基于TI处理器的外骨骼辅助康复机器人2021-06-25 1037
-
NVIDIA IGX Thor 机器人处理器将实时物理 AI 引入工业和医疗边缘场景2025-10-29 1866
全部0条评论

快来发表一下你的评论吧 !
