

反向传播算法的工作原理
电子说
描述
反向传播算法(BP算法)是目前用来训练人工神经网络的最常用且最有效的算法。作为谷歌机器学习速成课程的配套材料,谷歌推出一个演示网站,直观地介绍了反向传播算法的工作原理。
反向传播算法对于快速训练大型神经网络来说至关重要。本文将介绍该算法的工作原理。
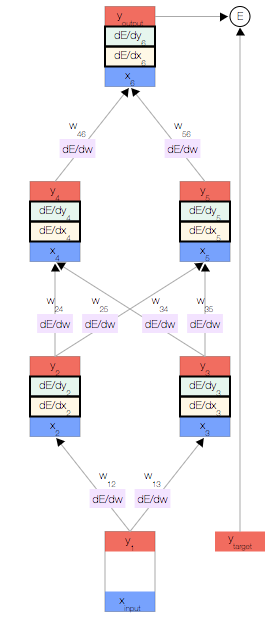
简单的神经网络
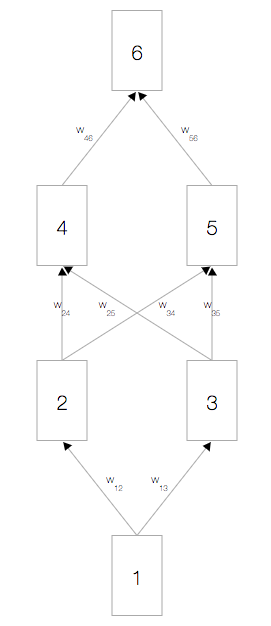
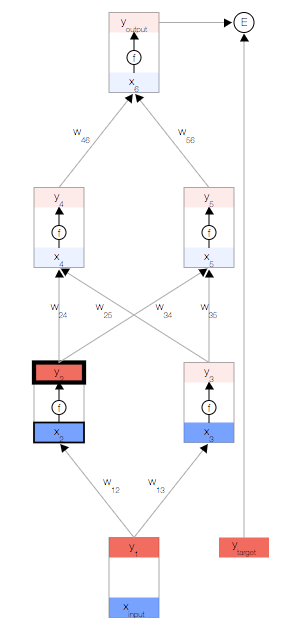
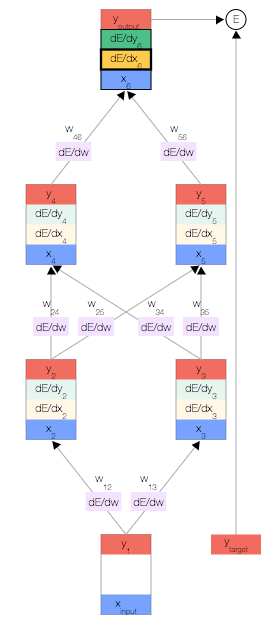
如上图,你会看到一个神经网络,其中包含一个输入节点、一个输出节点,以及两个隐藏层(分别有两个节点)。
相邻的层中的节点通过权重 相关联,这些权重是网络参数。
激活函数
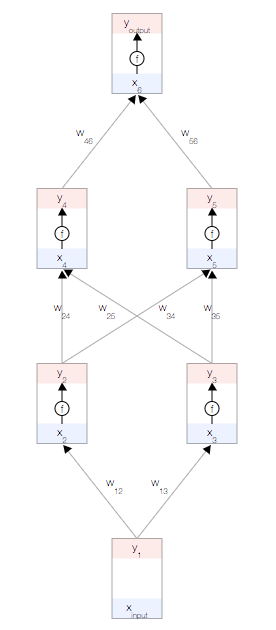
每个节点都有一个总输入 x、一个激活函数 f(x) 以及一个输出 y=f(x)。
f(x)必须是非线性函数,否则神经网络就只能学习线性模型。
常用的激活函数是 S 型函数:
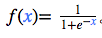
误差函数
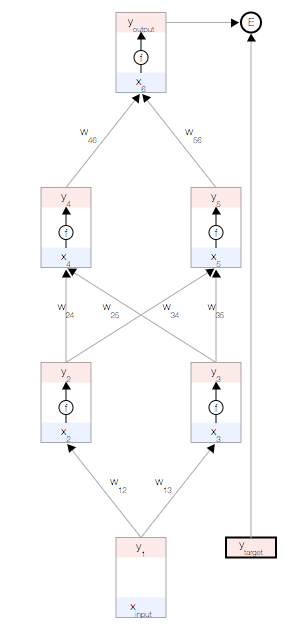
目标是根据数据自动学习网络的权重,以便让所有输入  的预测输出
的预测输出 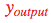 接近目标
接近目标 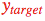
为了衡量与该目标的差距,我们使用了一个误差函数 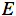 常用的误差函数是
常用的误差函数是
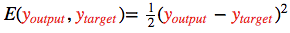
正向传播
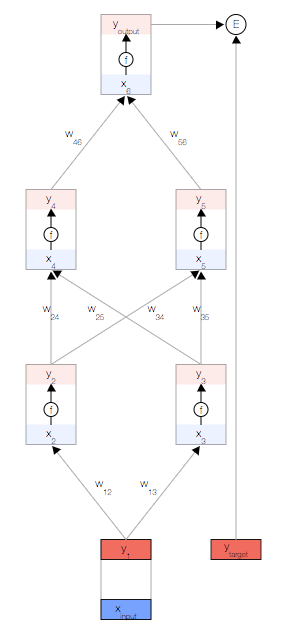
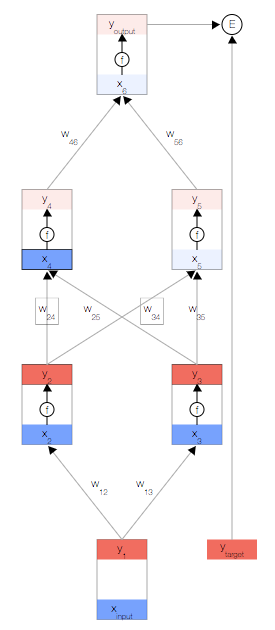
首先,我们取一个输入样本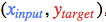 并更新网络的输入层。
并更新网络的输入层。
为了保持一致性,我们将输入视为与其他任何节点相同,但不具有激活函数,以便让其输出与输入相等,即 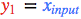
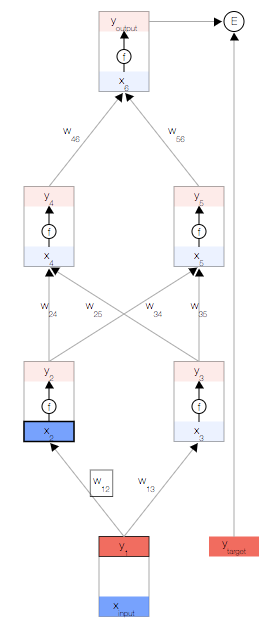
现在,我们更新第一个隐藏层。我们取上一层节点的输出 y,并使用权重来计算下一层节点的输入 x。
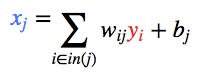
然后,我们更新第一个隐藏层中节点的输出。 为此,我们使用激活函数 f(x)。
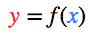
使用这两个公式,我们可以传播到网络的其余内容,并获得网络的最终输出。
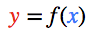
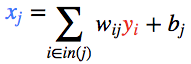
误差导数
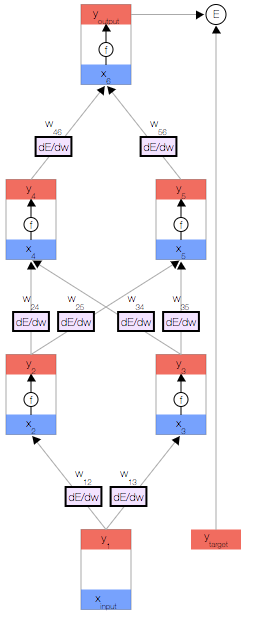
反向传播算法会对特定样本的预测输出和理想输出进行比较,然后确定网络的每个权重的更新幅度。 为此,我们需要计算误差相对于每个权重 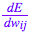 的变化情况。
的变化情况。
获得误差导数后,我们可以使用一种简单的更新法则来更新权重:
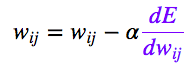
其中,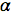 是一个正常量,称为“学习速率”,我们需要根据经验对该常量进行微调。
是一个正常量,称为“学习速率”,我们需要根据经验对该常量进行微调。
[注意] 该更新法则非常简单:如果在权重提高后误差降低了 (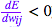 ),则提高权重;否则,如果在权重提高后误差也提高了 (
),则提高权重;否则,如果在权重提高后误差也提高了 (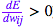 ),则降低权重。
),则降低权重。
其他导数
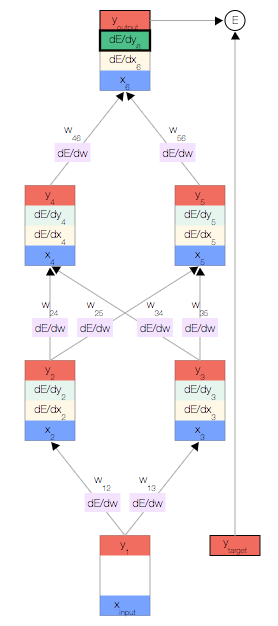
为了帮助计算 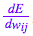 ,我们还为每个节点分别存储了另外两个导数,即误差随以下两项的变化情况:
,我们还为每个节点分别存储了另外两个导数,即误差随以下两项的变化情况:

反向传播
我们开始反向传播误差导数。 由于我们拥有此特定输入样本的预测输出,因此我们可以计算误差随该输出的变化情况。 根据我们的误差函数 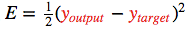 ,我们可以得出:
,我们可以得出:
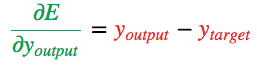
现在我们获得了 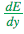 ,接下来便可以根据链式法则得出
,接下来便可以根据链式法则得出 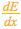 。
。
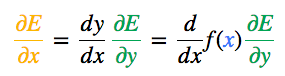
其中,当 f(x) 是 S 型激活函数时,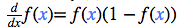
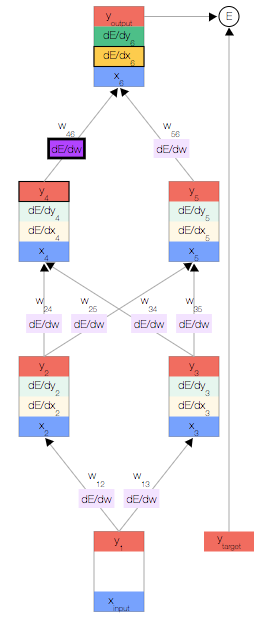
一旦得出相对于某节点的总输入的误差导数,我们便可以得出相对于进入该节点的权重的误差导数。
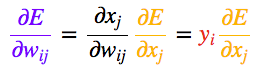
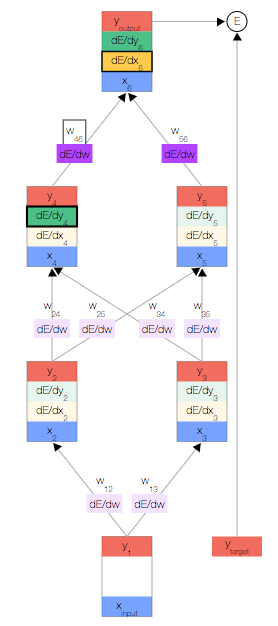
根据链式法则,我们还可以根据上一层得出 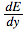 。此时,我们形成了一个完整的循环。
。此时,我们形成了一个完整的循环。
接下来,只需重复前面的 3 个公式,直到计算出所有误差导数即可。
结束。
-
反向传播如何实现2019-07-09 0
-
神经网络和反向传播算法2019-09-12 0
-
MapReduce的误差反向传播算法2017-12-20 675
-
深读解析反向传播算法在解决模型优化问题的方面应用2018-11-01 5860
-
浅析深度神经网络(DNN)反向传播算法(BP)2021-03-22 3907
-
PyTorch教程5.3之前向传播、反向传播和计算图2023-06-05 311
-
反向传播神经网络建模的基本原理2024-07-02 578
-
神经网络反向传播算法原理是什么2024-07-02 1203
-
神经网络前向传播和反向传播区别2024-07-02 1353
-
反向传播神经网络建模基本原理2024-07-03 747
-
神经网络反向传播算法的推导过程2024-07-03 951
-
神经网络反向传播算法的原理、数学推导及实现步骤2024-07-03 1602
-
神经网络反向传播算法的作用是什么2024-07-03 2266
-
神经网络反向传播算法的优缺点有哪些2024-07-03 1837
-
什么是BP神经网络的反向传播算法2025-02-12 610
- 树莓派与EthernetHat:用ChatGPT实现的MQTT智能家居项目!13小时前181
- 探索无刷小风扇驱动方案续航优化的 “密码”--【其利天下】05-30 18:191.1k
- 5分钟学会网络服务搭建,飞凌i.MX9352 + Linux 6.1实战示例05-30 11:08988
- 新品 | 视美泰发布高性价比4K超高清数字标牌主板DS-660A05-29 17:081.1k
- 高速PCB布局/布线的原则05-28 19:34516
- 解锁水泵降噪“新密码”,无刷驱动方案智解难题--【其利天下】05-28 17:41519
- ElfBoard嵌入式教育科普|CAN接口全面解析05-28 16:30577
- 芯对话 | CBM24AD98Q 24位精密医疗芯的破局之路05-28 10:02439
- PCB表面处理丨沉锡工艺深度解读05-28 07:33641
- 国产TurMass™技术革新智慧农业:加速农业现代化升级进程05-27 16:391.6k
- BLDC 电机的控制原理05-26 19:33874
- 栅极氧化层在SiC MOSFET设计中的重要作用05-26 18:07504
- 晶振在PCB板上如何布局05-26 16:11750
- 迅为RK3568开发板驱动指南GPIO子系统三级节点操作函数实验05-26 15:39501
- 树莓派“定居”完全指南:一键设置静态IP,稳定又高效!05-25 08:32495
全部0条评论

快来发表一下你的评论吧 !
