

一种称为标签映射(LM)的方法来解决大规模分类问题?
电子说
描述
近年来,深度学习已成为机器学习社区的一个主要研究领域。其中一个主要挑战是这种深层网络模型的结构通常很复杂。对于一般的多类别分类任务,所需的深度网络参数通常随着类别数量的增加而呈现超线性增长。如果类别的数量很大,多类别的分类问题将变得不可行,因为模型所需的计算资源和内存存储将是巨大的。然而,如今的很多应用程序需要解决庞大数量的多分类问题,如词级别的语言模型,电子商务中购物项目的图像识别(如现在淘宝和亚马逊上数百万的购物项),以及 10K 中文手写汉字的识别等。
为此,来自阿里巴巴的团队提出了一种称为标签映射(LM)的方法:通过将原始的分类任务分解成几个理论上可解决的子分类任务,来解决这个问题。
据介绍,这种方法类似纠错输出代码(ECOC) 一样的集成方法,但它还允许base learner 不同标签数量的多类别分类器。该团队提出了LM 的两种设计原则,一个是最大化基本分类器(可以对两个不同类别进行分类)的数量,另一个是尽可能地保证所有base learner 之间的独立性以便减少冗余信息。由于每个base learner 可以独立地进行训练,因此很容易能将该方法扩展到一个大规模的训练体系。实验表明,他们所提出的方法在准确性和模型复杂性方面,显著优于标准的独热编码和 ECOC 方法。
▌简介
事实上,用于处理 N 类的深度神经网络分类器通常可以被看作是将欧式空间中一些复杂的嵌入表示连接到最后一层的 softmax 分类器上。复杂的嵌入表示可以被解释为是一种聚类过程,即根据类别的标签将数据进行聚类并在最后一层将分离数据。聚类过程会根据类别标签对数据进行聚类,并在最后一层尝试将它们分开。如果欧式空间最后一层的维度大于或等于 N-1,那么将存在一个 softmax 分类器分离那些概率1的聚类。但是,如果欧式空间的维度小于 N-1,那么将不存在一个 softmax 分类器能够将一个聚类从中分离出来并使其聚类中心位于其他聚类中心所构成的凸集平面内,因为凸集上的线性函数总是能够在顶点处取得最大值。
解决这种 N 类别的分类问题,要么固定最后一层的维度,这将导致分类的性能变得很差;或者让最后一层的维度随着 N 的增长而增长,但这会导致最后两层的模型参数随着 N 的增加而呈现超线性增长。网络大小的超线性增长将显著增加训练的时间和内存的使用量,这将严重限制模型在许多现实的多类别问题中的应用。
本文我们提出了一种称为标签映射(LM)的方法来解决这个矛盾。我们的想法是将一个多类别的分类问题,变成多个小类别的分类问题,并平行地训练这些小类别的分类问题。分布式训练将放缓计算量和内存的增加,同时不需要机器之间的通信。
▌方法(标签映射)
如上所述,通常 N 类的深度神经网络分类器通常可以被看作是将欧式空间中一些列复杂的嵌入表示连接到最后一层的 softmax 分类器上。在本文中,我们进行了如下的一些定义:
我们把欧式空间 V 中 N 个点的集合称为 X,满足凸集的性质,并保证当且仅当凸集 X 的闭合具有确切的 N 个顶点。换句话说,softmax 分类器能够在欧式空间 V 中分离所有的 N 个聚类,并使得聚类中心落在凸集的内部。
对于一个多类别的分类问题,我们引入一种标签映射的方法,将大规模的多类别分类问题转化为一些子分类问题。一个映射序列的标签映射定义如下:
其中,每个 fi 都代表一个地点位置函数 (site-position function),n表示标签映射的长度,N表示类别数量。如果每个每个类别都相等的话,我们称之为单一的标签映射,否则则定义为混合的标签映射。
一般来说,N 是一个很大的数字,而Ni 是中等大小的一些数字。 我们可以通过标签映射将一个 N 类别的分类问题减小为 n 的中等尺寸的分类问题。假设训练数据集是{xk, yk},其中 xk 表示特征,而 yk 表示标签,有两种方法可以在深度神经网络模型中使用标签映射。一种是使用一个具有 n 个输出的网络 (如图1)。另一种是使用 n 个网络,每个网络都被训练成数据集中的base learner (如图2)。
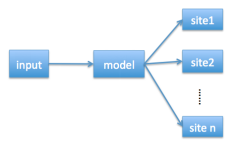
图1: n 个输出的网络
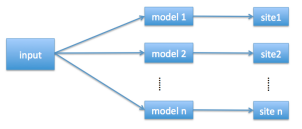
图2:n 个网络,每个网络有 n 个输出
考虑到分布式训练的便捷性,这里我们使用图2中的方法。此外,我们还规定标签映射应满足如下性质:
类别的高度分离性:对于两种不同的标签,尽可能保证二者高度分离,这里我们通过一个地点位置函数 fi 来衡量。
基础学习器的独立性:类别的高度分离性保证了每个基础学习器都能够通过训练将不同类别分离,而基础学习器的独立性保证了相同的信息能够被尽可能少的学习器所学习。
与 ECOC 的差异性:我们的标签映射方法不需要将多分类问题转化成二分类问题 (如 ECOC 方法),也不需要转化为相同类别数量的分类问题。
▌实验过程
我们在 Cifar-100,CJK 字符和 Republic 三个数据集上测试了标签映射的性能。
CIFAR-100 数据集由60000张100个类别的32x32彩色图像构成,每个类别有500张训练图像和100张测试图像。我们使用一个简单的 CNN 网络,其结构示意图如下图3,最后一层的维度是128,每个类别的标签都是一个独热编码。
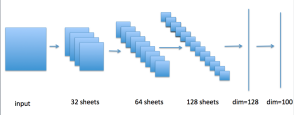
图3:CNN 的模型结构示意图
CJK 字符数据集由20901张139×139的灰度字符图像构成。我们使用 Inception V3 模型,其最后一层的维度为2048,并使用独热编码对应数据集中每个字符类别的标签。
Republic 数据集由一个含118684个词的文本构成,其中7409个词是独一无二的。我们使用一个 RNN 模型,其最后一层的维度为100,其结构示意图如图4所示。同样,我们对类别标签进行独热编码。
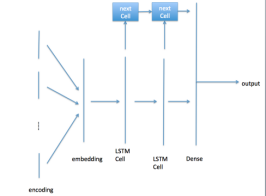
图4:RNN 模型结构示意图
▌结果分析
我们分别对三个数据集进行对比实验,评估单一标签映射、混合标签映射及标签映射与 ECOC 方法之间的优劣性。实验结果表明,标签映射的准确性将随着数据集长度的增大而升高。在 Cifar-100 数据集上,使用独热编码的标签会给标签映射的准确性带来更大的提高,而对于其他两个数据集的提升却不是很明显。这是因为独热编码的引入能够充分发挥简单 CNN 结构的优势,而对于 Inception V3 模型而言,其最后一层的维度小于 CJK 数据集的类别数量,因而独热编码的作用没能发挥出来。同样地,对于最后一层的维度小于 Republic 数据集类别数的 RNN 模型,独热编码的强大性也无法充分体现。
Cifar-100 数据集
下图5、图6、图7分别表示单一标签映射、混合标签映射作用下的精度及标签映射方法与 ECOC 方法的对比结果。
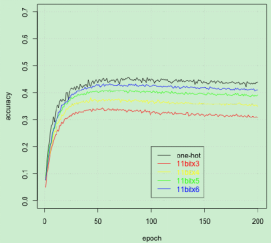
图5:单一标签映射下的精度
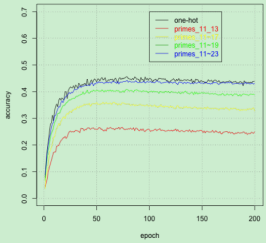
图6:混合标签映射下的精度
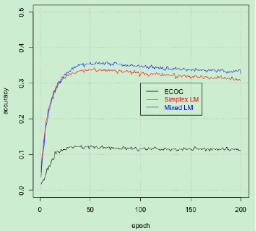
图7:标签映射与 ECOC 方法的对比结果
CJK 数据集
下表1、表2、表3分别表示单一标签映射、混合标签映射作用下的精度及标签映射方法与 ECOC 方法的对比结果。

表1 单一标签映射作用下的性能

表2 混合标签映射作用下的性能

表3 标签映射与 ECOC 方法的对比结果
Republic 数据集
表4显示标签映射方法在 Republic 数据集上的性能。
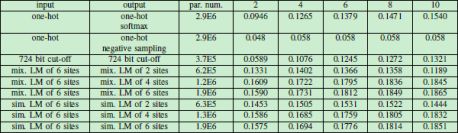
表4 标签映射作用下的性能
▌结论
我们提出了一种方法称为标签映射(LM),能够将大规模的多类别分类问题到分解成多个小规模的子分类问题,并为每个子分类问题训练base learner。而所需的base learner 数量随着类别数量的增加而增加。此外,我们提出两个设计原则,即类别高可分离性和base learner 的独立性,并提出两类满足该原则的标签映射,即单一标签映射和混合标签映射。我们分别在 Cifar-100、CJK 和 Republic 三个数据集上展示了标签映射的性能。实验结果表明,标签映射的性能随长度的增加而增加。当类别数量很大时(如 CJK 字符数据集和 Republic 数据集),特别当数量远大于模型最后一层的维度时,标签映射的性能更佳。此外,我们还对比了标签映射与 ECOC 方法的性能,发现在更少参数量的情况下,我们的方法还远远优于 ECOC 方法。
-
一种工作于Sub-6G的5G大规模天线的系统架构探讨2019-07-16 0
-
大规模MIMO的性能2019-07-17 0
-
有没有一种方法来配置MPLAX X来从RAM运行应用程序?2019-09-12 0
-
请问有另一种方法来测量RTD传感器而不使用IDAC吗?2019-10-11 0
-
一种先分割后分类的两阶段同步端到端缺陷检测方法2020-07-24 0
-
介绍一种适合大规模数字信号处理的并行处理结构2021-04-30 0
-
一个benchmark实现大规模数据集上的OOD检测2022-08-31 0
-
STEP模式映射的一种实用方法2010-02-22 620
-
一种多重映射的自动短文摘方法2017-12-23 751
-
科学家找到一种化学方法来储存和操作大量的数据2018-02-01 4613
-
一种新方法来检测这些被操纵的换脸视频的“迹象”2018-07-03 5798
-
一种处理多标签文本分类的新颖推理机制2021-02-05 2947
-
一种基于光滑表示的半监督分类算法2021-04-08 610
-
最后一种方法来整理你的电阻器2022-12-19 413
-
一种简单的方法来将振荡器相位噪声转换为时间抖动2023-11-23 195
全部0条评论

快来发表一下你的评论吧 !
