

格灵深瞳突破文本人物检索技术难题
描述
对计算机来说,理解“穿红色上衣的长发女性”这类特征性描述,并在海量图片中精准找到对应人物,是一项复杂的技术难题。尽管多模态预训练模型CLIP在多种视觉任务中展示出强大的性能,但其在人物表征学习的应用中,也就是“以文找人”时,面临两个关键挑战:
一是缺乏专注于人物中心图像的大规模训练数据;二是容易受到噪声文本标记的影响。
格灵深瞳参与研究的GA-DMS框架,为攻破上述技术难题提供了全新解决方案。研究团队通过数据构建和模型架构的协同改进,推动CLIP在人物表征学习中的应用,显著提升了基于文本的人物检索效果。该成果已入选EMNLP 2025 主会(自然语言处理领域的顶级国际会议之一)。
首先,团队开发了一个抗噪声的数据构建管道,利用机器学习语言模型(MLLMs)的上下文学习能力,自动过滤和标注网络来源的图像。这产生了一个大规模数据集WebPerson,包含500万高质量的人物中心图像-文本对。
其次,团队引入了梯度-注意力引导的双重遮蔽协同(GA-DMS)框架,用来改善跨模态对齐。
此外,团队还加入了遮蔽标记预测目标,让模型能够预测信息丰富的文本标记,增强细粒度语义表征学习。
广泛的实验表明,GA-DMS在多个基准测试中达到了最先进的性能,实现了更精准的“以文找人”检索能力——在CUHK-PEDES数据集上的准确率达到77.6%,在RSTPReid上准确率达到71.25%。
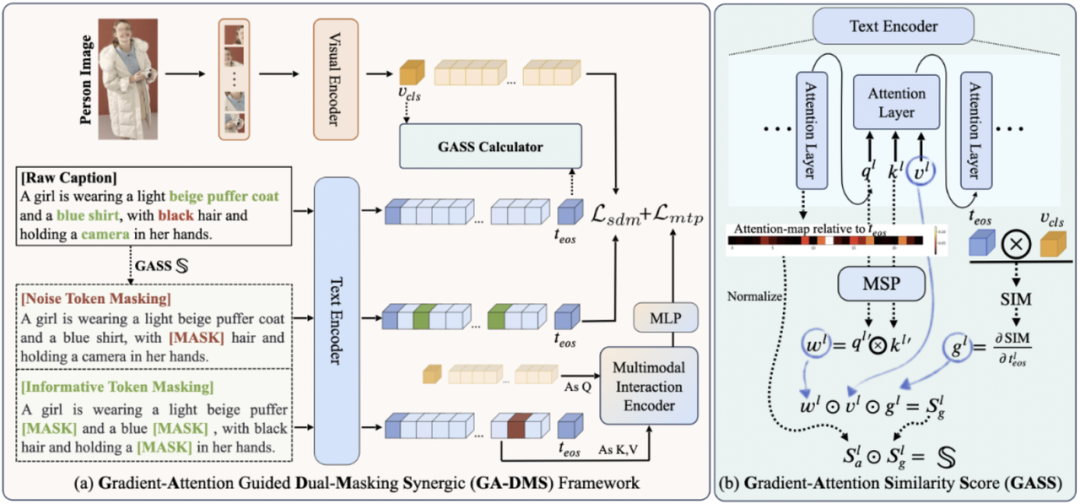
GA-DMS技术示意图
关于技术报告的更多细节,可点击下方链接体验。
论文题目:Gradient-Attention Guided Dual-Masking Synergetic Framework for Robust Text-based Person Retrieval
研究团队:格灵深瞳、东北大学、华南理工大学
报告链接:https://arxiv.org/pdf/2509.09118
项目主页:https://github.com/Multimodal-Representation-Learning-MRL/GA-DMS
全部0条评论

快来发表一下你的评论吧 !
