

针对智能驾驶应用,深度学习应该如何落地呢?
描述
本文由前向启创&CTO张晖介绍了前向启创在TI TDA芯片上,使用深度学习方法,解决智能驾驶感知问题的一些经验。
深度学习以其强大的特征表示能力,已经在许多应用领域中体现出了不俗的性能。而针对智能驾驶应用,深度学习应该如何落地呢?
前向启创&CTO张晖认为,主要存在有两大技术挑战:一是主芯片的选型,二则是针对特定芯片的深度学习算法的设计与实现。
前向启创&CTO张晖,2004年毕业于华中科技大学,获双学士学位;2004-2005年就职于美国安凯微电子,任算法工程师;005-2013年就职于美国ZORAN(CSR/Qualcomm)公司,任算法研发经理;近15年算法芯片化与产品化经验;在ACCV、ICPR等国际会议上发表学术论文多篇;拥有多项中美发明专利。
TI智能驾驶ASIC
针对智能驾驶产品主处理器芯片进行选型,应该将汽车智能驾驶产品的主要诉求——高可靠性与低成本,作为主要参考依据。
从业界角度来看,智能驾驶主芯片可分两大流派,一派为ASIC,将特定的算法计算引擎芯片化,代表企业有如TI、Mobileye、nVidia、Ambarella等;另一派则为FPGA,代表企业有如Xilinx,Altera等。
而ASIC以其定制性,在成本、功耗、算力、弹性、车规、功能安全等级以及量产周期上达到了更好的平衡。
TI(Texas Instuments)自2010年起开始提供针对智能驾驶的ASIC芯片TDA(TIDriverAssist)系列,至今已经迭代到了第四代。
经过多年的演进,TI已经将多项针对智能驾驶的算法逐步芯片化、引擎化,其功能安全等级,也达到了ASIL-C级。
TI的ASIC芯片TDA(TIDriverAssist)系列
TI的智能驾驶芯片以其优异的性价比,已被全球超过15家Tier1、25家OEM主机厂所采用,成功在近100款车型中量产,已累积出货近4千万片。目前前向启创也采用TI ASIC芯片。
深度网络设计
网络模型设计是深度学习应用的关键,如何设计一个能满足产品化要求的智能驾驶感知网络呢?
张晖认为,主要存在着两大关键点,第一需要贴近任务和系统需求,即必须针对智能驾驶系统应用对感知层的需求来进行网络设计,切不可为了使用深度学习而选择深度神经网络;
第二需要考虑到芯片嵌入式平台算力受限系统,必须因芯设计,切不可盲目的进行网络堆砌,导致运算量过大,而造成无法部署到芯片上的问题。
从智能驾驶的任务来看,Level2–Level3系统对感知提出了更高的要求,例如AEB-Cross需要检测车辆侧面状态,TJA(TrafficJamAssistance)更需要识别出可通行区域,即FreeSpace,等等。
针对车辆侧面检测,前向启创重新设计了一套FINet网络,将传统的2D-BoundingBox扩展到了3D-BoundingBox,可以对车辆的多个表面进行检测。
前向启创针对车辆侧面检测设计的FINet网络
而针对FreeSpace任务,前向启创重新设计了的FINet可将此任务分解为,对Flat平坦可通行区域;Step路沿台阶;以及Obstacle障碍物三大类目标进行分割。
前向启创针对FreeSpace任务,FINet分解为三大类目标
深度网络优化
常见的深度学习网络都对主芯片的算力提出了比较高的要求。
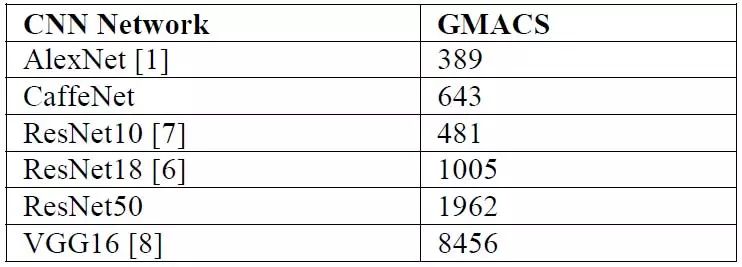
常见网络在对720P@30fps图像进行推理时,对算力的要求
由上图可看出,大部分网络对算力的要求超过了1Tops,而类似TITDA2x这类低功耗芯片目前达不到1Tops算力要求。所以在网络基础模型设计好后,为了大幅降低模型的GMACS以适应算力受限的芯片平台,就需要针对芯片进行网络的细调整(FineTuning)及优化。
针对TIASIC的芯片架构,前向启创主要采用了两大方法进行网络优化,第一卷积稀疏化,第二8-BIT量化技术。
第一,卷积稀疏化方法是通过调整损失函数,对权重小于动态阈值的卷积核中的系数进行归零处理,再将此稀疏度的张量重新进行调优训练,对已归零处理后的系数不再进行反向传播更新,最后以达到在保证稀疏度的情况下,训练精度没有明显的下降。
两种不同稀疏度的目标函数下,通过调优训练出来的滤波器的核
第二,动态8-BIT量化技术,动态指的是在8-BIT的最大位宽的前提下,尽量高地提高张量的量化精度,即有符号与否,定标值是多少,都随张量的范围而进行动态调整。
在完成以上两步优化后,前向启创的FINet网络在精度下降不到1%的情况下,整体提速了近10倍。
芯片级部署与实现
针对智能驾驶应用,TI的TDA系列芯片采用了多核异构的芯片架构来达到算力与功耗平衡,而其中的子处理器是可配置的,如DSP和EVE等子处理器单元数可以选择,以求针对系统要求,达到更合适的性价比。
整体芯片架构如图所示
多核异构架构的最大优点就是能够将不同类型的计算或控制任务异核化,TITDA系列芯片的设计初衷中,视觉感知的中低层计算任务主要被集中到了DSP和EVE这两类子处理器上:
TITDA系列芯片的设计
EVE作为TI针对智能驾驶应用而专门设计的向量硬件加速器,在同等功耗下,相比于现有其它智能驾驶芯片,每个EVE核能够达到8倍的计算性能的提升。
每个EVE核能够达到8倍的计算性能的提升
针对深度神经网络中最耗时的卷积运算部分,在部署阶段,前向启创主要使用了其中的EVE核来进行计算,利用EVE中的SIMD特性,可以将FINet中的卷积运算部分提速8倍左右。
完成在TI芯片上的部署后,前向启创FINet网络整体上能够达到实时感知的系统性能要求。
在TITDA这类成熟的ASIC上,通过网络设计、网络优化以及芯片部署这三大步,就能基本实现深度神经网络的初步框架。
在后续的产品化过程中,还需根据实际的系统需求,对这三步进行闭环式的迭代,以求达到系统性能与算力的最佳平衡。
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 0
-
百度深度学习研究院科学家深度讲解人工智能2018-07-19 0
-
华为云深度学习服务,让企业智能从此不求人2018-08-02 0
-
硅谷组建团队、L3产品落地,想法多多的腾讯自动驾驶2018-11-13 0
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 0
-
深度学习是什么2021-07-19 0
-
智能驾驶的狂想与现实落地 精选资料分享2021-07-27 0
-
智能驾驶域控制器的SoC芯片选型2022-08-11 0
-
人工智能深度学习未来应该如何发展的详细概述2018-06-02 4106
-
探讨深度学习在自动驾驶中的应用2018-08-18 5169
-
基于魔视智能先进的嵌入式深度学习技术的辅助自动驾驶产品正式量产落地2018-10-18 3493
-
深度学习技术与自动驾驶设计的结合2019-10-28 2039
-
深度学习:搜索和推荐中的深度匹配问题2020-11-05 4126
-
深度学习算法在自动驾驶规控中的应用解读2022-11-16 1271
-
深度学习在自动驾驶中的关键技术2024-07-01 793
全部0条评论

快来发表一下你的评论吧 !
