

基于交错组卷积的高效DNN详解
电子说
描述
卷积神经网络在近几年获得了跨越式的发展,虽然它们在诸如图像识别任务上的效果越来越好,但是随之而来的则是模型复杂度的不断提升。越来越深、越来越复杂的卷积神经网络需要大量存储与计算资源,因此设计高效的卷积神经网络是非常重要和基础的问题,而消除卷积的冗余性是该问题主要的解决方案之一。
如何消除消除卷积的冗余性?我们邀请到了微软亚洲研究院视觉计算组资深研究员王井东博士,为大家讲解发表在 ICCV 2017 和 CVPR 2018 上基于交错组卷积的方法。
以下是公开课内容,AI科技大本营整理,略有删减:
▌深度学习大获成功的原因
2006年《Science》上的一篇文章——Reducing the Dimensionality of Data with Neural Networks,是近十多年来促进深度学习发展非常重要的一篇文章。当时这篇文章出来的时候,很多机器学习领域的人都在关注这个工作,但是它在计算机视觉领域里并没有取得非常好的效果,所以并没有引起计算机视觉领域的人的关注。
深度学习的方法在计算机视觉领域真正得到关注是因为 2012 年的一篇文章——ImageNet Classification with Deep Convolutional Neural Networks。这个文章用深度卷积神经网络的方法赢得了计算机视觉领域里一个非常重要的 ImageNet 比赛的冠军。在 2012 年之前的冠军都是基于 SVM(支持向量机)或者随机森林的方法。
2012年 Hinton 和他的团队通过深度网络取得了非常大的成功,这个成功大到什么程度?比前一年的结果提高了十几个百分点,这是非常可观、非常了不起的提高。因为在 ImageNet 比赛上的成功,计算机视觉领域开始接受深度学习的方法。
比较这两篇文章,虽然我们都称之为深度学习,但实际上相差还挺大的。特别是 2012 年这篇文章叫“深度卷积神经网络”,简写成 “CNN”。CNN 不是 2012 年这篇文章新提出来的,在九十年代,Yann LeCun 已经把 CNN 用在数字识别里,而且取得非常大的成功,但是在很长的时间里,大家都没有拿 CNN 做 ImageNet 比赛,直到这篇文章。今天大家发现深度学习已经统治了计算机视觉领域。
为什么 2012 年深度学习能够成功?其实除了深度学习或者 CNN 的方法以外,还有两个东西,一个是 GPU,还有一个就是 ImageNet。
这个网络结构是 2012 年 Hinton 跟他学生提出的,其实这个网络结构也就8层,好像没有那么深,但当时训练这个网络非常困难,需要一个星期才训练出来,而且当时别人想复现它的结果也没有那么容易。
这篇文章以后,大家都相信神经网络越深,性能就会变得越好。这里面有几个代表性的工作,简单回顾一下。
深度网络结构的两个发展方向
▌越来越深
2014 年的 VGG,这个网络结构非常简单,就是一层一层堆积起来的,而且层与层之间非常相似。
同一年,Google 有一个网络结构,称之为“GoogLeNet”,这个网络结构看起来比 VGG 的结构复杂一点。这个网络结构刚出来的时候看起来比较复杂,今天看起来就是多分支的一个结构。刚开始,大家普遍的观点是这个网络结构是人工调出来的,没有很强的推广性。尽管 GoogLeNet 是一个人工设计的网络结构,其实这里面有非常值得借鉴的东西,包括有长有短多分支结构。
2015 年时出了一个网络结构叫 Highway。Highway 这篇文章主要是说,我们可以把 100 层的网络甚至 100 多层的网络训练得非常好。它为什么能够训练得非常好?这里面有一个概念是信息流,它通过 SkipConnection 可以把信息很快的从最前面传递到后面层去,在反向传播的时候也可以把后面的梯度很快传到前面去。这里面有一个问题,就是这个 Skip Connection 使用了 gate function,使得深度网络训练困难仍然没有真正解决。
同一年,微软的同事发明了一个网络,叫“ResNet”,这个网络跟 Highway 在某种意义上很相像,相像在什么地方?它同样用了 Skip Connection,从某一层的 output 直接跳到后面层的 output 去。这个跟 Highway 相比,它把 gate function 扔掉了,原因在于在训练非常深的网络里 gate 不是一个特别好的东西。通过这个设计,它可以把 100 多层的网络训练得非常好。后来发现,通过这招 1000 层的网络也可以训练得非常好,非常了不起。
2016年,GoogLeNet、Highway、ResNet出现以后,我们发现这里面的有长有短的多分支结构非常重要,比如我们的工作 deeply-fused nets,在多个 Branch 里面,每个分支深度是不一样的这样的好处在于,如果我们把从这个结构看成一个图的话,发现从这个输入点到那个输出点有多条路径,有的路径长,有的路径短,从这个意义上来讲,我们认为有长有短的路径可以把深度神经网络训练好。
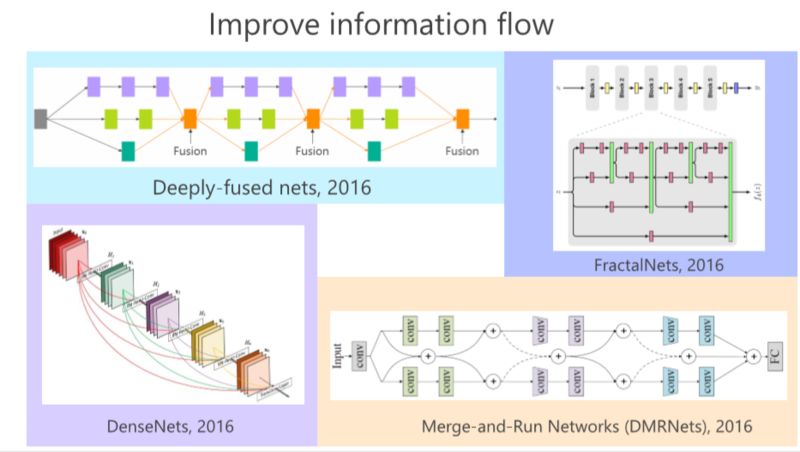
同年,我们发现有个类似的工作,叫 FractalNets,它跟我们的 deeply-fused nets 非常相像。
这条路都是通过变深,希望把网络结构训练得非常好,使它的性能非常好,加上 Skip Connection 等等形式来使得信息流非常好。尽管我们通过 Skip Connection 把深度网络训练得很不错,但深度还是带来一些问题,就是并没有把性能发挥得很好,所以有另外一个维度,大家希望变得更宽一点。
除此之外,大的网络用在实际中会遇到一些问题。比如部署到手机上时希望计算量不要太大,模型也不要太大,性能仍然要很好,所以识别率做的非常高的但是很庞大的网络结构在实际应用里面临一些困难。
▌简化结构的几种方法

另外一条路是简化网络结构,消除里面的冗余性。因为大家都认为现在深度神经网络结构里有很强的冗余性,消除冗余性是我近几年发现非常值得做的一个领域,因为它的实际用处很大。
卷积操作
CNN 里面的卷积操作实际上对应的就是矩阵向量相乘,大家做的基本就是消除卷积里的冗余性。
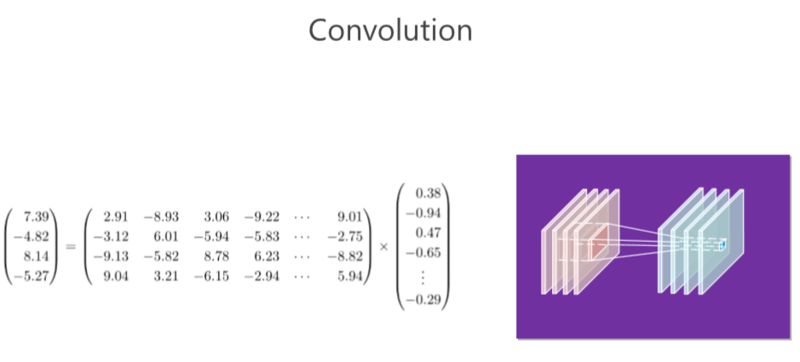
我们回顾一下卷积。右边的图:在 CNN 里面有若干个通道,每个通道实际上是一个二维的数组,每个位置都有一个数值,在这里面我们称为“响应值”。这里面有四个通道,实际上就相当于三维的数组一样。以这里(每个位置)为中心,取一个 3×3 的小块出来,3×34 个通道,那就有 3×3×4 这么多个数值,然后我们把这么多个数值拉成一个 3×3×4=36 维向量。卷积有个卷积核,卷积核对应一个横向量,这个横向量和列向量一相乘,就会得到响应的值,这是第一个卷积核。通过第二个卷积核又会得到第二个值,类似地可以得到第三个第四个值。
总结起来,卷积操作就是是矩阵和向量相乘,矩阵对应的是若干个卷积核,向量对应的是周围方块的响应值(ResponseValue)。
大家都知道矩阵跟向量相乘占了很大的计算量。我在这里举的例子并没有那么大,但大家想一想,如果输入输出 100个 通道,,假如这个卷积核是3×3×100,那就是 100×900 的计算量,这个计算量非常大,所以有大部分工作集中在解决这里面(卷积操作)冗余性的问题。
Low-precision kernels(低精度卷积核)
有什么办法解决冗余性的问题呢?

因为卷积核通常是浮点型的数,浮点型的数计算复杂度要大一点,同时它占得空间也会大一点。最简单的一招是什么?假设把卷积核变成二值的,比如 1、-1,我们看看 1、-1转成以后有什么好处?这个向量 1、-1(使得)本来相乘的操作变成加减了,这样一来计算量就减少了很多。除此以外,模型和存储量也减少很多。

也有类似相关的工作,就是把浮点型的变成整型的,比如以前 32 位浮点数的变成 16 位的整型数,同样存储量会小,或者模型会小。除了卷积核进行二值化化以外或者进行整数化以外,也可以把 Response 变成二值数或者整数。

还有一类研究得比较多的是量化。比如把这个矩阵聚类,比如 2.91、3.06、3.21,聚成一类,我用 3 来代替它量化有什么好处?首先,你的存储量减少了,不需要存储原来的数值,只需要存量化以后的每个中心的索引值就可以了。除此之外,计算量也变小了,你可以想办法让它减少乘的次数,这样就模型大小就会减少了。
Low-rank kernels(低秩卷积核)


另外一条路,矩阵大怎么办?把矩阵变小一点,所以很多人做了这件事情, 100 个(输出)通道,我把它变成 50 个,这是一招。另外一招, input(输入)很多, 100 个通道,变成了 50 个。
低秩卷积核的组合

把通道变少会不会降低性能?所以有人做了这件事情:把这个矩阵变成两个小矩阵相乘,假如这个矩阵是 100×100 的,我把它变成 100×10 和10×100 两个矩阵相乘,(相乘得到的矩阵)也变成 100×100 的矩阵,近似原来 100×100 那个矩阵。这样想想,100×100 变成 100×10 跟 10×100,显然模型变小了,变成五分之一。此外计算量也降到五分之一。
稀疏卷积核
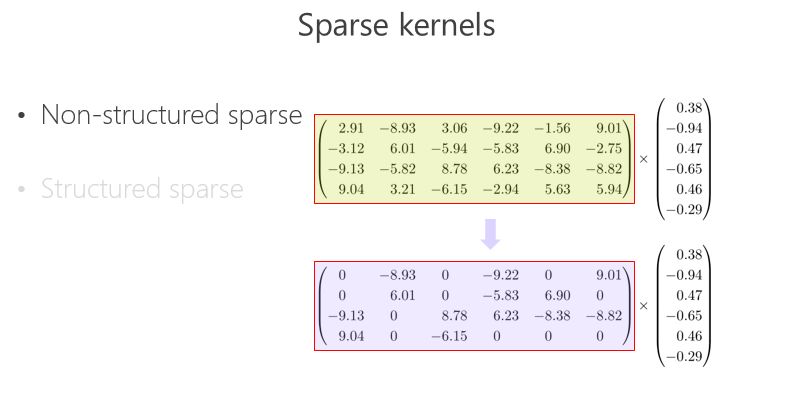
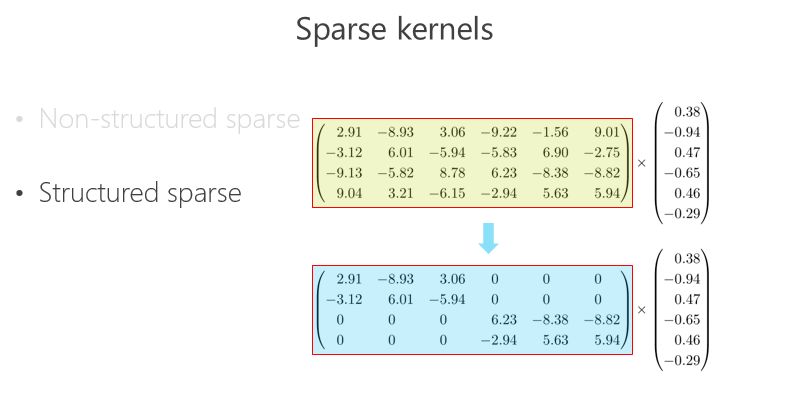
另外一条路,怎么把矩阵跟向量相乘变得快一点、模型的参数少一点?可以把里面的有些数变成 0,比如 2.91 变成 0,3.06 变成 0,变成 0 以后就成了稀疏的矩阵,这个稀疏矩阵存储量会变小,如果你足够稀疏的话,计算量会小,因为直接是 0 就不用乘了。还有一种 Structured sparse(结构化稀疏),比如这种对角形式,矩阵跟向量相乘,可以优化得很好。这里 Structured sparse 对应我后面将要讲的组卷积(Groupconvolution)。
稀疏卷积核的组合
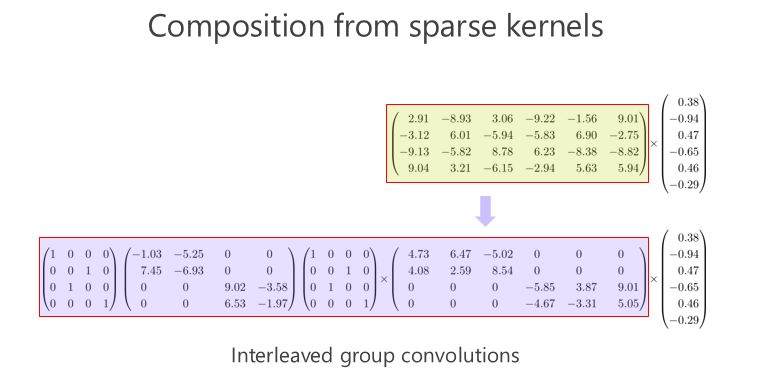
我们来看看这个矩阵能不能通过多个稀疏矩阵相乘来近似,这是我今天要讲的重点,我们的工作也是围绕这一点在往前走。在我们做这个方向之前,大家并没有意识到一个矩阵可以变成两个稀疏矩阵相乘甚至多个稀疏矩阵相乘,来达到模型小跟计算量小的目标。
从IGCV1到IGCV3
▌IGCV1
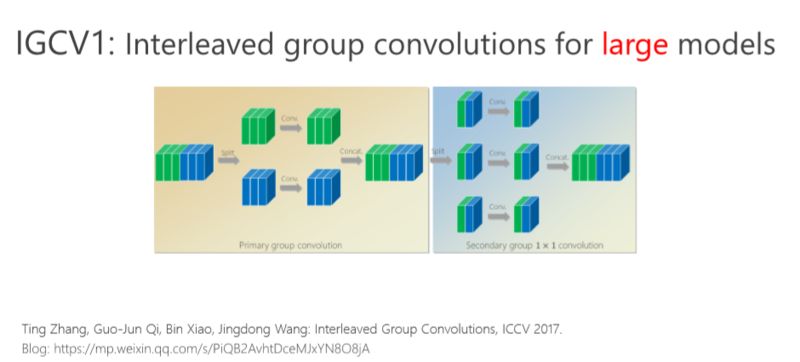
首先我给大家介绍一下我们去年在 ICCV 2017 年会议上的文章,交错组卷积的方法。
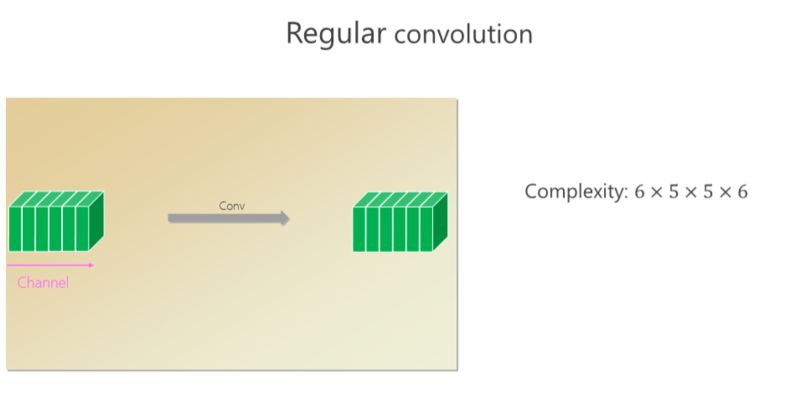
这个卷积里面有六个通道,通过卷积出来的也是六个小方块(通道),假如 spatial kernel 的尺寸是5×5,对每个位置来讲,它的计算量是6×5×5×6。
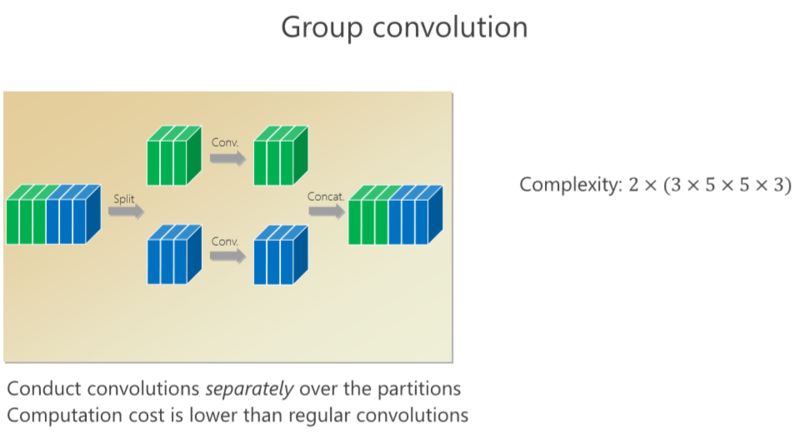
我刚才讲了(一种结构化)稀疏的形式,对应的就是组卷积的形式,组卷积是什么意思?我把这 6 个通道分成上面 3 个通道和下面 3 个通道,分别做卷积,做完以后把它们拼在一起,最后得到的是6个通道。看看计算量,上面是 3×5×5×3,下面也是一样的,整个计算复杂度跟前面的 6×5×5×6 相比就小了一半,但问题是参数利用率可能不够。
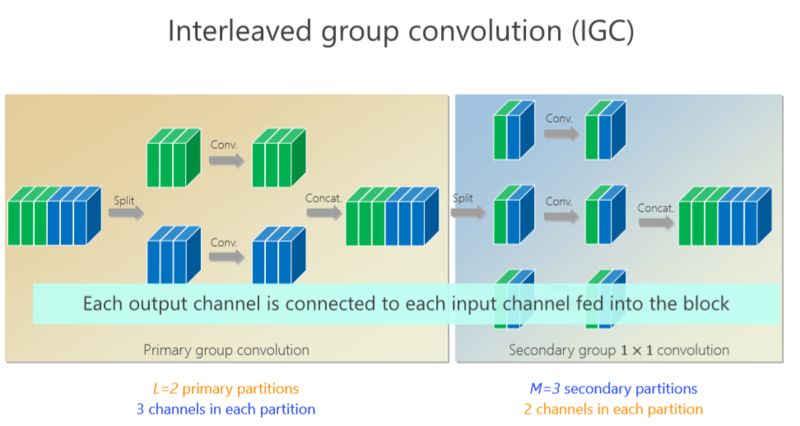
我们的工作是基于组卷积的,刚才提到了上面的三个通道和这三个通道不相关,那有没有办法让它们相关?所以我们又引进了第二个组卷积,我们把这6个通道重新排了序,1、4 放到这(第一个分支),2、5 放到这(第二个分支),3、6 放到那(第三个分支),这样每一分支再做一次 1×1 的convolution,得出新的两个通道、两个通道、两个通道,拼在一起。通过交错的方式,我们希望达到每个 output(输出)的通道(绿色的通道或者蓝色的通道)跟前面6个通道都相连。
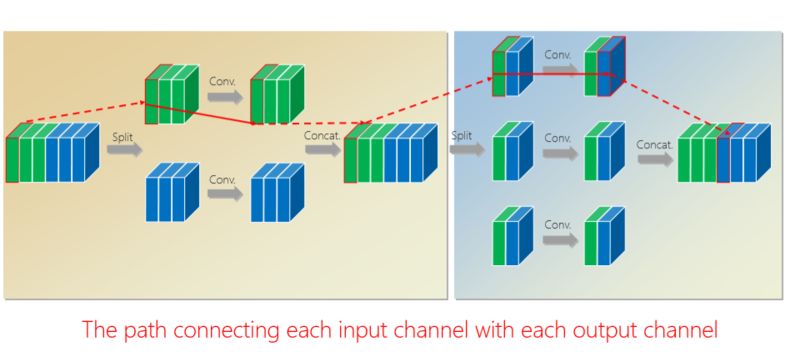
有什么好处?通过第二组的组卷积可以达到互补的条件,或者使得任何一个 output(输出通道)和任何一个 input(输入通道)连起来。

这里面我们引进了一个严格的互补条件,直观来讲就是,如果有两个通道在第一组卷积里面,落在同一个 Branch(分支),我希望在第二组里面落在不同的 Branch(分支)。第二组里面比如一个 Branch(分支)里面的若干个通道,要来自于第一个组卷积里面的所有 Branches(分支),这个称为互补条件。这个互补条件带来什么?它会带来(任何一对输入输出通道之间存在) path,也就是说相乘矩阵是密集矩阵。为什么称之为“严格的”?就是任何一个 input 和 output 之间有一条 path,而且有且只有一条path。

严格的准则引进来以后,参数量变小了、模型变小了,带来什么好处?这里我给一个结论,L 是(第)一个组卷积里面的 partitions(分支)的数目或者卷积的数目,M是第二组组卷积卷积的数目,S 是卷积核的大小,通常都是大于 1 的。这样的不等式几乎是恒成立的,这个不等式意味着什么?结论是:如果跟普通标准的卷积去比,通过我们的设计方式可以让网络变宽。跟网络变深相比起来,网络变宽是另外一个维度,变宽有什么好处?会不会让结果变好?我们做了一些实验。
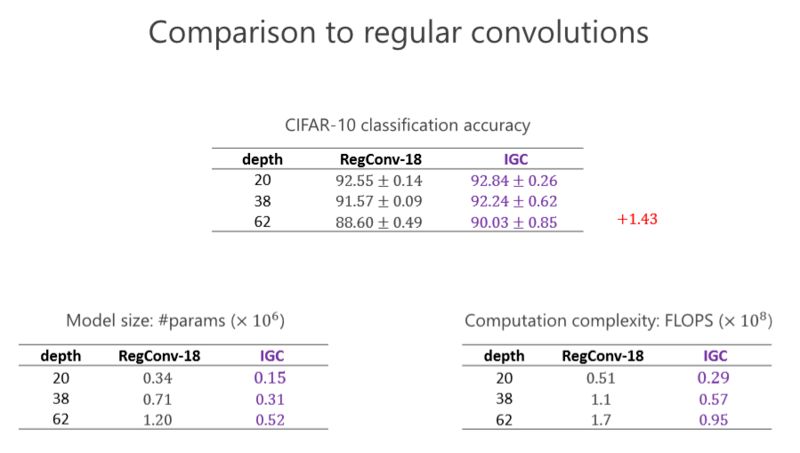
这个实验是跟标准的卷积去比,大家看看左下角的表格,这个表格是参数量,我们设计的网络几乎是标准(卷积)参数量的一半。然后看看右下角这个网络,我们的的计算量几乎也是一半。在 CIFAR-10 标准的图像分类数据集里(上面的表格),我们的结果比前面的一种好。我们甚至会发现越深越好,在 20 层有些提升并没有那么明显,但深的时候可以达到 1.43 的提高量。
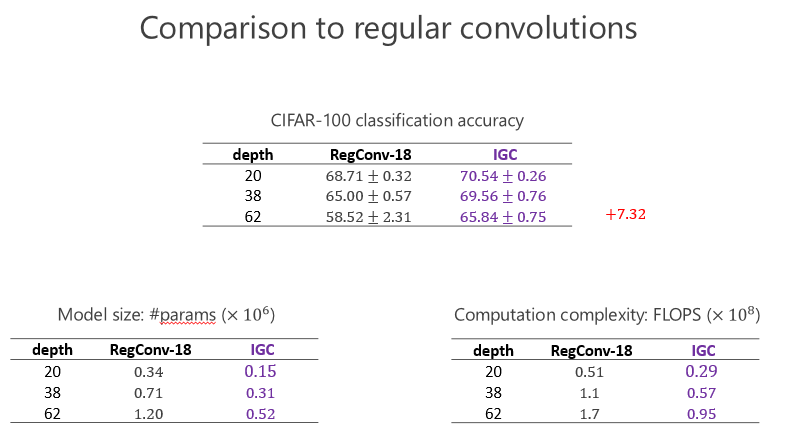
后来 CIFRA-100 我们也做了同样的实验,发现我们提升仍然是一致的,甚至跟前面的比起来提高得更大,因为分 100 类比分 10 类困难一点,说明越困难的任务,我们的优势越明显。这个变宽了以后(性能)的确变好了,通过 IGC 实现,网络结构变宽的确会带来好处。
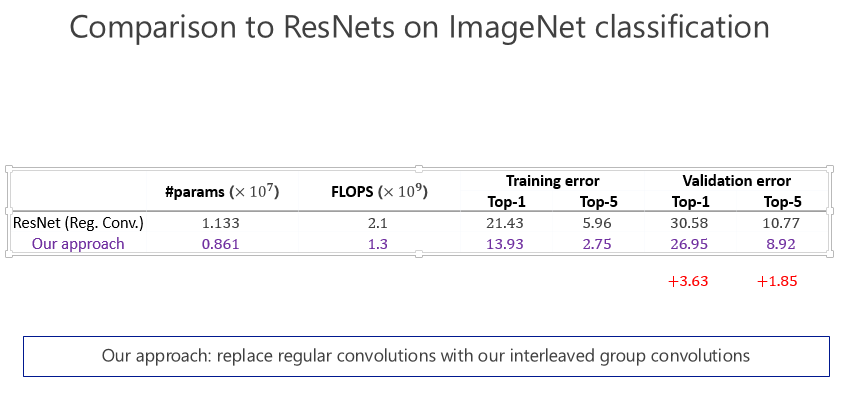
这是两个小的数据集,其实在计算机视觉领域里小数据集上的结果是不能(完全)说明问题的,一定要做非常大的数据集。所以我们当时也做了 ImageNet 数据集,跟 ResNet 比较了一下,参数量少了近五分之二,计算量小了将近一半了,错误率也降低了,这证明通过 IGC 的实现,让模型变宽,在大的网络模型上取得非常不错的效果。
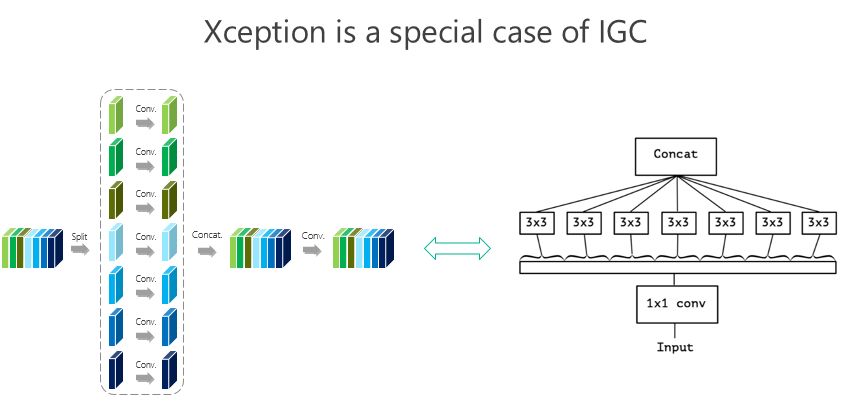
我们大概是前年 8、9 月份开始做这个事情,10 月份发现 Google 有一个工作是 Xception,这个是它的结构图,这个形式非常接近(我们的结构),跟我们前面所谓的 IGC 结构非常像,实际上就是我们的一个特例。当时我们觉得这个特例有没有可能结果最好,所以我们做了些验证,整体上我们结构好一点。
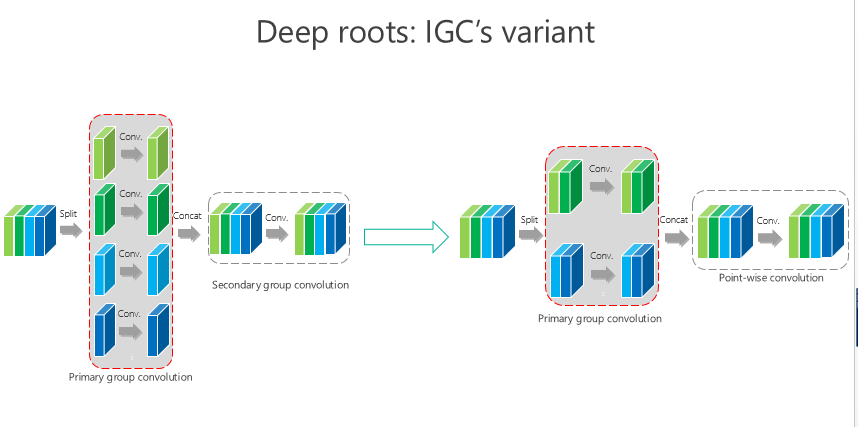
IGC 可能还有变体,比如我要是把这个 channel-wise 也变成组卷积,第二个是 1×1 的,这样的结果会怎样?我们做了类似同样的实验,仍然发现我们的方法是最好的。
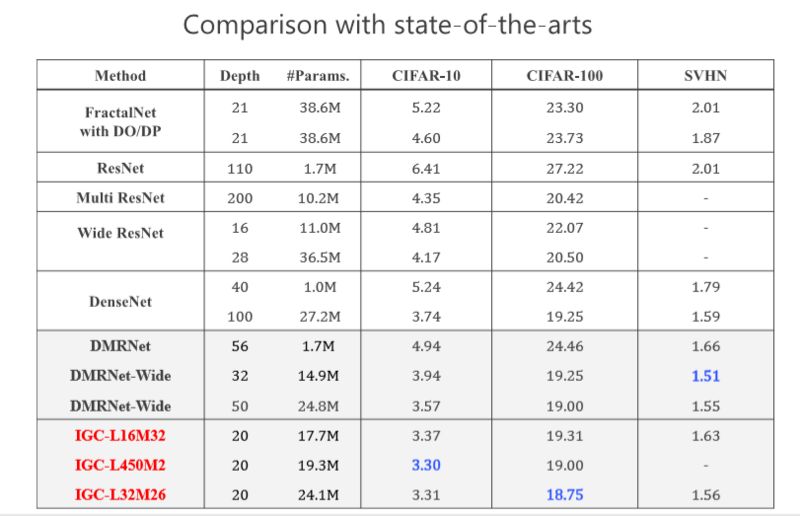
当时我们做的时候,希望在网络结构上跟 state-of-the-arts 的方法去比较,我们取得了非常不错的结果,当时我们的工作是希望通过消除冗余性提高模型性能或者准确率。
▌IGCV2
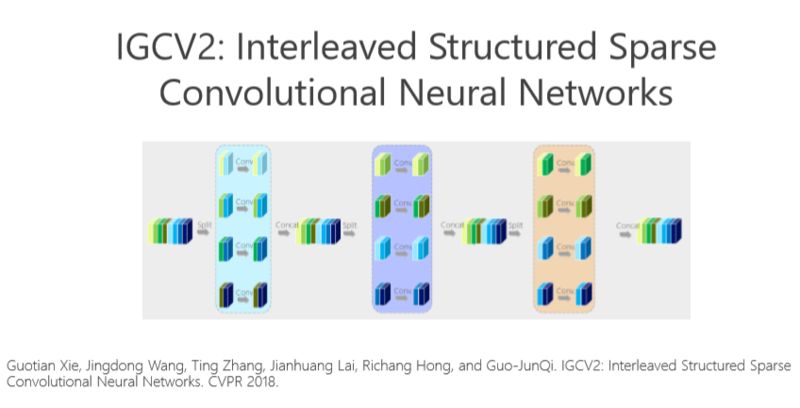
后来我们尝试利用消除冗余性带来的好处,把这个模型部署到手机上去。我们去年又沿着这个方向继续往前走,把这个问题理解得更深,希望进一步消除冗余性。
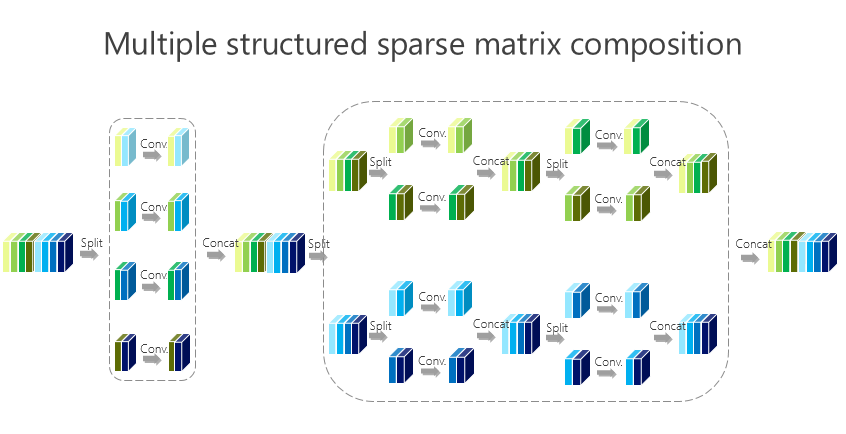
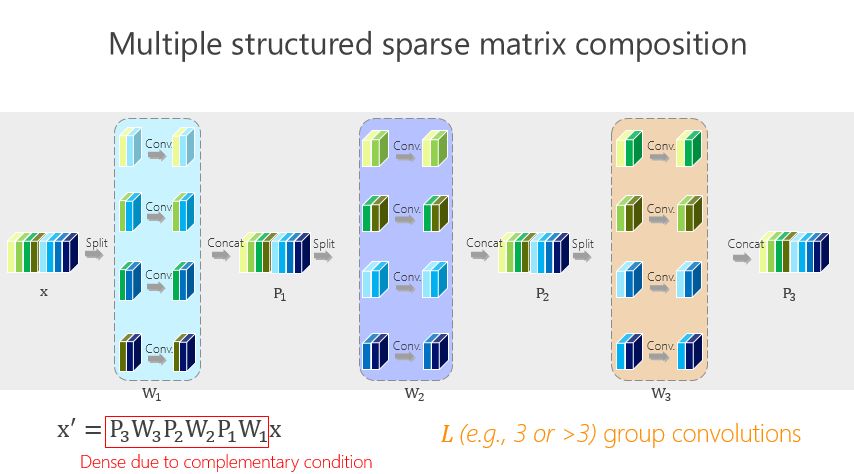
这个讲起来比较直接或简单一点,前面的网络结构是两个组卷积或者两个矩阵相乘得到的,我们有没有办法变得多一点?实际上很简单,如上图所示。

这种方法带来的好处很直接,就是希望参数量尽量小,那怎么才能(使)参数量尽量小?我们引进了所谓的平衡条件。虽然这里面我们有 L-1 个 1×1 的组卷积,但 L-1 个 1×1 的组卷积之间有区别吗?谁重要一点、谁不重要一点?其实我们也不知道。不知道怎么办?就让它一样。一样了以后,我们通过简单的数学推导就会得出上面的数学结果。
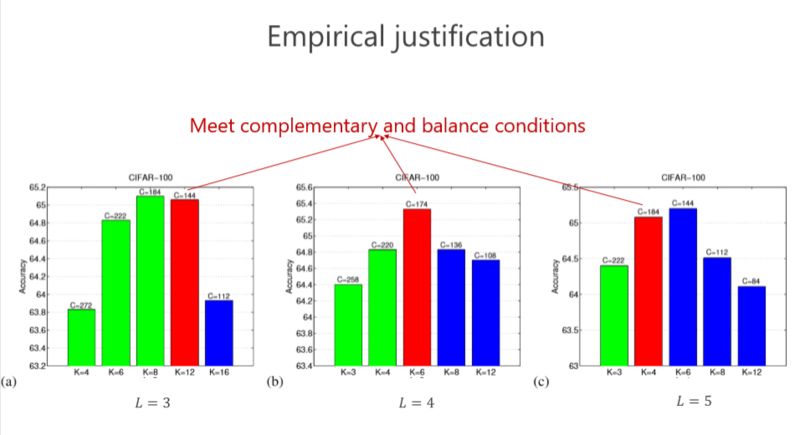
现在再验证一下,前面讲了互补条件、平衡条件,那这个结果是不是最好的?或者是不是有足够的优势?我们做了些实验,这个红色的是对应满足我们条件的,发现这个情况下(L=4)结果是最好的。其实是不是总是最好?不见得,因为实际问题跟理论分析还是有点距离。但我们总体发现基本上红色的不是最好也排在第二,说明这种设计至少给了我们很好的准则来帮助设计网络结构。这个虽然不总是最好的,但和最好的是差不多的。

第二个问题,我们究竟要设计多少个组卷积(L 设成多少)?同样我们的准则也是通过参数量最小来进行分析,以前是两个组卷积,我们可以通过 3 个、4 个达到参数量更小,但其实最终的结论发现,并不是参数量最优的情况下性能是最好的。
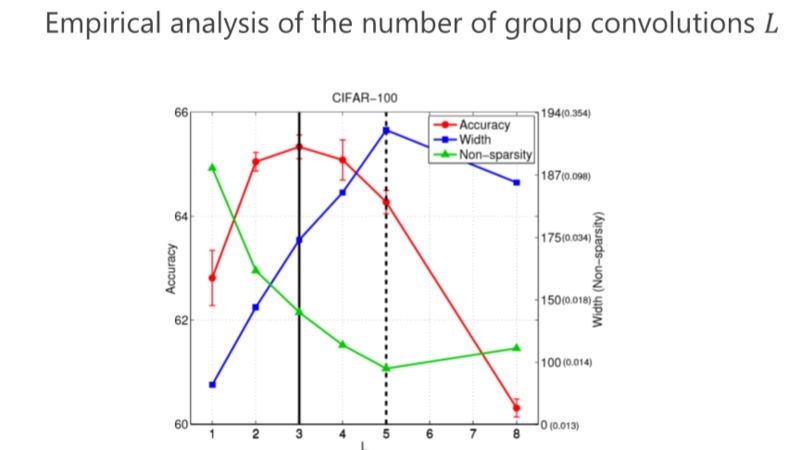
▌IGCV3

后来我们发现,如果遵循严格互补条件,模型的结构变得非常稀疏、非常宽,结果不见得是最好的。所以我们变成了 Loose。Loose 是什么意思?以前 output(输出通道)和 input (输入通道)之间是有且只有一个 path,我们改得非常简单,能不能多个path?多个 path 就没那么稀疏了,它好处在于每个 output (输出通道)可以多条路径从 input (输入通道)那里拿到信息,所以我们设计了 Loose condition。

实际上非常简单,我们就定义两个超级通道(super-channels)只能在一个 Branch 里面同时出现,不能在两个 Branch 里同时出现,来达到 Loose condition。
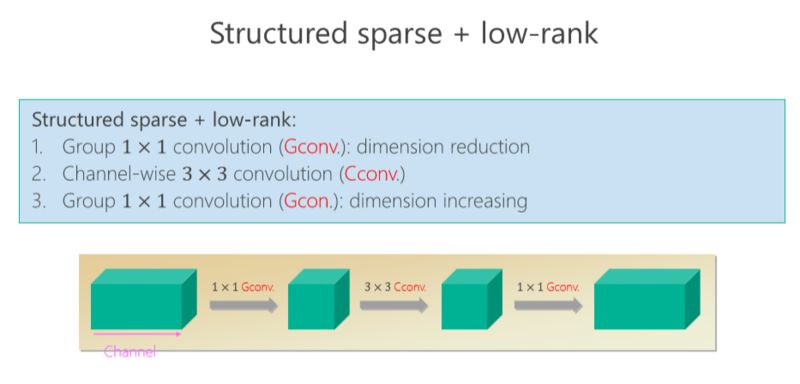
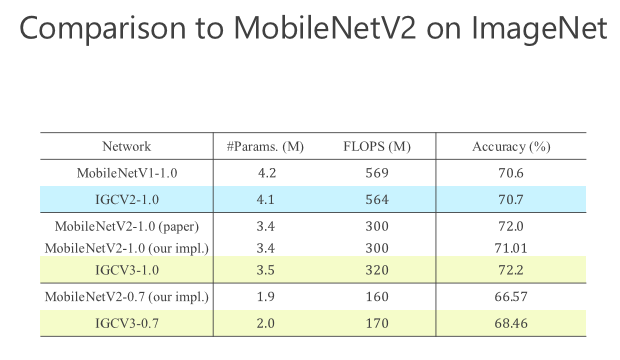
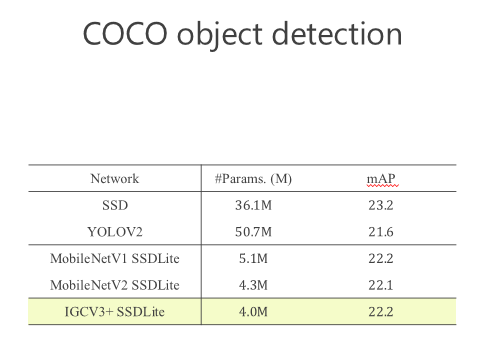
后来我们进一步往前走,把 structured sparse 和 low-rank 两个组起来。我们在 ImageNet 上比较,同时跟 MobileV2 去比,在小的模型我们优势是越来越明显的。比较结果,见下图。

这就是今天的主要内容,这个工作是我跟很多学生和同事一起做的,前面这5个是我的学生,Ting Zhang现在在微软研究院工作,Bin Xiao 是我的同事,Guojun Qi 是美国的教授,我们一起合作了这篇文章。
-
什么是卷积码? 什么是卷积码的约束长度?2008-05-30 20177
-
【我是电子发烧友】如何加速DNN运算?2017-06-14 5241
-
CNN之卷积层2018-10-17 4423
-
卷积神经网络入门资料2019-02-12 4394
-
详解时间交错技术2019-07-23 1141
-
计算卷积的方法有哪些2020-06-04 1516
-
可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别2021-07-26 3816
-
卷积码,卷积码是什么意思2010-03-19 2317
-
卷积码,什么是卷积码2010-04-03 7721
-
什么是DNN_如何使用硬件加速DNN运算2018-07-08 23603
-
浅谈卷积编码在通信中的应用 详解卷积编码设计应用2018-08-21 9611
-
详解卷积神经网络卷积过程2019-05-02 19443
-
卷积神经网络详解 卷积神经网络包括哪几层及各层功能2023-08-21 8024
-
AI芯片设计DNN加速器buffer管理策略2023-10-17 2684
-
基于FPGA进行DNN设计的经验总结2024-04-07 1320
全部0条评论

快来发表一下你的评论吧 !
