

如何简单快速的来打造MCU性能分析利器的详细资料概述
电子说
描述
说出来不确定大家信不信,实现起来也就70来行算上大括号的代码,是不是很激动人心?
言归正传,再小的程序,也是数据结构+代码。咱们先来由表及里地看看核心数据结构的样子。
首先,既然要从Cortex-M核在响应中断时自动入栈的信息采集PC,就必须了解自动入栈了些啥东东:

这里可以看出Cortex-M内核自动压入了8个寄存器,右二那个不起眼的pc,正是一号主角。对自动入栈不太了解的小伙伴,可以查看《Cortex-M3权威指南》第9章的介绍
(https://github.com/RockySong/cm3_def_guide_cn)
理论上pc可以是任何指令位置。不幸的是一般工程生成的指令数常常在几万甚至几十万条,难道都要记录下来?估计天价的开发工具也不会这么做。常言说“首恶必办,协从不问”,咱们做profiling,也没必要统计出PC在所有指令上的分布密度,只要抓几个大头就够了。还有个麻烦的,是一个函数可以有多个指令,函数长度可以相差巨大,而且在一个大函数里不同区域的覆盖密度也不同。过日子还需要精打细算呀,咱们权衡打击精度与弹药消耗量,使用2个宏来决定配置,比如:

第1个宏PROF_CNT决定了抓多少个大头,第2个宏PROF_ERR决定了网眼的大小——抓取的地址范围(也就是最大误差),在这个范围内的地址都计作同一个地址块。显然,PROF_CNT越多,PROF_ERR越小,抓取的就越多越精确,也就更接近高档的分析工具。值得一表的是,如果PROF_ERR够小,可以在较大的函数中抓出更消耗性能的位置。
第3个宏PROF_MASK又是什么鬼?这其实是个工具宏,用来把地址向下对齐到误差范围的边界,这也意味着PROF_ERR必须是2的整数次幂,这么做是避免消耗性能的取模运算。
下面请出关键的数据结构:性能分析的PC统计单元:

很显然,PROF_CNT是多少,就应该有多少个ProfUnit_t实例。结构中,hitCnt是关键的参数,它统计了这个对齐后的PC地址”baseAddr”被采集到了多少次,”hitRatio”则是一个对人类友好的辅助变量,提供千分数(其实是1024级)精度的CPU占用率。
此外,还有个非常有用的小细节。比如,小伙伴们可能也注意到了,CPU占用率也是有时效性的。就像一个漫长的初始化可能让一些查询等待的函数红极一时,但在之前越是弄得满城风雨,程序主体运行后往往越是无声无息,甚至都没机会再运行一遍。
而即使在正常运行期间,不同时段开启的功能不同,常常出现“皇帝轮流做,明年到我家”。因此,咱们可以加一点衰减处理,也就是定期对于非0的hitCnt进行扣除一格,如果没有后续源源不断的再次命中,就会渐渐走下神坛直至跌出排行榜。这样可以提高统计结果的实时性。衰减机制的思路也很简单,就是轮流从hitCnt非0的各个PC样本点去扣。
综合上面的如意算盘,定义了如下统领全局的结构体:
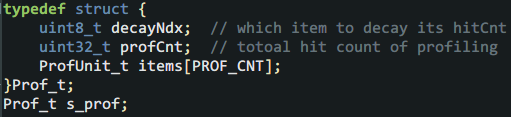
这个结构里decayNdx表示下次统计时从谁身上扣除hitCnt,每一次扣除后就轮转到后面的item上,以公平公正。profCnt则表示已经做了多少次profiling统计,用于计算命中率,而items则是上文介绍的PC样本统计单元。这里也有个小细节,就是在应用衰减来扣除每个item的hitCnt时,profCnt也需要扣除。
好了,有了完整的数据结构,该写代码了。从易到难,咱们可以先处理命中时的动作。
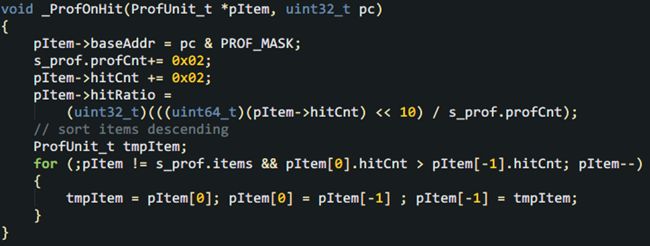
代码很简单,记录地址,增加hitCnt,计算hitRate,再实时地“冒泡”,把最多hitCnt的item顶上去,排序的目的也是为了便于突出重点,对人类查看友好。这里每次hitCnt加2,是为了让衰减得没有增加的快,“过气”得缓慢点,小伙伴们可以根据需要调节增加量。
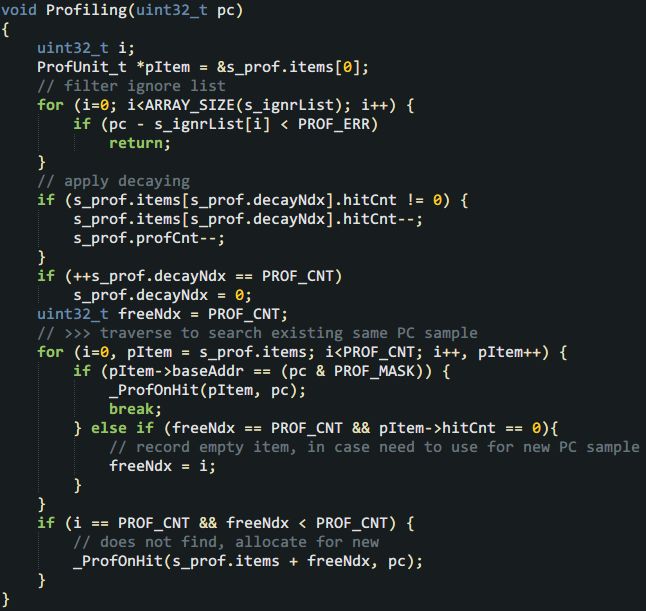
再剩下的就是最复杂的主函数了——说是复杂也就不到40行的代码。要在主函数里先应用衰减,然后检查这次的PC样本是否已有记录。如有记录就调用上面的_ProfOnHit(),如无记录则在一个hitCnt为0的item上记录这个新PC样本,也是调用_ProfOnHit()。此外,为了避免把idle函数和一些不想关心的函数也记录下来,程序还支持一个“忽略列表”,凡是位于忽略列表地址范围的PC样本都不理会。
大功告成!接下来就是要使用了。使用非常简单,只需在定时器中断服务程序的主体中调用Profiling()并告诉它进入定时器中断时pc寄存器的值。为了获取入栈的PC,这个需要一点Cortex-M的基础知识和手写汇编。下面给出KEIL下的汇编入口:
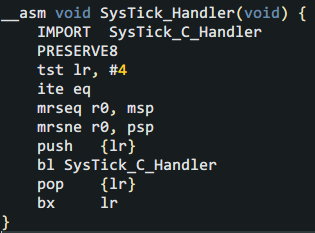
这个小程序先查出中断前使用的栈指针并以作为参数传递给C语言主体“SysTick_C_Handler”。如果小伙伴们对这段汇编看不明白,就直接用就可以。
C语言主体的使用方式如下:

在使用的时候,咱们就进入开发工具的调试会话,让程序跑一会,再停下来。如果是在KEIL或IAR中,可以使用memory窗口或watch窗口观察s_prof.items。如果使用了GDB,可以输入命令 p/a s_prof.items。查看排名靠前的item,对照map文件即可估计出函数的名字和大致位置。值得一表的是,GDB下会自动解析出地址所对应的函数名,不用再让咱们手动查map,非常贴心!
回顾理论篇介绍的几个小坑,当查到一个不合理的地址时,先别激动,看看是不是小坑中的之一。如果确定不是,就有必要深入处理了。
到了这里,这期性能分析的话题的理论和实践的故事就讲完了。
等等,似乎还有什么没交待完。试想,当我们一一找出最耗CPU资源的函数后,倘若束手无策,那也是徒劳无功,我们必须有对付他们的办法。其中一项省力而又见效快的办法就是把它们放在执行性能更高的位置中去,也就是前面说的VIP区。下次,咱们就介绍一下各种VIP区的特点,以及升V的方法!敬请继续关注!
-
9013流水灯的介绍和设计详细资料概述2018-06-05 1218
-
如何修改Muto软件来运行自己的StaseSimo Foc板的详细资料概述2018-05-31 994
-
如何利用LM3447来进行非隔离调光GU10电源的详细资料图解概述2018-07-18 1231
-
如何运用TI的LM3447来设计7W可调光LED球泡灯Demo的详细资料概述2018-07-18 1096
-
PID程序算法的详细资料概述免费下载2018-07-24 977
-
SV601187的详细资料合集包括了电路图,原理图和介绍等详细资料概述2018-07-30 1487
-
如何使用万用表简单判断旋转编码器?的详细资料概述2018-09-10 2156
-
数字系统设计与PLD应用答案的详细资料概述2018-10-22 1456
-
LabVIEW串口写入和读取详细资料概述2019-01-02 1441
-
逆变器的原理和详细资料概述2019-01-07 3296
-
开关电源环路补偿的详细资料概述2019-11-06 1798
-
python的内置函数详细资料概述2019-11-18 965
-
CAN总线基础的详细资料概述2019-11-29 1865
-
PLC编程电缆制作大全详细资料概述2020-04-26 1213
-
EMC HF垫圈的详细资料概述2020-09-07 1052
全部0条评论

快来发表一下你的评论吧 !
