

Python也有这么强大的用处哦!用Python脚本自助抢课
描述
最近学校开始选课,但是如果选课时间与自己的事情冲突,这时候就可以使用Python脚本自助抢课,抢课的第一步即是模拟登录,需要模拟登录后保存登录信息然后再进行操作。
而且整个流程是比较简单,这是因为正方教务系统是比较旧的,全文的IP地址部分遮挡,请换成你们学校的IP地址。
尝试登录
首先我们打开学校的教务系统,随便输入,然后提交表单,打开Chrome的开发者工具中的Network准备抓包
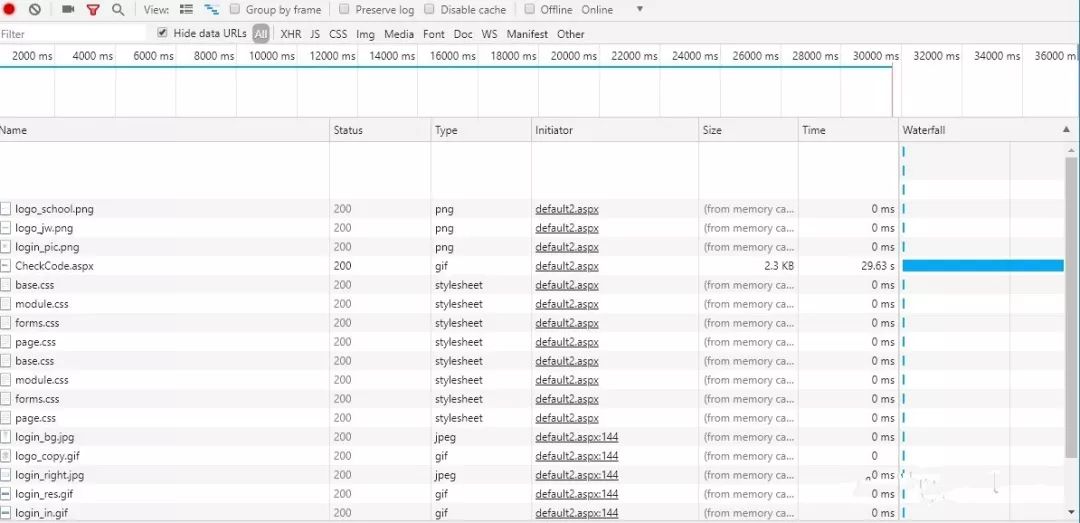
把css 图片之类的过滤掉,发现了default.aspx这个东西
如果你们学校教务系统不使用Cookie则会是这样
我们可以发现,真实的请求地址为 http://110.65.10.xxx/(bdq1aj45lpd42o55vqpfgpie)/default2.aspx
随后我们发现这个网址括号围起来的一串信息有点诡异,而且每次进入的时候信息都不一样,经过资料查询,这是一种http://ASP.NET不使用Cookie会话管理的技术。
不使用 Cookie 的 ASP.NET 会话管理
那这样就很好办了,我们只需要登录时记录下这个数据即可保持登录状态。
经过测试发现,我们可以随便伪造一个会话信息即可一直保持登录状态,但是为了体现模拟登录的科学性,我们需要先获取该会话信息。
如果你们学校教务系统使用Cookie则会是这样
服务器会返回一个Cookie值,然后在本地保存,这与下面的会不相同。
获取会话信息(不使用Cookie)
这里我们要使用requests库,并且要伪造header的UA信息
经过测试发现,我们只访问学校的IP地址,会自动重定向至有会话信息的网址,所以我们先访问一下IP地址。
classSpider:
def __init__(self, url):pp
self.__uid = ''
self.__real_base_url = ''
self.__base_url = url
self.__headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
}
def __set_real_url(self):
request = requests.get(self.__base_url, headers=self.__headers)
real_url = request.url
self.__real_base_url = real_url[:len(real_url) - len('default2.aspx')]
return request
上面获取的url即为带有会话信息的网址,保存的url格式为
your_ip/(bdq1aj45lpd42o55vqpfgpie)/
保存为这样的格式是因为我们要访问其他地址
获取会话信息(使用Cookie)
有些学校的教务系统是使用Cookie的,我们只需要首次get请求时保存Cookie即可,然后此后一直使用该cookie
def get_cookie():
request = requests.get('http://xxx.xxx.xxx.xxx') #以某教务系统为例子
cookie = requets.cookie
return cookie
而requests中使用Cookie很简单
只需要这样
def use_cookie(cookie):
request = requests.get('http://xxx.xxx.xxx.xxx',cookie=cookie)
由于我们学校采用的是无Cookie方案,所以下面的代码均没有发送Cookie,如果你的学校采用了Cookie,只需要像我上面这样发送Cookie就行了。
而如果你们学校使用Cookie,就不必获取带有会话信息的地址了,直接存储Cookie即可。
验证码的处理
分析r返回的文本信息
发现验证码的标签的资源地址为 src="CheckCode.aspx" ,我们可以直接requests然后下载验证码图片,下载图片的一种优雅的方式如下
def __get_code(self):
request = requests.get(self.__real_base_url + 'CheckCode.aspx', headers=self.__headers)
with open('code.jpg', 'wb')as f:
f.write(request.content)
im = Image.open('code.jpg')
im.show()
print('Please input the code:')
code = input()
return code
上面的代码把图片保存为code.jpg,Python有一个Image模块,可以实现自动打开图片
这样验证码就展示出来了,我们人工输入或者转入打码平台皆可
登录数据的构造
这是上面抓的登录post的数据包,
发现有信息无法被解码,应该是gb2312编码,查看解码前的编码
然后将不能解码的代码复制能够解码的地方
发现%D1%A7%C9%FA编码解码后为学生
这也就对应了学生选项的登录
学号和密码和验证码能够显而易见地知道是哪些信息,但是我们发现有__VIEWSTATE这一项
查找一下,这是一个表单隐藏信息,我们可以用BeautifulSoup库解析可以得出该一项数据的值
这是完整的登录数据包,
def __get_login_data(self, uid, password):
self.__uid = uid
request = self.__set_real_url()
soup = BeautifulSoup(request.text, 'lxml')
form_tag = soup.find('input')
__VIEWSTATE = form_tag['value']
code = self.__get_code()
data = {
'__VIEWSTATE': __VIEWSTATE,
'txtUserName': self.__uid,
'TextBox2': password,
'txtSecretCode': code,
'RadioButtonList1': '学生'.encode('gb2312'),
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': '',
}
return data
登录
如果登录完成了,如何判断是否登录成功呢?我们从登录成功返回的界面发现有姓名这一标签,而我们等一下也是需要学生姓名,所以我们用这个根据来判断是否登录成功。
代码如下,进行了验证码用户名和密码的提示信息判别
def login(self,uid,password):
whileTrue:
data = self.__get_login_data(uid, password)
request = requests.post(self.__real_base_url + 'default2.aspx', headers=self.__headers, data=data)
soup = BeautifulSoup(request.text, 'lxml')
try:
name_tag = soup.find(id='xhxm')
self.__name = name_tag.string[:len(name_tag.string) - 2]
print('欢迎'+self.__name)
except:
print('Unknown Error,try to login again.')
time.sleep(0.5)
continue
finally:
returnTrue
获取选课信息
接下来就是获取选课信息了,这里我们以校公选课为例子,点击进去,进行抓包,headers没有什么好注意的,我们只用关注get发送的包即可

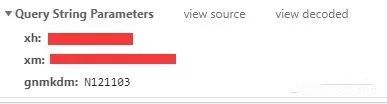
发现有学号与姓名与gnmkdm这一项,姓名我们需要编码为gb2312的形式才能进行传送
这里我们注意headers需要新增Referer项也就是当前访问的网址,才能进行请求
def __enter_lessons_first(self):
data = {
'xh': self.__uid,
'xm': self.__name.encode('gb2312'),
'gnmkdm': 'N121103',
}
self.__headers['Referer'] = self.__real_base_url + 'xs_main.aspx?xh=' + self.__uid
request = requests.get(self.__real_base_url + 'xf_xsqxxxk.aspx', params=data, headers=self.__headers)
self.__headers['Referer'] = request.url
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
注意到上面有一个设置VIEWSTATE值的函数,这里等下在选课构造数据包的时候会讲
模拟选课
随便选一门课,然后提交,抓包,看一下有什么数据发送
前三个值可以在原网页中input标签中找到,由于前两项为空,就不获取了,而第三项我们使用soup解析获取即可,由于这个操作是每请求一次就变化的,我们写成一个函数,每次请求完成就设置一次。
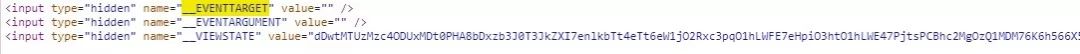
def __set__VIEWSTATE(self, soup):
__VIEWSTATE_tag = soup.find('input', attrs={'name': '__VIEWSTATE'})
self.__base_data['__VIEWSTATE'] = __VIEWSTATE_tag['value']
而其他数据,我们通过搜索响应网页就可以知道他们是干什么用的,这里我只说明我们要用的数据。
TextBox1为搜索框数据,我们可以用这个来搜索课程,dpkcmcGrid:txtPageSize为一页显示多少数据,经过测试,服务器最多响应200条。
值得注意的是ddl_xqbs这个校区数据信息,我所在的校区的数字代号为2,也许不同学校设置有所不同,需要自己设置一下,也可以从网页中获取
下面是基础数据包,由于我们搜索课程与选择课程都要使用这个基础数据包,所以我们直接在init函数里面新增
self.__base_data = {
'__EVENTTARGET': '',
'__EVENTARGUMENT': '',
'__VIEWSTATE': '',
'ddl_kcxz': '',
'ddl_ywyl': '',
'ddl_kcgs': '',
'ddl_xqbs': '2',
'ddl_sksj': '',
'TextBox1': '',
'dpkcmcGrid:txtChoosePage': '1',
'dpkcmcGrid:txtPageSize': '200',
}
然后我们关注一下这条数据,我们搜索一下,发现这是课程的提交选课的代码,所以我们也可以直接从网页中获取,而on表示选项被选上

kcmcGrid:_ctl2:xk:'on'
搜索课程
课程有很多信息,比如名字,上课时间,地点,这些东西确定好了才知道选的是哪门课,所以我们先新建一个类来存储信息
classLesson:
def __init__(self, name, code, teacher_name, Time, number):
self.name = name
self.code = code
self.teacher_name = teacher_name
self.time = Time
self.number = number
def show(self):
print('name:' + self.name + 'code:' + self.code + 'teacher_name:' + self.teacher_name + 'time:' + self.time)
有了这个类,我们就可以进行搜索课程了,具体代码看下面代码,解析网页内容就不细讲了。
def __search_lessons(self, lesson_name=''):
self.__base_data['TextBox1'] = lesson_name.encode('gb2312')
request = requests.post(self.__headers['Referer'], data=self.__base_data, headers=self.__headers)
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
returnself.__get_lessons(soup)
def __get_lessons(self, soup):
lesson_list = []
lessons_tag = soup.find('table', id='kcmcGrid')
lesson_tag_list = lessons_tag.find_all('tr')[1:]
for lesson_tag in lesson_tag_list:
td_list = lesson_tag.find_all('td')
code = td_list[0].input['name']
name = td_list[1].string
teacher_name = td_list[3].string
Time = td_list[4]['title']
number = td_list[10].string
lesson = self.Lesson(name, code, teacher_name, Time, number)
lesson_list.append(lesson)
return lesson_list
进行选课
选课我们只要将lesson_list传入即可,这就是我们之前创建的Lesson类的实例的列表,'Button'的内容为' 提交 ',这两边各有一个空格,完事后我们可以进行发送请求进行选课。
这里我们用正则提取了错误信息,比如选课时间未到、上课时间冲突这些错误信息来提示用户,我们还解析了网页的已选课程,这里也不细讲了,都是基础的网页解析。
def __select_lesson(self, lesson_list):
data = copy.deepcopy(self.__base_data)
data['Button1'] = ' 提交 '.encode('gb2312')
for lesson in lesson_list:
code = lesson.code
data[code] = 'on'
request = requests.post(self.__headers['Referer'], data=data, headers=self.__headers)
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
error_tag = soup.html.head.script
ifnot error_tag isNone:
error_tag_text = error_tag.string
r = "alert('(.+?)');"
for s in re.findall(r, error_tag_text):
print(s)
print('已选课程:')
selected_lessons_pre_tag = soup.find('legend', text='已选课程')
selected_lessons_tag = selected_lessons_pre_tag.next_sibling
tr_list = selected_lessons_tag.find_all('tr')[1:]
for tr in tr_list:
td = tr.find('td')
print(td.string)
总结
这次我们完成了模拟正方教务系统选课的过程,由于这个教务系统技术比较陈旧,所以比较好弄,事实上抢课的时候用Fiddler即可完成操作,因为我们只需要提前登录然后记录网址即可。
由于不同学校的正方教务系统有可能不同,所以上面很多细节都是需要修改的。
-
基于Python脚本的R语言的函数2020-10-12 2575
-
Python能做什么?自学Python获得人生的第一桶金经验分享2021-01-04 4131
-
10个杀手级的Python自动化脚本2022-11-28 951
-
Python这么火,那有啥优势呢?2018-05-09 5275
-
python写一个建模的脚本-微带天线的模型建立与仿真的过程搞定了2021-02-19 8067
-
如何在 IIS 中执行 Python 脚本2010-02-23 1482
-
matlab如何调用python脚本文件,路径是怎样的2017-12-04 8354
-
如何使html网页与python脚本进行通信2019-11-04 8284
-
如何使用Python和HFSS的联合仿真实现微带天线的设计2020-11-17 1314
-
Python也太强大了吧2020-12-23 1850
-
【Python】如何将Python脚本打包成exe可执行文件2022-08-18 19367
-
Python怎么玩转JS脚本2023-02-23 1897
-
使用Python脚本实现自动化运维任务2023-04-08 2344
-
如何在Linux命令行中运行Python脚本2023-05-12 2529
-
用python写验证环境cocotb2024-07-24 1387
全部0条评论

快来发表一下你的评论吧 !
