

深入浅出的介绍了深度学习的理论——用理论的力量横扫深度学习!
电子说
描述
目前深度学习的应用较为广泛,尤其是各种开源库的使用,导致很多从业人员只注重应用的开发,却往往忽略了对理论的深究与理解。普林斯顿大学教授Sanjeev Arora近期公开的77页PPT,言简意赅、深入浅出的介绍了深度学习的理论——用理论的力量横扫深度学习!(文末附PPT下载地址)
深度学习历史
学习任何一门知识都应该先从其历史开始,把握了历史,也就抓住了现在与未来 。——BryanLJ
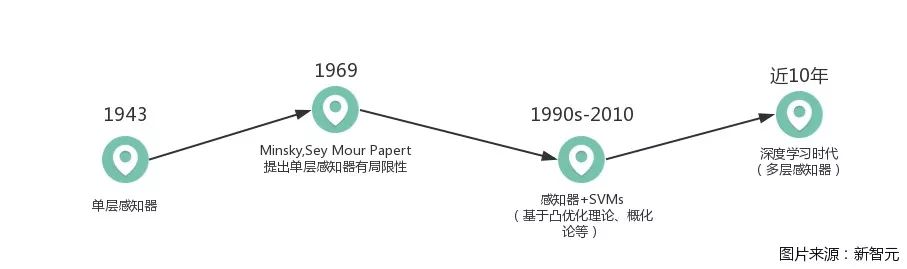
由图可以简单看出深度学习的发展历史,在经历了单调、不足与完善后,发展到了如今“动辄DL”的态势。
定义与基本概念
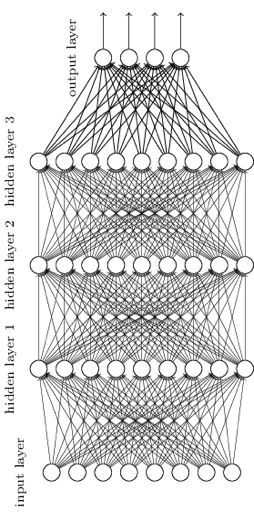
神经网络基本结构图:
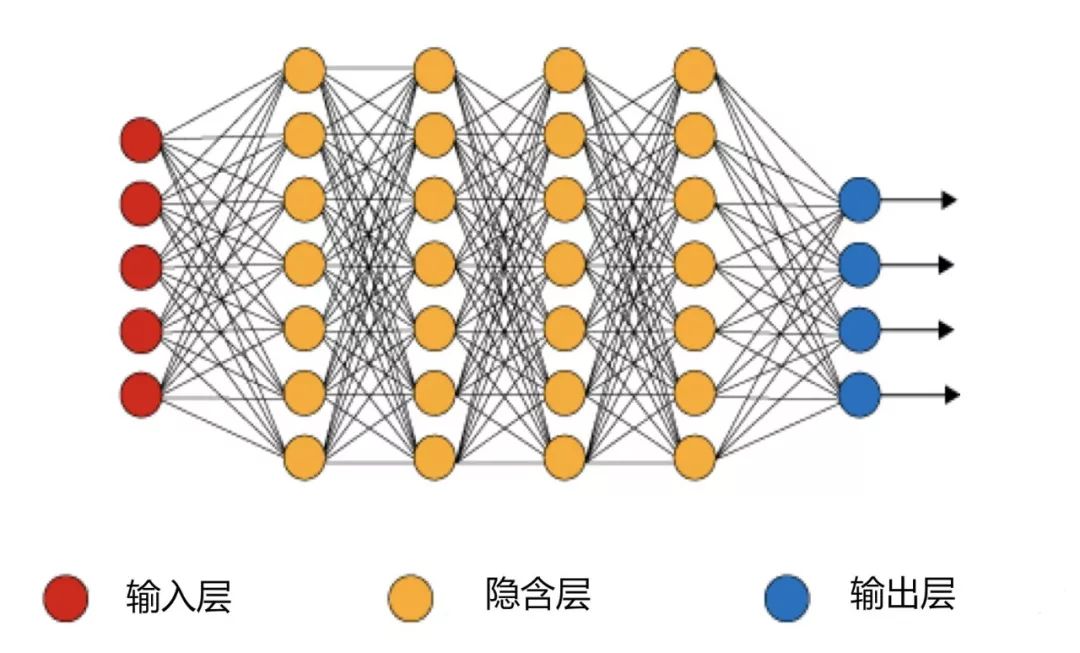
定义:
θ:深度网络的参数
训练集:(x1, y1) ,(x2, y2) ,…,(xn, yn)
损失函数 ζ(θ,x,y):表示网络的输出与点x对应的y的匹配度
目标: argminθEi[ζ(θ,x1, y1)]
梯度下降:
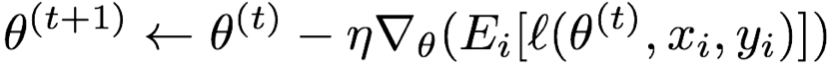
结合GPUs、大型数据集,优化概念已经塑造了深度学习:
反向传播:用线性时间算法来计算梯度;
随机梯度下降:通过训练集的小样本评估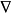
梯度、解空间推动形成了残差网络(resnet)、WaveNet及Batch-Normalization等;
理论的目标:通过整理定理,得出新的见解和概念。
深度学习中的优化
困难:深度学习中大多数优化问题是非凸(non-convex)的,最坏的情况是NP难问题(NP-hard)。
维数灾难:指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象
深度学习“黑盒”分析:
原因:
1、无法确定解空间;
2、没有明确的(xi, yi) 数学描述;
所以,求全局最优解是不可行的。
未知解空间中的控制梯度下降:
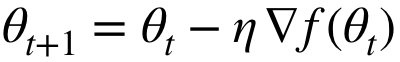
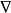 ≠0→∃下降方向,但如果二阶导数比较高,允许
≠0→∃下降方向,但如果二阶导数比较高,允许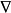 波动很大。为了确保下降,采用由平滑程度
波动很大。为了确保下降,采用由平滑程度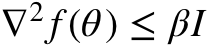 (可由高斯平滑 f来定义)决定的小步骤。
(可由高斯平滑 f来定义)决定的小步骤。
平滑:
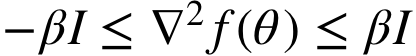
要求: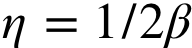 满足
满足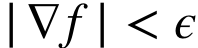 且与
且与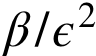 成正比。
成正比。
非“黑盒”分析:
很多机器学习问题是深度为2的子案例,例如,输入层和输出层之间的一个隐含层。通常假设网络的结构、数据分布,等等。比起GD/SGD,可以使用不同算法,例如张量分解、最小化交替以及凸优化等等。
过度参数化(over-parametrization)和泛化(generalization)理论
教科书中说:大型模型会导致过拟合
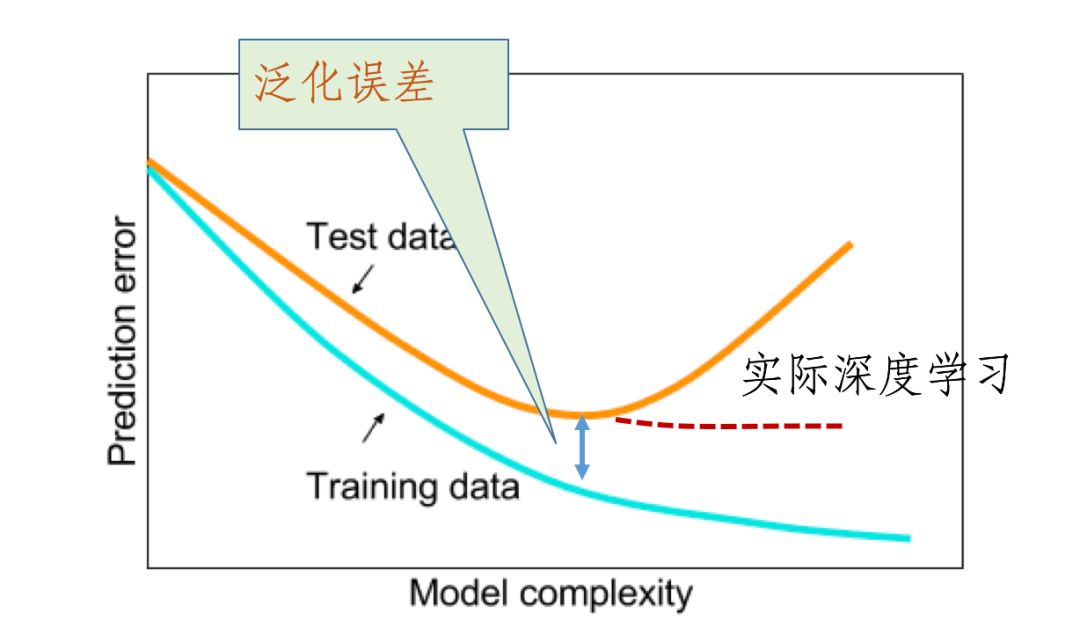
很多人认为:SGD +正则化消除了网络的“过剩容量”(excess capacity),但是过剩容量依旧还是存在的,如下图所示:
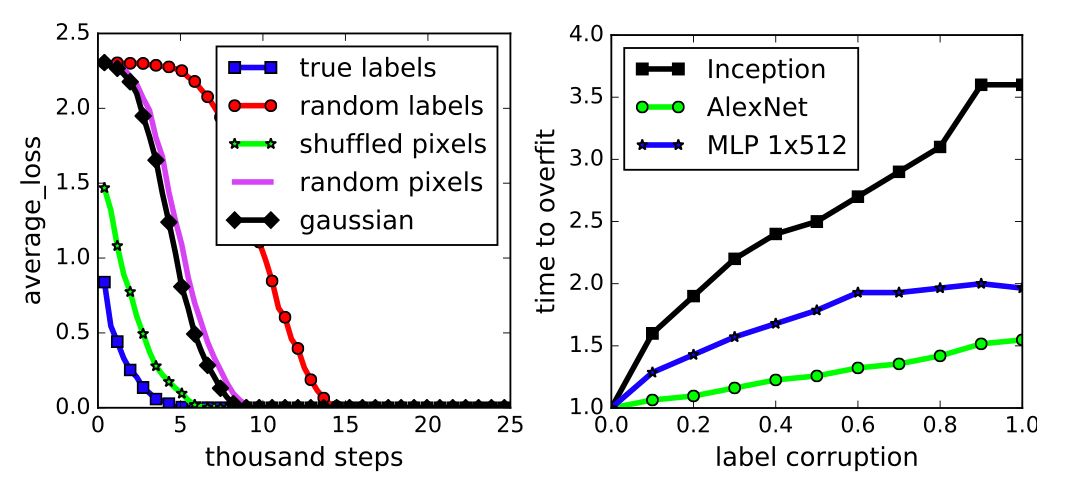
事实上,在线性模型中也存在同样的问题。
泛化理论:
测试损失(Test Loss)-训练损失(Training Loss)≤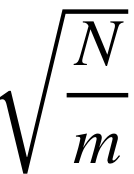
其中,N是“有效能力”。
“真实容量”(true capacity)的非空估计被证明是难以捉摸的:
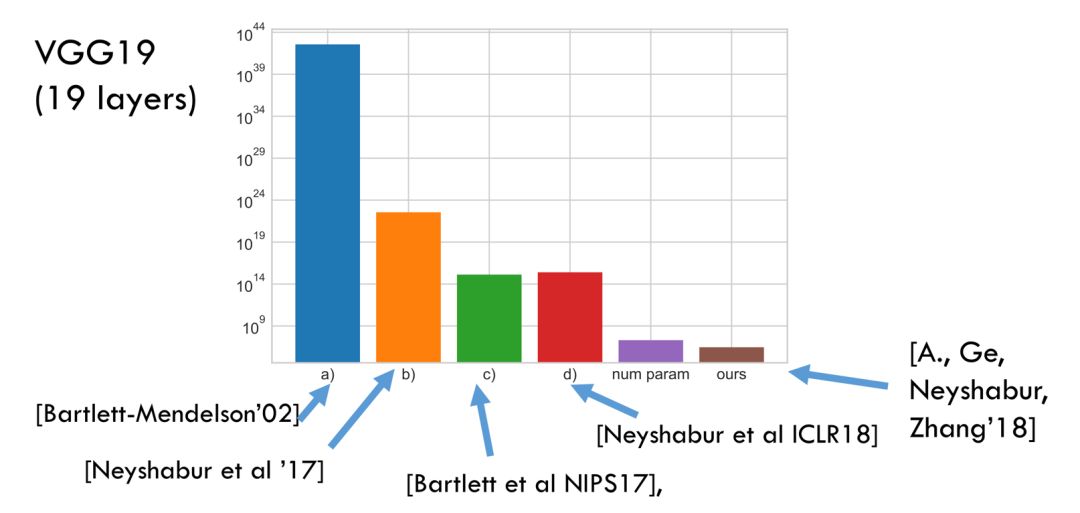
“真实参数”(true parameters)的非空边界被证明是难以捉摸的:
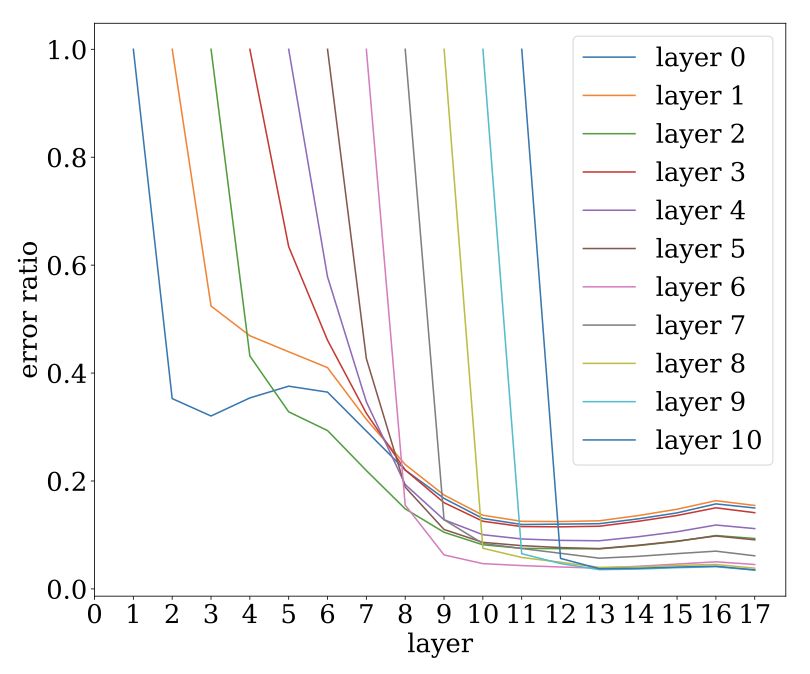
深度网络噪声稳定性(可以视作深度网络的边缘概念):
噪声注入:为一个层的输出x添加高斯η 。
测量更高层次的变化,若变化是小的,那么网络就是噪声稳定的。
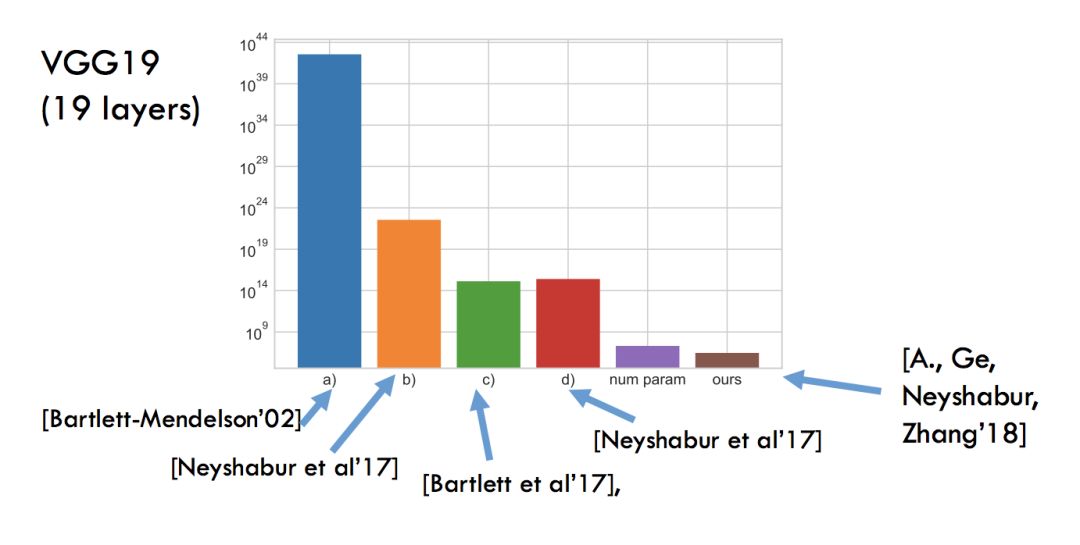
VGG19的噪声稳定性:
当高斯粒子经过更高层时的衰减过程
与泛化相关定性实验:
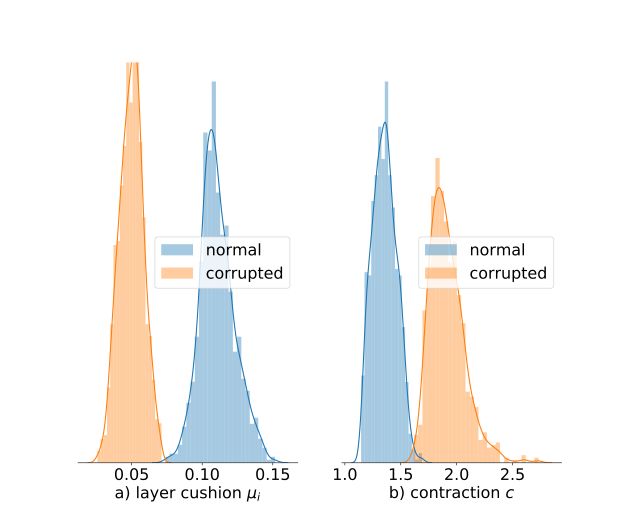
垫层(layer cushion)在正常数据上的训练要比在损坏数据上的训练高得多
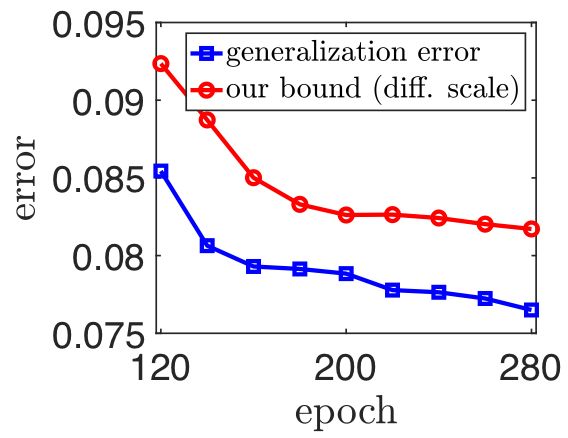
在正常数据训练过程中的进化
“深度”的作用
深度的作用是什么?
理想的结果是:当遇到自然学习问题时,不能用深度d来完成,但可以用深度d+1来完成。但是目前,由于理论依据不足,缺乏“自然”学习问题的数学形式化,还无法达到理想的结果。
深度的增加对深度学习是有益还是有害的?
支持:会出现更好的表现(正如上面实验结果所示);
反对:使优化更加困难(梯度消失(vanishing gradient)、梯度爆炸(exploding gradient),除非像残差网络这样的特殊架构)。
生成模型与生成对抗网络(GAN)理论
无监督学习:“流行假设”(Mainfold Assumption):
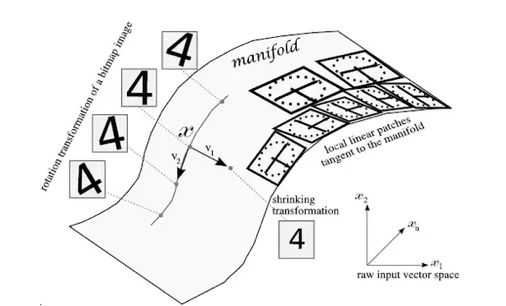
学习概率密度p(X|Z)的典型模型
其中,X是图像,Z是流行上的编码。目的是使用大量未标签的数据集来学习图像→编码匹配(code mapping)。
深度生成模型(deep generative model)
隐含假设: Dreal是由合理大小的深度网络生成的。
生成对抗网络(GANs)
动机:
(1)标准对数似然函数值(log-likelihood)目标倾向于输出模糊图像。
(2)利用深度学习的力量(即鉴别器网络,discriminator net)来改进生成模型,而不是对数似然函数。
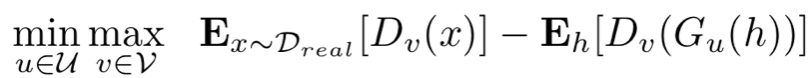
u:生成网络可训练参数
v:鉴别器网络可训练参数
鉴别器在训练后,真实输入为1,合成输入为0。
生成器训练来产生合成输出,使得鉴别器输出值较高。
GANs噩梦:模式崩溃(mode collapse)
因为鉴别器只能从少数样本中学习,所以它可能无法教会生成器产生足够大的多样性分布。
评估来自著名GANs的支持大小(support size)
CelaA:200k训练图像
DC-GAN:重复500个样本,500x500 =250K
BiGAN和所有支持大小,1000x1000 =1M
(结果与CIFAR10相似)
深度学习—自由文本嵌入
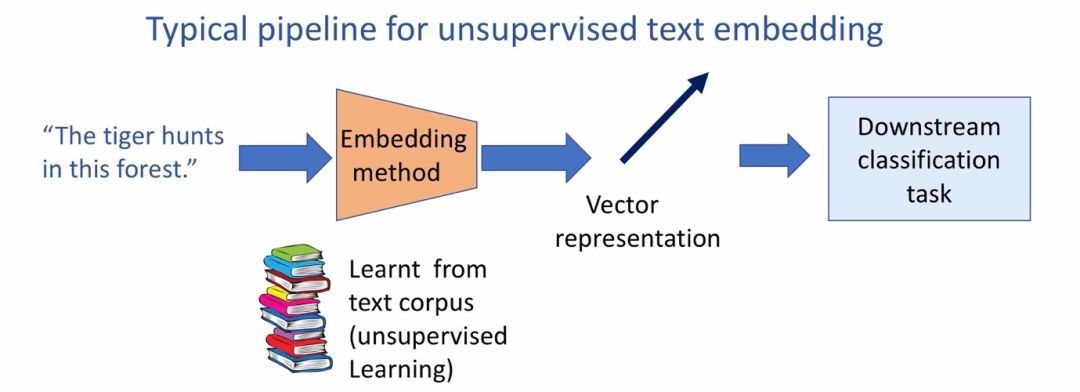
无监督学习文字嵌入经典流程
常用方法:复发性神经网络或LSTM等
手工业(cottage industry)的文本嵌入是线性的:
最简单的:构成词(constituent word)的词嵌入求和
加权求和:通过适应段落数据集来学习权重
性能(相似性、蕴涵任务):
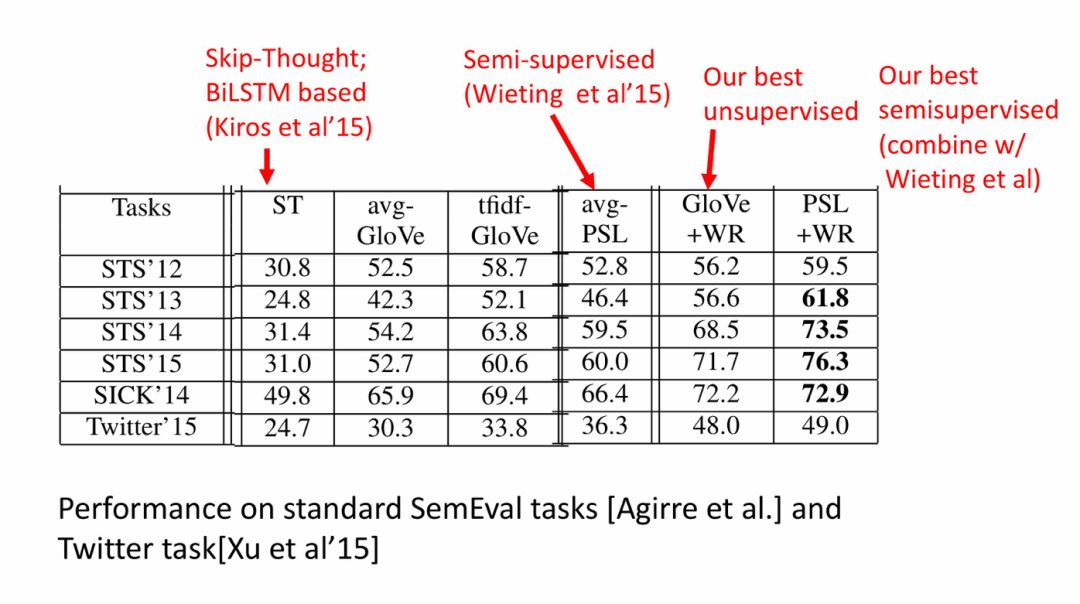
较先进的句子嵌入方法与下游分类(downstream classification)任务的比较:
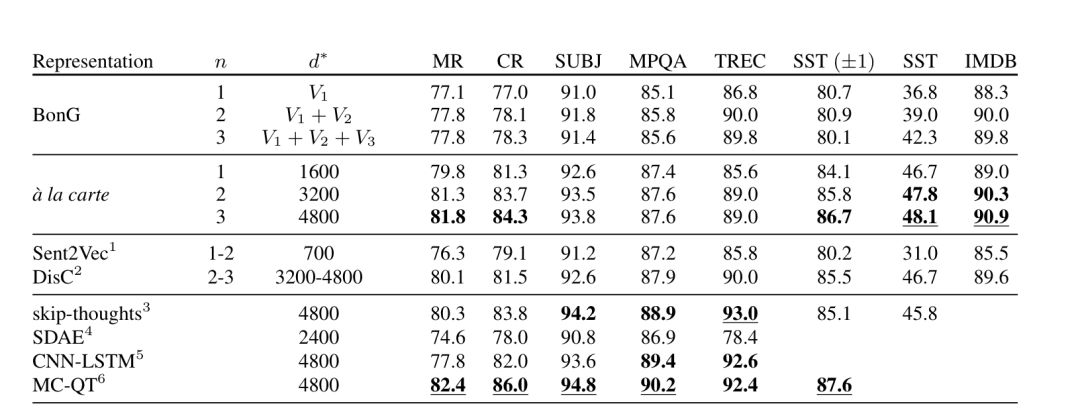
-
单片机学习资料。深入浅出通俗易懂,用钱买的。2011-02-04 0
-
ARM7 深入浅出的学习2012-12-04 0
-
深入浅出排序学习使用指南2019-09-16 0
-
深度学习入门之基于python的理论与实现2020-06-19 0
-
深入浅出Cortex-M0学习资料2010-06-18 1066
-
[CPLD-FPGA]《深入浅出玩转FPGA视频学习课程》35讲全[wmv]2013-09-04 1977
-
STM32深入浅出之新手篇2016-03-21 1235
-
如何理解深度学习?深度学习的理论探索分析2018-10-03 3771
-
深度学习入门基于python的理论与实现PDF电子书免费下载2019-12-09 1573
-
基于Python的理论与实现进行深度学习的入门教程2020-11-11 880
-
深度学习入门基于Python的理论与实现的PDF电子书免费下载2021-01-27 1289
-
深入浅出学习250个通信原理资源下载2021-04-12 799
-
深入浅出学习低功耗蓝牙协议栈2021-06-23 902
-
深入浅出学习eTs(七)如何判断密码是否正确2023-05-13 1000
-
OpenCV库在图像处理和深度学习中的应用2023-08-18 1002
全部0条评论

快来发表一下你的评论吧 !
