

AI核心领域——强化学习的缺陷
电子说
描述
前段时间,OpenAI的游戏机器人在Dota2的比赛中赢了人类的5人小组,取得了团队胜利,是强化学习攻克的又一游戏里程碑。但是本文作者Andrey Kurenkov却表示,强化学习解决的任务也许没有看起来那么复杂,深究起来是有缺陷的。以下是论智带来的编译。
在这篇文章中,我们来讨论讨论AI核心领域——强化学习的缺陷。我们先从一个有趣的比喻开始,之后会关注一个重要因素——先验知识,接着我们会对深度学习进行介绍,最后进行总结。
首先我们将对强化学习是什么进行介绍,以及它为什么有基础性缺陷(或者至少某个版本,我们称为“纯粹的强化学习”)。如果你是AI专业人才,可以跳过这部分简介。
棋盘游戏
假设你的一位朋友给你介绍了一款你从未听说过的游戏,并且你之前从来没玩过任何游戏。你朋友告诉你怎样算有效的移动,但是却不告诉你这样做的意义是什么,也不告诉你游戏怎么计分。在这种情况下你开始参与游戏,没有任何问题,也不会有任何解释。结果就是不断地输……慢慢地你发现了输局的某些规律,虽然之后还是会输,但起码能坚持玩一段时间了。经过几周后,甚至几千盘对抗后,你甚至能赢下一局。
听起来很傻,为什么不在一开始就问游戏的目标以及应该怎样获胜呢?总之,上面的场景是当下大多数强化学习方法的做法。
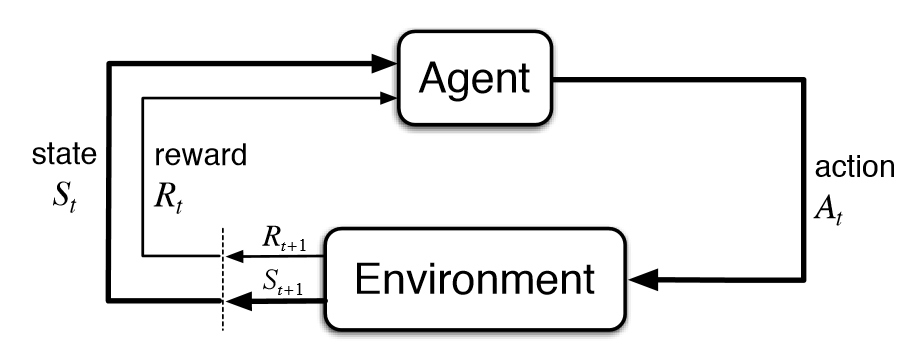
强化学习(RL)是AI的一个基础子领域,在强化学习的框架中,智能体(agent)在与环境的交互中学习应该在特定状态下做出哪些动作从而使长期奖励最大化。这也就是说在上述棋盘游戏中,玩家在棋盘中学习怎么走能让最后的分数最高。
在强化学习的典型模型中,智能体最初只知道它可以做哪些动作,除此之外对环境一无所知,人们希望它能在与环境的交互中,以及在收到奖励后学会该做什么动作。缺少先验知识的意思是,智能体从零开始学习,我们将这种从零开始的方法称为“纯粹的强化学习”。纯强化学习可以用到西洋棋或者围棋中,也可以应用到机器人等其他领域。
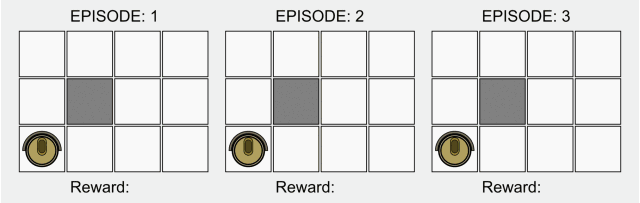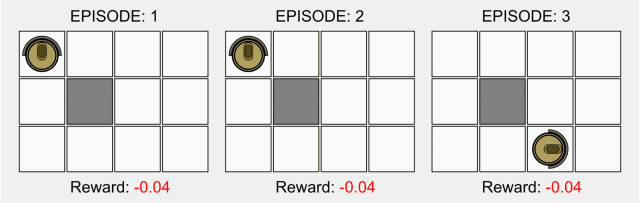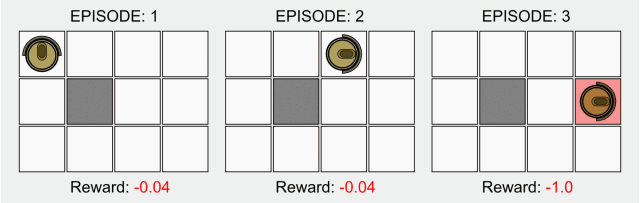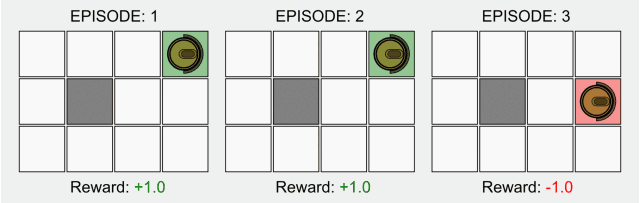
最近很多强化学习受到了深度学习的启发,但基础模型没怎么改变。毕竟这种从零开始学习的方法是强化学习的开端,并且在大多数基础等式中都有表现。
所以这里有个基本问题:如果纯强化学习的过程特别不合常理,那么在此基础上设计的AI模型能有多可靠?如果我们认为让人类通过纯强化学习全新的棋盘游戏很荒唐,那么这个框架对智能体来说也是有缺陷的呢?仅仅通过奖励信号而不借助先验知识和高水平指导,就开始学习一项新技能真的有意义吗?
先验知识和高水平指导在经典强化学习中是不存在的,隐式或显式地改变这些方法可能对所有用于训练强化学习的算法有很大影响,所以这是个非常大的问题,要回答它需要两部分:
第一部分即本文,我们将从展示纯强化学习的主要成果开始,这些成果可能不会像你想象得那样重要。接着,我们会展示一些更复杂的成果,它们在纯强化学习下可能无法完成,因为智能体会受到多种限制。
在第二部分中,我们将浏览各种能解决上述限制的方法(主要是元学习和zero-shot学习)。最后,我们会总结基于这种方法的令人激动的成果并进行总结。
纯强化学习真的有道理吗?
看到这个问题,大多数人可能会说
当然了,AI智能体不是人类,不会像我们一样学习,纯强化学习已经能解决很多复杂任务了。
但是我不同意。根据定义,AI研究指的是让机器做只有动物和人类目前能做的事,因此,将机器和人类智慧相比是不恰当的。至于纯强化学习已经解决的问题,人们常常忽视了重要的一点:这些问题通常看起来并不那么复杂。
这听起来可能很惊讶,因为很多大型研究机构都努力地用强化学习做出各种成果。这些成果确实很棒,但是我仍然认为这些任务并不像他们看起来那么复杂。在深入解释之前,我列举了一些成就,并且指出它们为什么值得人们研究:
DQN:这项由DeepMind推出的项目在五年前引起了人们对强化学习极大的兴趣,该项目展示了将深度学习和纯强化学习结合后,可以解决比此前更复杂的问题。虽然DQN只包含少量的创新,但对于让深度强化学习变得更实用是很重要的。
AlphaGo Zero和AlphaZero:这种纯强化学习模型已经超越了人类最佳水平。最初的AlphaGo是监督学习和强化学习结合的产物,而AlphaGo Zero是完全通过强化学习和自我对抗实现的。因此,它是最接近纯强化学习方法的产物,虽然它仍然有提供游戏规则的模型。
在与人类对战获胜后,AlphaGo Zero被很多人看作是一种游戏颠覆者。接着一种更通用的版本——AlphaZero出现了,它不仅能玩围棋,还能下国际象棋和日本将棋,这是第一次有一种算法可以完成两种棋类比赛。所以AlphaGo Zero和AlphaZero是非常了不起的成就。
OpenAI可以打Dota的机器人:深度强化学习能够在Dota2中多人模式中击败人类了。去年,OpenAI的机器人在1v1对抗中击败了人类就已经令人印象深刻了,这次是更加困难的5v5。它同样不需要先验知识,并且也是通过自我对抗训练的。
这种在复杂游戏中的团队模式中获胜的成绩比此前的雅达利游戏和围棋对抗更惊艳。另外,这一模型还没有进行主要的算法更新,完全依靠大量计算和已有的纯强化学习算法和深度学习进行的。
所以,纯强化学习已经做出了很多成绩。但是就像我之前说的,他们有些地方可能被高估了。
首先从DQN开始。
它可以超越人类水平玩很多雅达利游戏,但也并不是全部。一般来说,它适合玩灵活度较高的、不需要推理和记忆的游戏。即使五年之后,也不会有纯强化学习攻下推理和记忆游戏。相反,能完成这些游戏的都经过了指导和示范。
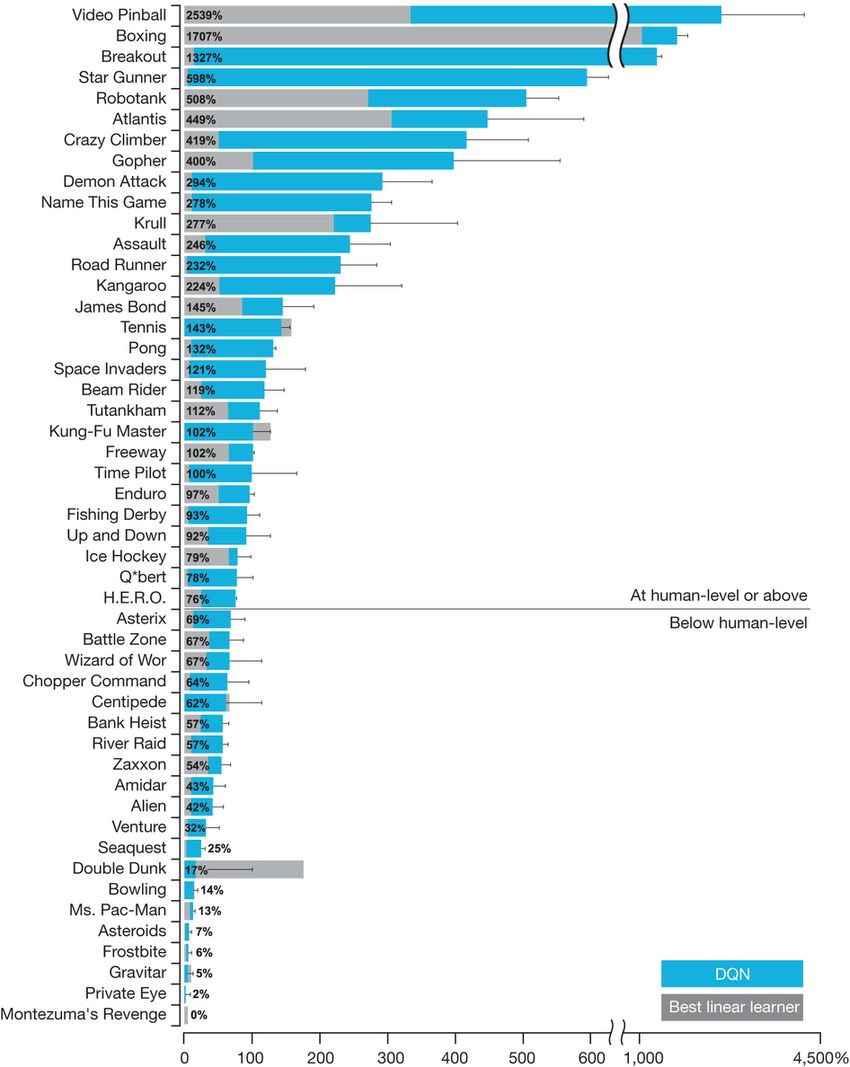
即使在DQN表现良好的游戏中,它也需要非常大量的时间和经验去学习。
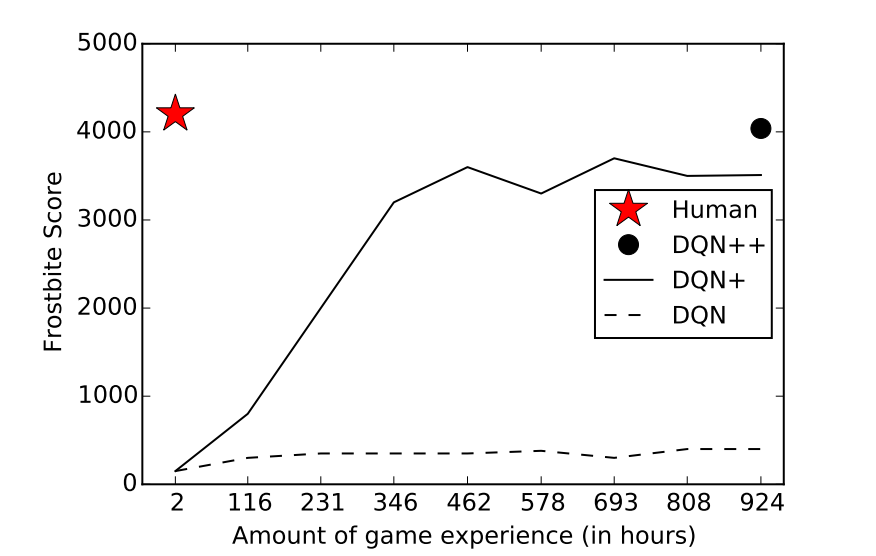
同样的限制在AlphaGo Zero和AlphaZero上都有体现。围棋的很多性质都能让学习任务变得简单,例如它是必然的、完全可观测的、单一智能体等等。但唯独一件事让围棋变得麻烦:它的分支因数太多了。
所以,围棋可能是变数最多的简易游戏。有人说强人工智能(AGI)因为AlphaGo的成功即将到来,这种说法不攻自破。多数研究者认为,真实的世界比一个简单游戏复杂得多,尽管AlphaGo的成功令人赞赏,但是它和它所有的变体从根本上和“深蓝”是相似的:它只是一套昂贵的系统罢了。
说到Dota,它的确比围棋更复杂,并且是非静止的、多人的游戏。但是它仍然是可以用灵活的API操控的游戏,并且成本巨大。
所以,尽管这些成就很伟大,我们仍需要对它们的本质进行了解,同时要思考,纯强化学习难道不能成为获取这些成就的最佳方法吗?
纯强化学习的基础缺陷——从零开始
有没有更好的方法让智能体下围棋、玩dota呢?AlphaGo Zero的名字来源正是暗示它是从零开始学习的模型,但是让我们回到文章开头说的那个小故事,如果让你从零开始学习下围棋,不给任何解释,听起来很荒谬对吗?所以为什么要把这定为AI的目标呢?
事实上,如果你正在学的那个棋盘游戏是围棋,你会怎么开始?可能你会先读一遍规则,学一些高级策略,回忆一下之前的对战,总结经验……确实,让AlphaGo Zero和Dota机器人从零开始学习是有点不公平的,它们只依靠更多数量的游戏经验和运用比人类大得多的计算力。
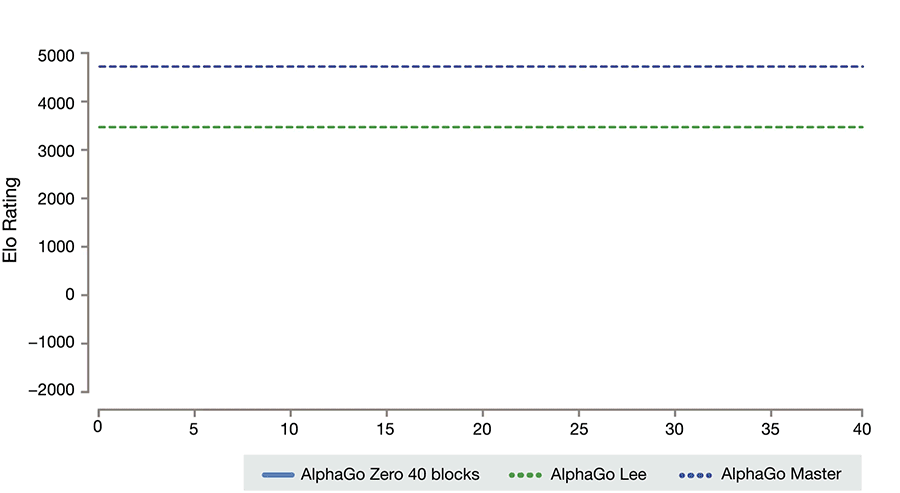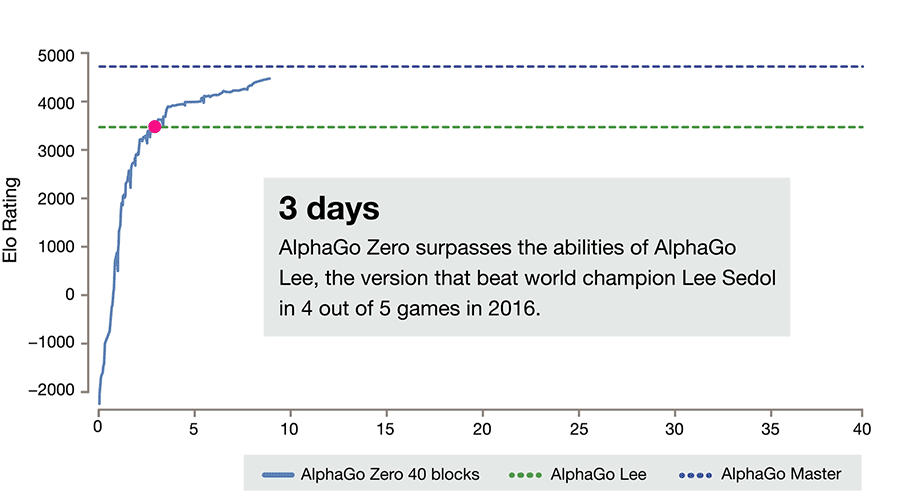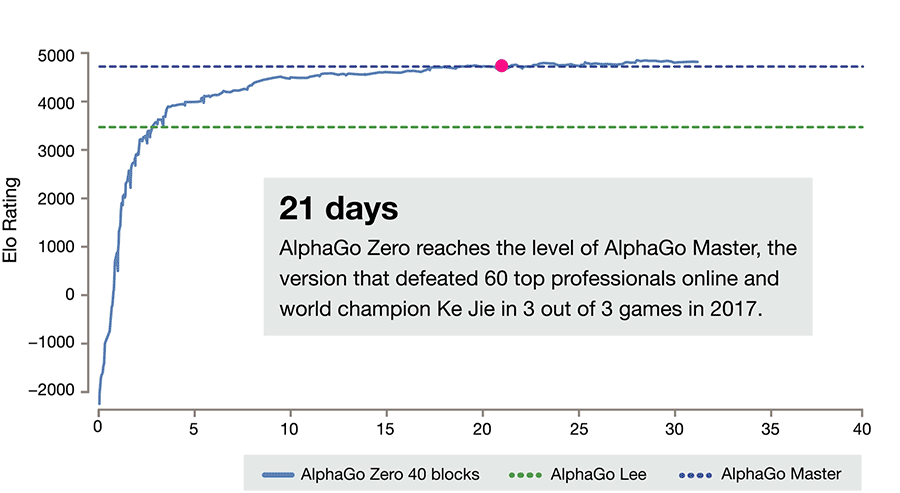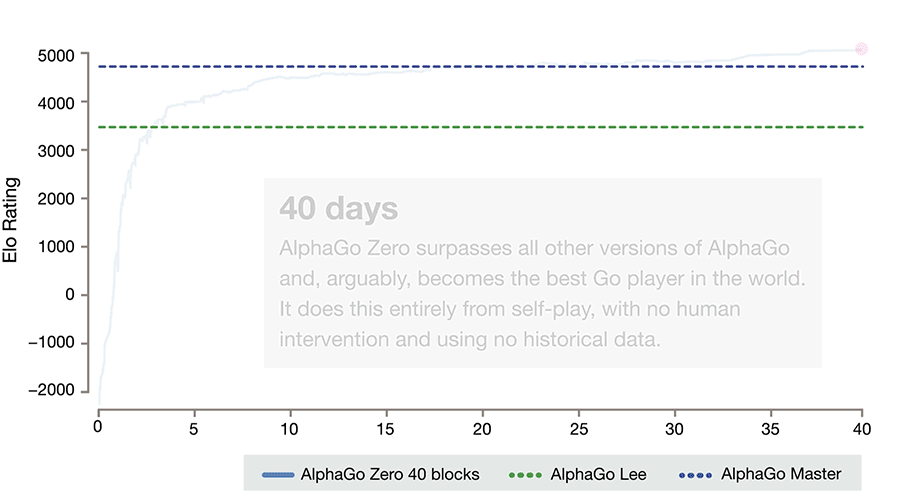
AlphaGo Zero技能增长曲线,注意,它花了一整天的时间和好几千局游戏才达到人类最低水平
实际上,纯强化学习技术可以在更“窄”的任务中应用,例如连续控制或是像dota和星际争霸这样的复杂游戏。然而随着深度学习的成功,AI研究者正尝试解决更复杂的问题例如汽车驾驶和对话。
所以,纯强化学习,或者从零开始的学习方法,是解决复杂任务的正确方法吗?
是否应该坚持纯强化学习?
答案可能如下:
当然,纯强化学习是除了围棋和dota之外的其他问题的正确解决方法。虽然在棋盘类游戏中有点讲不通,但是在通用事物的学习上还是可以说得通的。另外,就算不受人类的启发,智能体在没有先验知识的条件下也能表现得更好。
让我们先说最后一点,不考虑人类的启发,从零开始的典型做法就是另一种方法会限制模型的精确度,将人类的想法编码到模型上是很困难的,甚至会降低性能。这种观点在深度学习的成功之后成为了主流,即用百万级参数学习端到端模型,并在大量数据上训练,同时有一些内在先验知识。
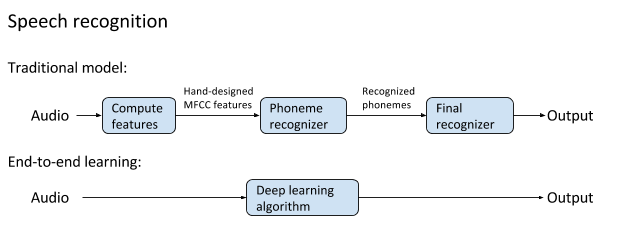
但问题时,加入先验知识和知道并不会将人类知觉中含有的有限结构加入到智能体上。换句话说,我们可以教会智能体或模型关于怎样执行任务,而不会添加对其能力有限制的因素。
对大多数AI问题来说,不从零开始就不会限制智能体学习的方式。目前还没有确切的原因解释,为什么AlphaGo Zero如此执着于“从零开始”,事实上它可以借助人类知识表现得更好。
那么纯强化学习是最佳解决办法吗?这个答案曾经很简单,在无梯度优化领域,纯强化学习是你可以选择的最可靠的方法。但是最近的一些论文质疑了这一说法,并认为更简单的基于演化策略的方法能达到相似效果。具体论文:
Simple random search provides a competitive approach to reinforcement learning
Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Towards Generalization and Simplicity in Continuous Control
Ben Recht,是理论和实际优化算法的顶尖研究者,也是Simple random search provides a competitive approach to reinforcement learning一文的作者之一,他准确地总结了以上观点:
我们看到,随机搜索在简单线性问题上表现良好,并且比一些强化方法,例如策略梯度表现得更好。但是当我们提出更难的问题时,随机搜索崩溃了吗?不好意思,没有。
所以,将纯强化学习用来从零开始学习不一定是正确的方法。但是回到人类从零开始学习的问题,人们会在具备一些技巧,却没有指示信息的情况下开始学习吗?不会的。
也许在一些通用基础问题上,纯强化学习可能有用,因为这些问题很广泛。但是在AI中,很大部分的问题是否适合强化学习还并不清楚。事实上,之所以选择从零开始,是因为目前的AI和强化学习都有着很多缺陷:
目前的AI非常需要数据。很多项目都需要大量的数据进行计算,而从零学习只需要高效的采样方法即可。
目前的AI是不透明的。也就是“黑箱”问题,很多时候我们只能从较高层次了解AI算法的学习和工作流程。
目前的AI应用范围有限。很多模型一次只能执行一种任务,而且很容易崩溃。
现有AI很脆弱。只有在大量数据训练的基础上,模型才可能对从未见过的输入生成较好结果。即使如此也经常崩溃。
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 2099
-
反向强化学习的思路2019-04-03 2370
-
深度强化学习实战2021-01-10 2795
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28662
-
如何深度强化学习 人工智能和深度学习的进阶2018-03-03 4655
-
人工智能机器学习之强化学习2018-05-30 1737
-
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?2018-07-15 18442
-
谷歌推出新的基于Tensorflow的强化学习框架,称为Dopamine2018-08-31 4317
-
基于强化学习的MADDPG算法原理及实现2018-11-02 22797
-
基于PPO强化学习算法的AI应用案例2020-07-29 3390
-
DeepMind发布强化学习库RLax2020-12-10 1305
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 1211
-
模型化深度强化学习应用研究综述2021-04-12 1183
-
彻底改变算法交易:强化学习的力量2023-06-09 911
-
如何使用 PyTorch 进行强化学习2024-11-05 1477
全部0条评论

快来发表一下你的评论吧 !
