

新的深度神经网络模型命名为CODEnn
电子说
描述
在软件开发过程中,经常需要进行代码搜索。然而,现有的代码搜索方法大都将代码视作文本,依赖源代码和自然语言查询的文本相似性。由于缺乏对查询和源代码的语义的理解,在某些场景下,无法返回期望的结果。
例如,下面这段代码读取xml文档:
publicstatic < S > S deserialize(Class c, File xml) {
try {
JAXBContext context = JAXBContext.newInstance(c);
Unmarshaller unmarshaller = context.createUnmarshaller();
S deserialized = (S) unmarshaller.unmarshal(xml);
return deserialized;
} catch (JAXBException ex) {
log.error("Error-deserializing-object-from-XML", ex);
returnnull;
}
}
然而,由于代码中并不包含“读取”(read)一词,因此现存的方法可能无法成功返回这一代码片段。
有鉴于此,HKUST和微软研究院的研究人员顾小东、Hongyu Zhang、Sunghun Kim最近发表论文,使用深度神经网络,学习源代码和自然语言查询的统一向量表示,以支持代码语义搜索。
CODEnn
研究人员将其新提出的深度神经网络模型命名为CODEnn(Code-Description Embedding Neural Network,代码-描述嵌入神经网络)。CODEnn的主要思路是将代码片段和自然语言查询联合嵌入一个统一的向量空间,使查询嵌入和相应的代码片段嵌入为相近的向量(可以通过向量相似度匹配)。
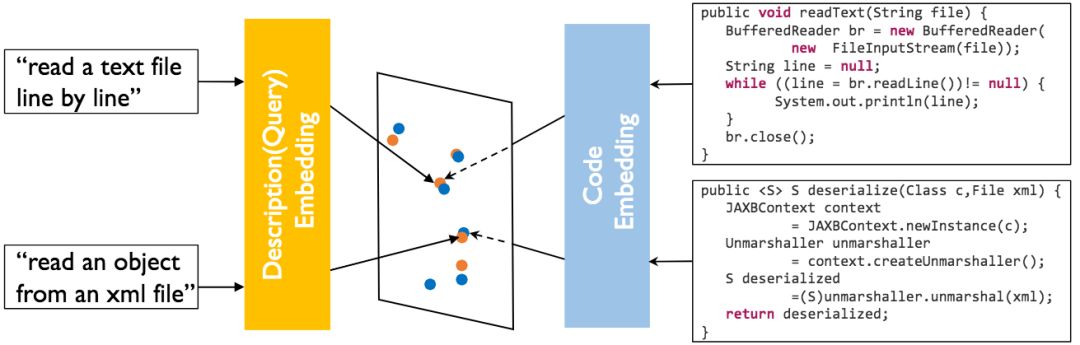
联合嵌入
首先让我们简单温习一下联合嵌入的概念。
联合嵌入(joint embedding),又称多模态嵌入(multi-modal embedding),可以将异构数据嵌入统一的向量空间,使得模态不同而语义相似的概念在空间中占据相近区域。形式化地表述为:
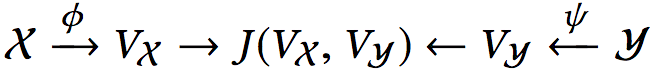
其中,φ、ψ为嵌入函数,J衡量相似度。
在CODEnn中,φ为源代码嵌入网络(CoNN),ψ为自然语言描述嵌入网络(DeNN),J为余弦相似度。
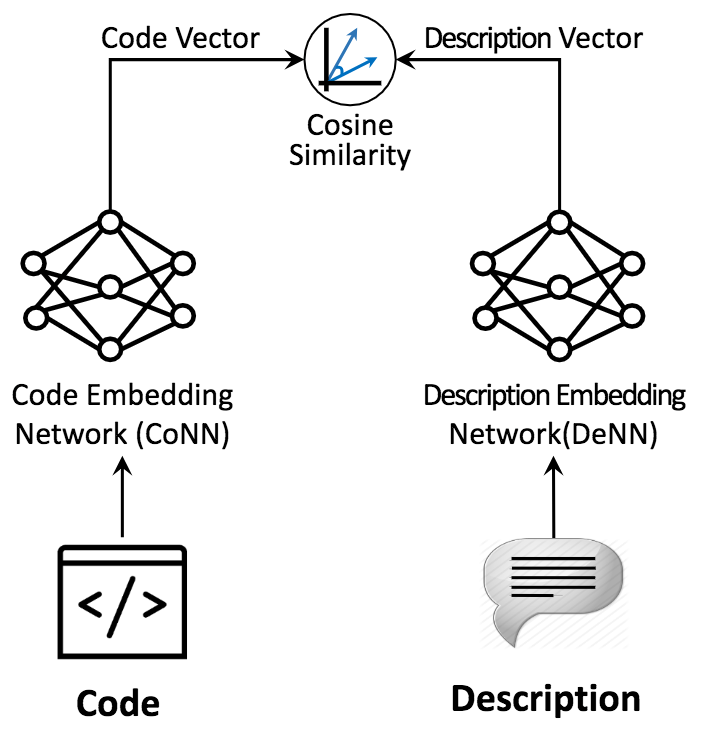
具体架构
具体而言,CODEnn的嵌入网络主要使用了循环神经网络(RNN)和最大池化,架构如下:
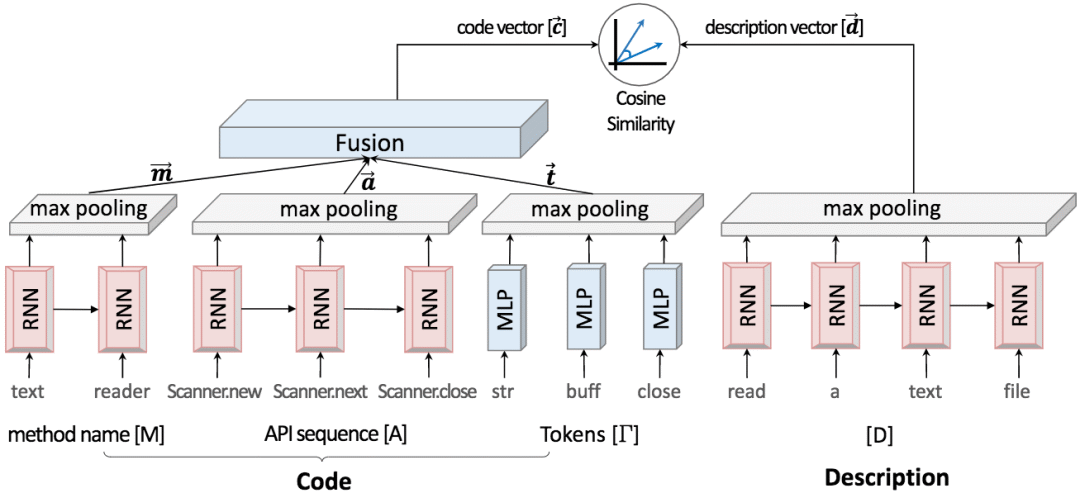
从上图我们可以看到,正如我们之前提到的那样,网络架构分为三个模块。下面我们将从上往下,从右向左地依次说明这三个模块:
相似度模块
DeNN
CoNN
相似度模块
这是最简单的模块,将代码和相应描述转换为向量后,通过这一模块衡量两者的相似度。具体而言,使用的是余弦相似度:
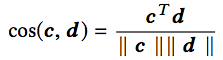
DeNN
DeNN将自然语言描述嵌入为向量。DeNN使用循环神经网络(tanh激活)和最大池化完成嵌入:
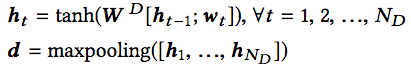
CoNN
由于代码不是简单的纯文本,包含多种结构性信息。因此,CoNN的架构要比DeNN复杂。
CoNN考虑代码的三个方面:
方法名
API调用序列
代码中包含的token
从每个代码片段中提取以上三方面的信息后,分别嵌入,然后融合成单个向量表示。
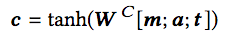
上式中,c为整个代码片段的向量表示,m、a、t分别为方法名、API调用序列、token的嵌入向量表示。
方法名的嵌入和DeNN类似,同样使用循环神经网络(tanh激活)和最大池化:
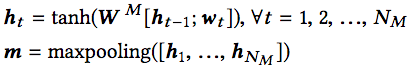
API调用序列的嵌入同理:
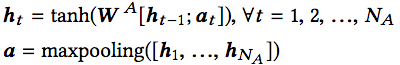
token的嵌入有所不同。因为并不在意token的顺序,也就是说,不把token作为序列数据,所以就不使用循环神经网络了。使用的是多层感知器(MLP),也就是普通的全连接层。不过仍然搭配了tanh激活和最大池化:
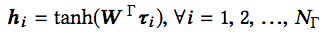
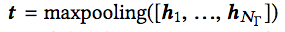
模型训练
CODEnn接受代码、描述作为输入,预测其嵌入表示的余弦相似度。具体而言,每个训练样本为一个三元组(C, D+, D-),其中C为代码片段,D+为正面样本(C的正确描述),D-为负面样本(随机选取的不正确描述)。训练时,CODEnn预测(C, D+)和(C, D-)的余弦相似度,并最小化以下损失:
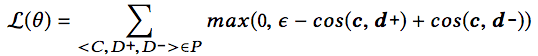
上式中,θ为模型参数,P为训练数据集,c、d+、d-为C、D+、D-的嵌入向量,ε为边缘常数,在研究人员的试验中,ε的值定为0.05. 从直觉上说,最小化以上损失,将鼓励代码片段和正确描述的余弦相似度提高,代码片段和错误描述的余弦相似度下降。
下面是一些实现的细节:
循环神经网络选用的是双向LSTM,每个双向LSTM在每个方向上有200个隐藏单元。
词嵌入维度为100.
嵌入token的MLP有100个隐藏单元。
融合代码片段不同方面的MLP有400个隐藏单元。
优化算法为mini-batch Adam,batch大小为128.
词汇量限制为10000(10000个训练集中最常用的单词)。
模型基于Keras构建。
在单块Nvidia K40 GPU上,训练耗时约50小时(500个epoch)。
收集训练语料
CODEnn模型需要大规模的训练语料,语料包括代码元素和相应的描述,即(方法名, API调用序列, token, 描述)元组。

研究人员利用GitHub上的开源项目准备语料:
下载了GitHub上所有创建于2008年8月至2016年6月的Java项目。
排除所有未加星的项目,以移除玩具项目和试验性项目。
选取带有文档注释的Java方法(Java中的文档注释以/**开始,以*/收尾)。
最终收集到了18233872个Java方法。
Java方法名的提取很简单,根据驼峰原则解析即可,例如,listFiles将被解析为list和files。
API调用序列的提取要复杂一点。研究人员使用Eclipse JDT编译器解析了AST,并根据如下规则生成API调用序列:
new C() ->C.new
o.m() ->C.m (o为类C的实例)
方法调用作为参数传入时,传入的方法调用在前:o1.m1(o2.m2(), o3.m3()) ->C2.m2-C3.m3-C1.m1
提取语句序列s1;s2;...;sN中每个语句si的方法调用序列ai,并连接:a1-a2-...-aN
条件语句的调用序列包括所有分支:if (s1) {s2;} else {s3} ->a1-a2-a3
循环语句:while (s1) {s2;} ->a1-a2
token提取,同样根据驼峰原则解析方法主体,并移除重复token。同时也移除了一些停止词(例如the、in)和Java关键字,因为这些词在源代码中频繁出现,区分性不好。
描述提取,也用到了Eclipse JDT编译器,从AST提取JavaDoc注释。根据Javadoc指导原则,JavaDoc注释的第一句话通常是方法的概述,因此研究人员将JavaDoc注释的第一句话作为描述。

一个提取的例子
DeepCS
研究人员基于CODEnn模型创建了一个代码搜索工具DeepCS。给定自然语言查询,DeepCS会建议最相关的K个代码片段。DeepCS系统包含三个主要阶段:
离线训练
离线代码嵌入
在线代码搜索
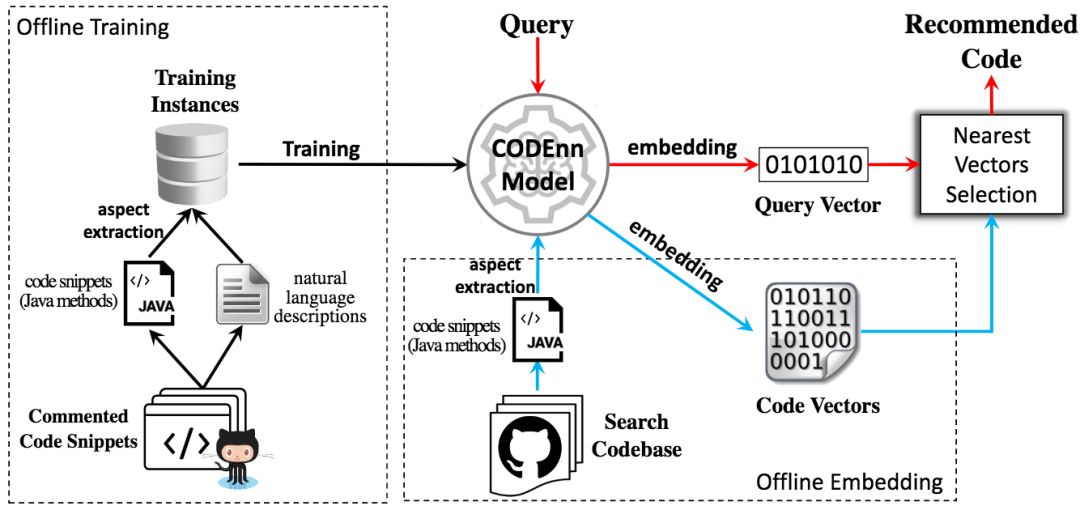
DeepCS事先将代码库中的所有代码片段嵌入为向量(使用训练好的CODEnn模型的CoNN模块)。在线搜索时,当开发者输入自然语言查询时,DeepCS首先使用训练好的CODEnn模型的DeNN模块将查询嵌入为向量,然后估计查询向量和所有代码向量的余弦相似度,并返回相似度最高的K个(比如,10个)代码片段作为搜索结果。
试验
试验设置
为了更好地评估模型的表现,研究人员使用了不同于训练语料的独立代码库。研究人员选取了GitHub上至少有20星的Java项目。和训练语料不同,测试数据集包含所有代码(包括那些没有Javadoc注释的代码)。总共收集了9950个项目,从中得到了16262602个方法。
研究人员从Stack Overflow问答网站中选取了得票最高的Java编程问题,并手工检查了这些问题,确保其符合标准:
这个问题关于一项具体的Java编程任务。研究人员剔除了描述含糊抽象的问题,比如“加载JNI库失败”,“StringBuilder和StringBuffer的区别是什么?”,“为什么Java有transient域?”
接受的答案包含Java代码片段。
不与之前的问题重复。
评估指标
两个开发者独立地查看搜索结果,并标注其相关性。接着互相讨论不一致的标签,并重新标注。重复这一过程,直到达成共识。
研究人员使用了4个常用的指标衡量代码搜索的有效性。其中2个指标衡量单次代码搜索查询的有效性:
FRank 首个命中结果在结果列表中的位置。由于用户从上往下查看结果,因此较小的FRank值意味着找到所需结果需要花费的精力较少。
Precision at k 衡量k个返回结果中相关结果所占的比例。

Precision at k很重要,因为开发者经常会查看多个结果,良好的带吗搜索引擎应该避免给开发者过多的噪声。Precision at k越高,代码搜索的表现就越好。研究人员评估了k值为1、5、10时的Precision at k.
另外两个指标衡量一组查询的表现:
SuccessRate at k 衡量在前k个结果中命中结果的比例。
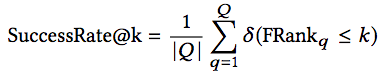
其中,Q为查询集合,δ函数在输入为真时返回1,否则返回0. SuccessRate at k越高,代码搜索的总体表现就越好。和Precision at k一样,研究人员评估了k值为1、5、10时的SuccessRate at k.
MRR 是一组查询中FRank倒数的平均数。MRR越高,代码搜索的总体表现就越好。
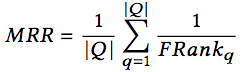
评测对比
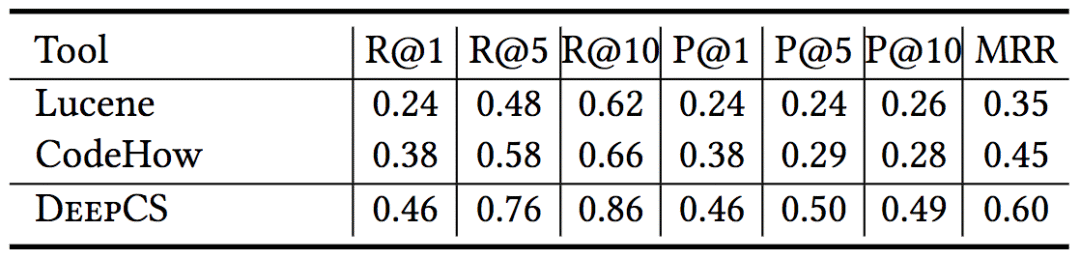
研究人员对比了CodeHow(当前最先进的代码搜索引擎)和Lucene(许多代码搜索工具使用的流行文本搜索引擎)的表现:
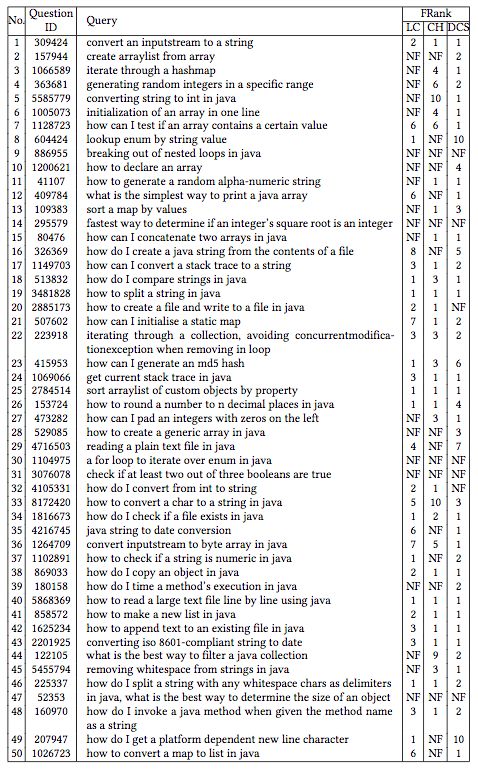
上表中,NF表示未找到,LC表示Lucene,CH表示CodeHow,DCS表示DeepCS。
从上表我们可以看到,一般来说,相比Lucene和CodeHow,DeepCS能返回更相关的结果。统计数据也证实了这一点。
例子
为了演示DeepCS的优势,研究人员提供了一些具体的例子。

上面的两个查询中,第一个queue是动词(加入队列),第二个queue是名词(队列)。普通的文本搜索引擎很难区分两者,而DeepCS成功理解了两者的不同。

上面这个例子展示了DeepCS的鲁棒性。CodeHow返回了很多与查询中不太重要的单词(比如specified和character)相关的结果,而DeepCS可以成功识别不同关键词的重要性,理解查询的关键点。

这个例子展示了DeepCS能够理解查询的语义。尽管代码片段中不包含查询中的关键词“read”(读取)和“song”(歌曲),DeepCS仍然找到了语义相关的结果,“deserialize”(反序列化)和“voice”(声音)。
当然,DeepCS有时可能会返回不够精确的结果。

上图中的查询语句为“生成md5”,精确结果在返回结果列表中排在第7,而部分相关的结果(生成校验值)却排在结果列表的前面。研究人员打算以后在模型中加入更多代码特征(例如上下文环境),以进一步提升表现。
-
深度神经网络模型有哪些2024-07-02 3150
-
卷积神经网络模型有哪些?卷积神经网络包括哪几层内容?2023-08-21 2760
-
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法2023-08-17 2173
-
卷积神经网络模型发展及应用2022-08-02 13207
-
基于深度神经网络的激光雷达物体识别系统2021-12-21 3804
-
深度神经网络是什么2021-07-12 1964
-
深度神经网络模型的压缩和优化综述2021-04-12 1101
-
深度神经决策树:深度神经网络和树模型结合的新模型2018-08-19 13285
-
从AlexNet到MobileNet,带你入门深度神经网络2018-05-08 2736
全部0条评论

快来发表一下你的评论吧 !
