

测量神经网络的抽象推理能力
电子说
描述
聚焦 ICML—— Deep Mind 今天在 ICML 大会上发表了他们的最新研究,从人类的 IQ 测试里用来衡量抽象推理的方法中获得灵感,探索深层神经网络的抽象推理和概括的能力。一开始看到文章的前半部分的 IQ 测试题数据集,我在凌晨十二点花了一些时间把几个测试题做完了,但是并不是以预期中的飞速完成,然后回想体会了一下我“是如何理解题目,进而做出这些题目得到结果的”。我就很好奇这将会是如何开展的一个研究;随着岁月的流逝,我们会不断地遗忘知识,渐渐地还给老师了,但是我们学习新知识的能力,推理思维力也不如以前, 那这个研究的成果又会是如何呢?今天人工智能头条也为大家介绍一下 Deep Mind 的这项最新研究:测量神经网络的抽象推理能力。看到最后觉得需要练练的怕是我吧~~
神经网络是否可以学习抽象推理,还是仅仅浅显地学习统计数据学习,是最近学术界辩论的主题。在本文中,受到一个著名 IQ 测试的灵感启发,我们提出一个抽象推理挑战及其相应的数据集。为了成功应对这一挑战,模型必须应对训练和测试阶段不同数据方法情况下的各种泛化情况,我们展示了即使是在训练集和测试集的差别很小的情况下,像 ResNet 这样的模型也难以取得很好的泛化表现。
为了解决这个问题,我们设计了一种用于抽象推理的新颖结构,当训练数据和测试数据不同时,我们发现该模型能够精通某些特定形式的泛化,但在其他方面能力较弱。进一步地,当训练时模型能够对答案进行解释性的预测,那么我们模型的泛化能力将会得到明显的改善。总的来说,我们介绍并探索两种方法用于测量和促使神经网络拥有更强的抽象推理能力,而我们公开的抽象推理数据集也将促进在该领域进一步的研究进展。
在机器学习问题上,基于神经网络的模型已经取得了长足而又令人印象深刻的成果,但同时其对抽象概念的推理能力的研究也是一大难题。先前的研究主要集中于解决通用学习系统的重要特征,而我们的最新论文提出了一种在学习机器的过程中测量抽象推理的方法,并揭示了关于泛化本质问题的一些重要见解。
要理解为什么抽象推理对于通用人工智能如此得重要,首先了解阿基米德提出的 “famous Eureka” :即物体的体积等于所取代的水体积,他从概念层面理解体积,因此能够推断出其他不规则形状物体的体积。
我们希望 AI 也拥有这样类似的能力。尽管当前的人工智能系统可以在复杂的战略游戏中击败人类的世界冠军,但它们经常挣扎于其他一些看似简单的任务,特别是在新环境中需要发现并重复应用抽象概念。例如,如果专门训练我们系统只学习计算三角形,那么即便是当前最好的 AI 系统也无法计算方形或其他先前未见过的对象。
因此,要构建更好、更智能的系统,了解当前神经网络处理抽象概念的方式并寻求改进的地方是非常重要的。为了实现这一目标,我们从人类智商测试中汲取用于测量抽象推理的灵感。
▌创建抽象推理数据库

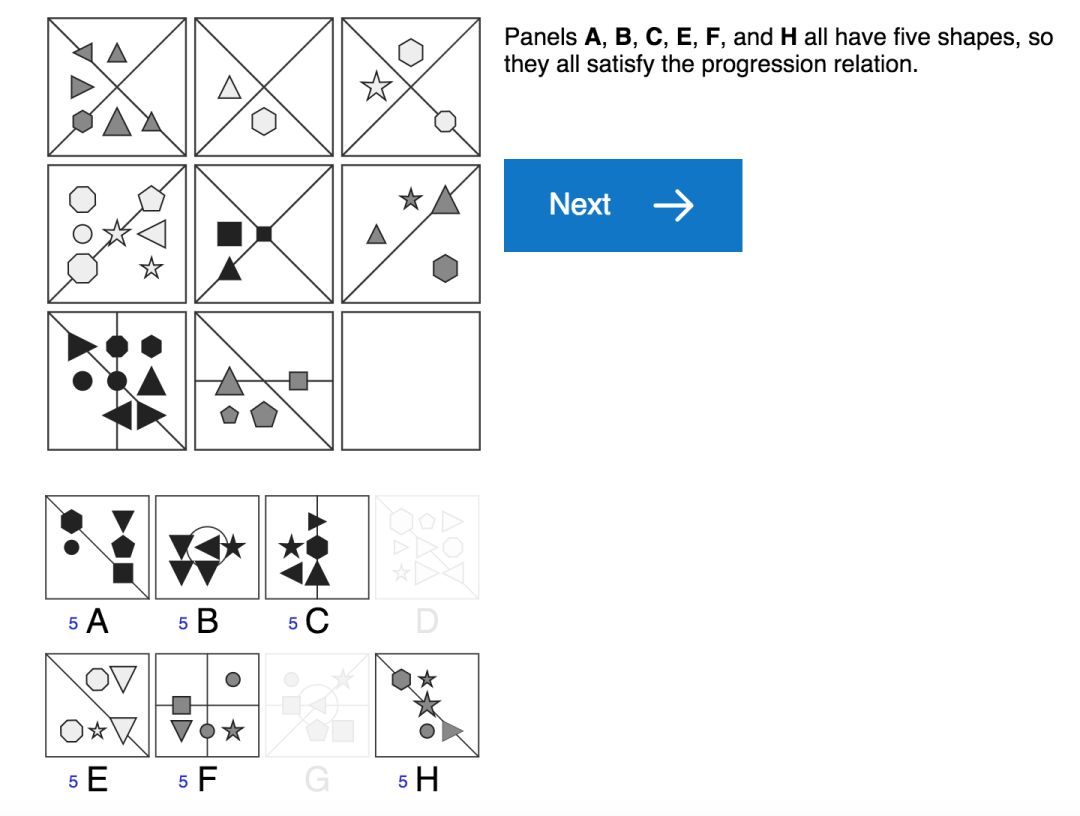
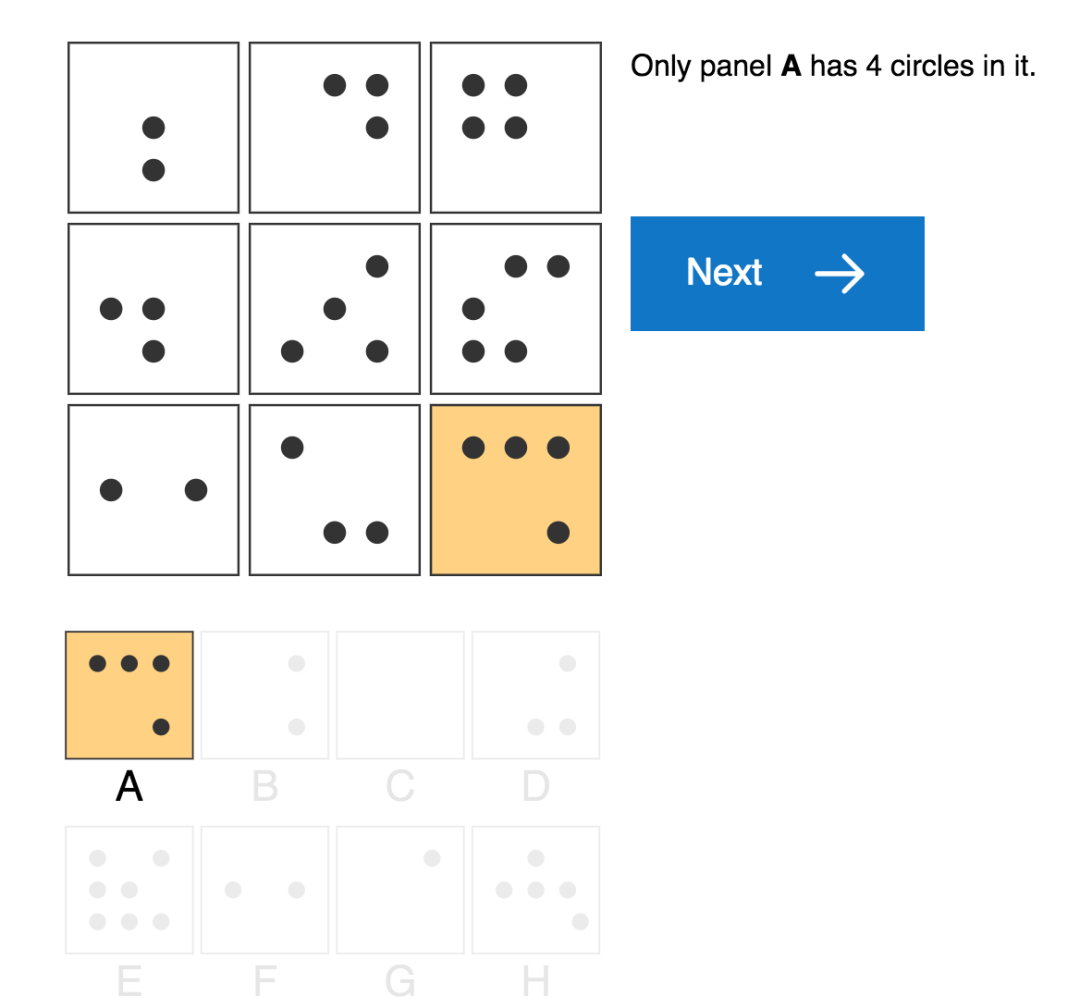
标准的人类 IQ 测试 (如上图),通常要求测试者通过应用他们日常经验学习到的原则来解释一些简单感知上的视觉场景。例如,人类测试者可以通过观察植物或建筑物的增长,或通过数学课上学习的加法运算,或通过跟踪银行余额带来的累积利息,来了解 “progressions” 这个概念 (表示属性增加、递增的概念)。然后,他们可以在谜题中应用这一概念,来推断形状的数量,大小,甚至它们的颜色强度将沿着序列增加的情况。
我们还没有办法能让机器学习智能体学习到这样的“日常体验”,我们就无法轻易的去衡量如何它们将知识从现实世界转化成视觉推理测试的能力。尽管如此,我们仍然可以创建一个实验设置,以便能够充分利用人类视觉推理测试。我们要研究的是从一组受控的视觉推理问题到另一组问题上的知识转移,而不是研究从日常生活到视觉推理问题的知识转移 (如人类测试中那样)。
为了实现这个目标,我们构建了一个用于创建矩阵问题的生成器,称之为“程序生成矩阵数据集” (Proceduralyly Generated Matrices, PGM),用于抽象推理的模型试验。、该数据集涉及一组抽象因素并通过原始数据随机采样得到,这些抽象因素包括“渐进 (progressions)” 之类的关系、以及颜色大小等属性数据。虽然该问题生成器只使用了一小部分的潜在因素,但它仍然会产生大量独特的问题,以构成丰富的矩阵数据集。
关系类型数据集 (R,元素是 r):包括 progression,XOR,OR,AND,consistent union关系等。
目标类型数据集 (O,元素是 o):包括 shape,line 类型等。
属性类型数据集 (A,元素是 a):包括 type,color,position,number 等属性。
接着,我们对生成器可用的因素或组合进行了约束,使生成器能够创建用于模型训练和测试的不同问题数据集,以便我们进一步测量模型推广到测试集的泛化能力。例如,我们创建了一组谜题训练集,其中只有当应用线条颜色时才会遇到渐进 (progressions) 关系,而测试集中的情况是当应用形状大小时才会发现该关系。如果模型在该测试集上表现良好,即使是训练时从未见过的数据情况下也是如此,就证明了我们的模型具有推断和应用抽象概念的能力。
▌抽象推理模型
在机器学习评估中所应用的典型的泛化方案中,训练和测试数据是服从相同的基础分布采样的,所测试的所有网络都表现出良好的泛化误差,其中有一些绝对性能甚至超过75%,实现了令人印象深刻的结果。对于性能最佳的网络,它不仅能够明确地计算不同图像面板之间的关系,还能并行地评估了每个潜在答案的适合性。我们将此网络架构称为—— Wild Relation Network (WReN),其模型结构示意图如下:
WReN模型结构
其中,每个 CNN 能够独立处理每个上下文面板 (panel),而每个上下文面板将用于返回一个单独的答案并生成9个嵌入矢量。随后,将这组得到的嵌入向量传递给 RN,其输出的是单个 sigmoid 单元,用于对问题答案的关联得分进行编码。 通过这样的网络传递过程,得到8个问题的答案及其相应的得分,最终通过一个 softmax 函数得分来确定模型的预测答案。
▌实验分析
为了验证抽象推理模型,我们在 PGM 数据集上进行了大量的实验测试,并对比分析了不同模型的表现,不同类型问题模型的表现,模型的泛化表现,辅助训练对模型表现的影响。
总的说来,当需要在先前见过的属性值之间进行属性值“内插值(interpolated)”时,以及在不熟悉的因素组合中应用已知抽象关系进行推理时,模型表现出非常好的泛化能力。然而,同样的网络在“外推 (extrapolation)”方案中却表现的更差。在这种情况下,测试集中的属性值与训练集中的属性值不在同一范围内。例如,对于训练期间包含深色物体而在测试期间包含浅色物体的谜题,就会出现这种情况。此外,当模型训练时将先前学习到的关系 (如形状数量的递增关系) 应用于新的属性 (如大小) 时,其泛化性能也会表现的更糟糕。
最后,我们观察到当训练的模型不仅能够预测正确的答案,还能推理出正确答案 (即能够考虑解决这个难题的特定关系和属性) 时,我们模型的泛化性能得到了改进。更有趣的是,模型的准确性与其矩阵潜在的正确推理能力密切相关:当推理解释正确时,模型的准确性将达到87%;而当其推理解释错误时,这种准确性表现将下降到只有32%。这表明当模型能够正确推断出任务背后的抽象概念时,它们可以获得更好的性能。
▌总结
最近的研究主要集中探索用于解决机器学习问题的神经网络模型方法的优点和缺点,通常是基于模型的能力或泛化能力的研究。我们的研究结果表明,关于泛化能力的一般结论可能是无益的:我们的神经网络在某些泛化方案测试中表现良好,而在其他测试中表现很差。其中的成功取决于一系列因素,包括所用模型的架构以及模型是否经过训练来为其答案选择提供可解释的推理等。在几乎所有的情况下,在超出模型经验范围的外推输入或用于解决完全不熟悉的属性问题时,模型都会表现不佳。因此,这也为这个关键而又重要的研究领域未来的工作提供了一个明确的焦点。
-
粒子群优化模糊神经网络在语音识别中的应用2010-05-06 0
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 0
-
卷积神经网络如何使用2019-07-17 0
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 0
-
如何设计BP神经网络图像压缩算法?2019-08-08 0
-
针对Arm嵌入式设备优化的神经网络推理引擎2021-01-15 0
-
如何构建神经网络?2021-07-12 0
-
基于BP神经网络的PID控制2021-09-07 0
-
卷积神经网络一维卷积的处理过程2021-12-23 0
-
图像预处理和改进神经网络推理的简要介绍2021-12-23 0
-
ARM Cortex-M系列芯片神经网络推理库CMSIS-NN详解2022-08-19 0
-
基于自适应神经网络模糊推理的负荷预测2009-12-18 672
-
IQ测试是否能测量AI的推理能力?2018-07-17 3308
-
人工神经网络的定义2018-11-24 16055
-
深度神经网络在识别物体上的能力怎样2020-04-14 880
全部0条评论

快来发表一下你的评论吧 !
