

DeepMind提出了一种让神经网络进行抽象推理的新方法
电子说
描述
DeepMind提出了一种让神经网络进行抽象推理的新方法,类似人类的IQ测试。结果发现经典模型如ResNet得分极低,数据稍有改动就变“白痴”,而他们关注推理的架构得分高很多,如果能给出结果的符号解释,模型的预测性能和泛化性能还会显著提高。
在许多长期存在的机器学习问题中,基于神经网络的模型持续取得了令人振奋的结果,但是,开发它们推理抽象概念的能力被证明是很困难的。已有的研究解决了通用学习系统的重要特性,基于此,DeepMind的最新研究提出了一种在学习机器中测量抽象推理的方法,并解释了关于泛化(generalisation)本质的一些重要见解。
要理解为什么抽象推理对于一般智力(general intelligence)至关重要,可以思考阿基米德的名言“尤里卡!”(希腊语Eureka,意即“我发现了!”):他注意到物体的体积相当于物体溢出的水的体积,他在概念层面理解了“体积”,并因此推理出如何计算不规则物体的体积。
我们希望AI具有类似的能力。虽然目前的AI系统可以在复杂的战略游戏中击败世界冠军,但它们经常对其他看似简单的任务束手无策,特别是当需要在新环境中发现并重新应用抽象概念时。例如,如果一个AI专门训练来计算三角形的数量,那么即使是最好的AI系统也无法计算方块或任何其他先前未遇到过的对象。
因此,要构建更好、更智能的系统,理解神经网络目前处理抽象概念的方式以及它们需要改进的地方,这非常重要。为此,我们从人类智商测试(IQ测试)中测量抽象推理的方法中获得了灵感。
人类IQ测试中的推理
标准的人类IQ测试通常要求测试者运用他们从日常经验中学到的原理来解释感知上简单的视觉场景。例如,人类测试者可能已经通过观察植物生长或建筑物的搭建,在数学课上学习加法,或跟踪利息累计的银行余额等了解了“进展”这个概念(即事物某些属性可能增加的概念)。然后,他们可以在IQ题中应用这个概念来推断随着序列增加,形状的数量、大小,甚至颜色的深浅等属性。
IQ测试题1:右下角应该选哪个?

答案是A,为什么?
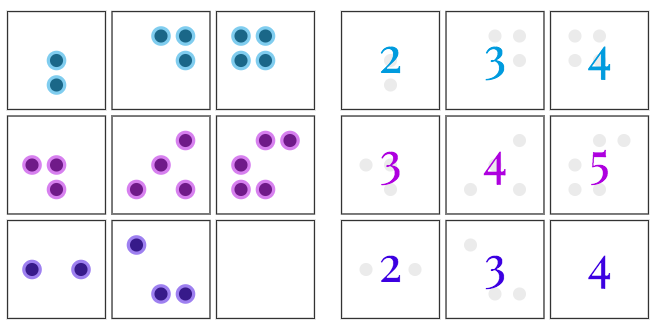
因为在每一排中,方框里黑点的数目有一种“渐增”的关系,因此右下角黑点的数量应该是4。
IQ测试题2:右下角应该选哪个?
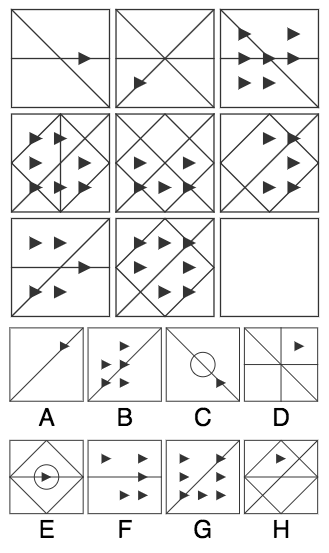
答案是A,为什么?
首先,每一列的三角形状的数目分别是1个、5个和7个,因此,右下角三角形状的数量应该是1,因此我们排除了B、F、G这三个答案,剩下A、C、D、E、H。
这道题中还需要观察“线”的关系,我们观察到每一排最右方的线是AND的关系,即同时出现在左边两个格的线才会出现在第三个格。
因此,我们得到了右下角格的线,进一步排除C、D、E、H,正确答案就是A。
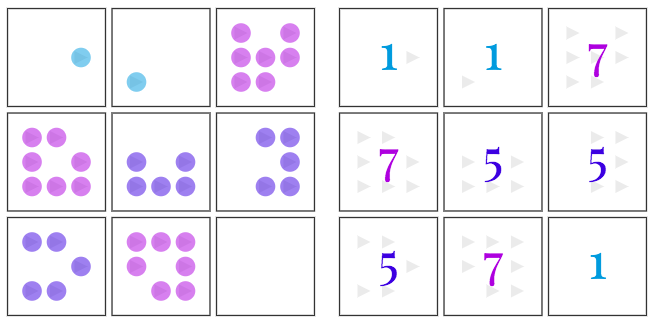
IQ测试题3:右下角应该选哪个?
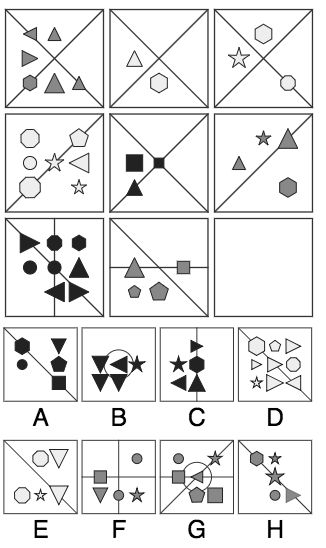
答案仍然是A,为什么?
首先,每一列的形状的数量有一种“渐增”的关系,因此右下角形状的数量应该是5个,排除D、G。
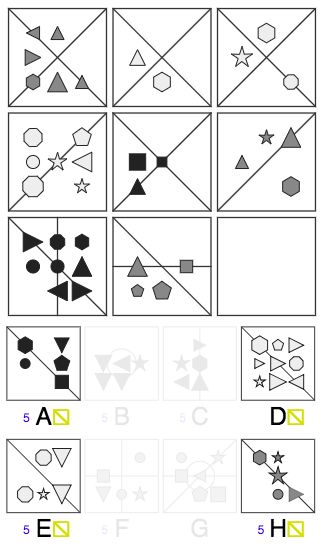
跟前一题类似,线同样是AND的关系,我们得到右下角的线,符合的只有A、D、E、H,D已经在前一步排除,因此剩下A、E、H三个选项。
再看形状颜色,每一列都分别有浅灰、深灰和黑色,因此右下角应该是黑色,得到正确答案A。
我们还没有办法让机器学习智能体接触到类似的“日常体验”,这意味着我们无法轻易地衡量它们将知识从现实世界迁移到视觉推理测试的能力。尽管如此,我们仍然可以创建一个实验设置,充分利用人类视觉推理测试。我们不是研究从日常生活到视觉推理问题的知识迁移(人类的IQ测试是如此),而是研究从一组受控的视觉推理问题到另一组视觉推理问题的知识迁移。
为实现这一目标,我们构建了一个用于创建矩阵问题的生成器,它涉及一组抽象因素,包括“进展”(progression)之类的关系以及“颜色”、“大小”之类的属性。虽然问题生成器使用了少量的潜在因素,但它仍然可以创建大量独特的问题。
接下来,我们限制了生成器可用的因素或组合,以便为训练和测试模型创建不同的问题集,从而测量我们的模型能够多大程度上推广到已配置的测试集。例如,我们创建了一组测试题的训练集,其中只有在应用于线条颜色时才会遇到“渐进关系”,而在测试集中应用于形状大小时会遇到“渐进关系”。如果模型在该测试集上表现良好,它将为推断和应用“渐进关系”这个抽象概念的能力提供证据,即使它以前从未遇见过“渐进关系”。
抽象推理的证据
在机器学习评估中应用的典型的泛化机制中,训练和测试数据来自相同的底层分布,我们测试的所有网络都表现出良好的泛化误差( generalisation error),其中一些网络实现了令人印象深刻的绝对性能。表现最好的网络显式地计算了不同图像方块之间的关系,并且并行地评估每个潜在答案的适用性。我们称这种架构为Wild Relation Network(WReN)。
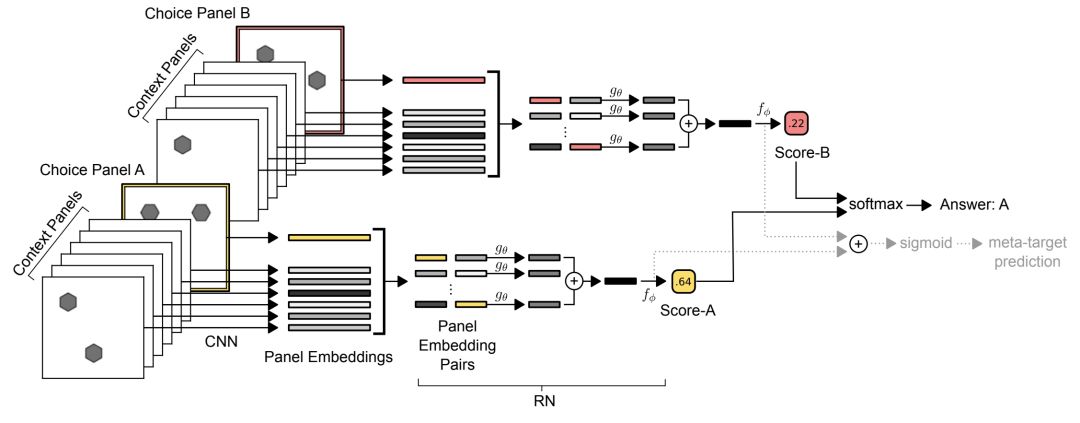
WReN模型
CNN会独立处理每个内容panel并且一个单独的回答会选择一个panel来产生9个矢量embedding。然后将这组embedding传递给RN(其输出是单个sigmoid单元),为相关答案选择panel的“得分”进行编程。 通过该网络进行8次这样的传递(为简便起见,我们仅描绘2次),每次答案选择一次,就会通过softmax函数得分以确定模型的预测答案。
当需要使用属性值在先前看到的属性值之间“内推”(interpolated),以及在不熟悉的组合中应用已知的抽象关系时,模型的泛化效果非常好。但是,同样的网络在“外推”(extrapolation)机制中表现糟糕得多,在这种情况下,测试集中的属性值与训练期间的属性值不在同一范围内。对于在训练中包含深色物体,但测试中包含浅色物体的谜题中就会出现这种情况。当模型被训练来将以前见到的关系(比如形状的数量)应用到一个新的属性(比如形状的大小)时,泛化性能也会更差。
实验结果
PGM数据集
我们将数据集称为程序生成矩阵(Procedurally Generated Matrices,PGM)数据集。为了生成PGM,受Carpenter,Wang&Su等人的启发,通过从以下原始集中随机抽样来完成的:
关系类型(R,元素是r):包括progression,XOR, OR, AND, consistent union;
目标类型(O,元素是o):包括shape,line;
属性类型(A,元素是a):包括,type,color,position,number
PGM问题—模型比较
我们首先比较了中性分裂(训练/测试)的所有模型,这与传统的监督学习制度最为接近。 也许令人惊讶的是,虽然它们是强大的图像处理器的方法,CNN模型几乎完全失败了PGM推理问题(表1),性能略微优于我们的基线 - context-blind的ResNet模型,该模型对内容视而不见并仅在八个候选答案受过训练。 LSTM按顺序考虑各个候选小组的能力,相对于CNN产生了小的改进。 性能最佳的ResNet变体是ResNet-50,其性能优于LSTM。 ResNet-50具有比我们的简单CNN模型更多的卷积层,因此具有更强的推理其输入特征的能力。
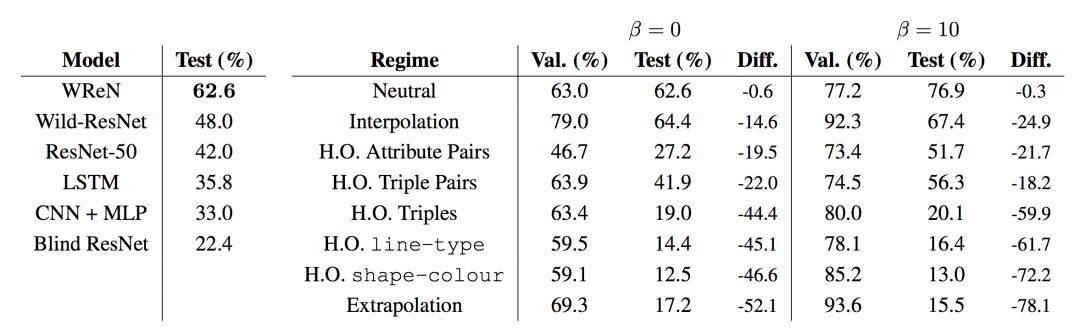
所有模型在中性分裂(左图)上的的性能,以及根据β= 0的泛化误差排序的泛化机制WReN模型(右图)的泛化性能。
性能最佳的模型是WReN模型。 这种强大的性能可能部分归因于Relation Network模块,它是为了推理对象之间的关系而明确设计的,部分是由于评分结构。 请注意,评分结构不足以解释改进的性能,因为WReN模型基本上优于最佳Wild-ResNet模型,该模型也具有评分结构。
不同问题类型的表现
涉及单个[r,o,a]三元组的问题比涉及多个三元组的问题更容易。 有趣的是,有三个三元组的PGM比四个三元组更难。 虽然有四个三元组的问题显得更为复杂,但是还有更多好的方法可以解决问题。在涉及单个三元组的PGM中,OR(64.7%)被证明是一种比XOR更容易的关系(53.2%)。具有结构涉及线(78.3%)的PGM比涉及形状的那些(46.2%)更容易,涉及形状数(80.1%)比那些涉及形状大小(26.4%)。这表明模型难以辨别细粒度的大小差异,而不是更显着的变化,如线条的缺少或出现,或形状的数量。
干扰物的影响
到目前为止报告的结果是包含干扰物属性值的问题(见图4)。 当这些干扰物被移除时,WReN模型的表现明显更好(验证组的干扰物为79.3%,测试组的干扰物为78.3%,并与干扰者为63.0%和62.6%时的情况做比较)。

离心(distraction)的影响。在两个PGM中,底层结构S 是[形状,颜色,连续单元],但是(b)包括形状数、形状类型,线颜色和线型的离心。
辅助训练的效果
然后,我们通过使用符号元目标训练我们的模型来探索辅助训练对抽象推理和概括的影响。在中立状态下,我们发现辅助训练使测试精度提高了13.9%。重要的是,模型捕获数据的整体能力的改进也适用于其他泛化机制。在将模型的三元组重新组合成新组合的情况下,差异最为明显。因此,代表抽象语义原则的压力使得它们可以简单地解码成离散的符号解释,似乎提高了模型有效地组成其知识的能力。这一发现与先前关于离散通道(discrete channel)对知识表示的优势的观察结果一致。
辅助训练分析
除了提高性能之外,使用元标记(meta-targets)进行培训还可以提供一种方法来衡量模型在给定PGM的情况下存在哪些形状,属性和关系,从而深入了解模型的策略。 使用这些预测,WReN模型在其元目标预测正确时达到了87.4%的测试准确率,而在预测不正确时仅达到34.8%。
元目标预测可以分解为对象,属性和关系类型的预测。 我们利用这些细粒度预测来询问WReN模型的准确性如何随其对每个属性的预测而独立变化。当形状元目标预测正确(79.5%)时,相比预测不正确(78.2%)时模型的精度有所提高;同样,当属性元目标预测正确(49%)时,相比预测不正确(62.2%)时模型的精度有所提高。然而,对于关系属性,正确和不正确的元目标预测之间的差异很大(86.8%对32.1%)。 这个结果表明正确预测关系属性对任务成功至关重要。
最后,当模型被训练于不仅预测正确的答案,而且预测答案的“原因”(即考虑解决这个难题的特定关系和属性)时,我们观察到了更好的泛化性能。有趣的是,在neutral split中,模型的准确性与它推断矩阵背后的关系的能力密切相关:当解释正确时,模型在87%的时候能选择到正确的答案;但当它的解释错误时,准确性下降到只有32%。这表明,当模型正确地推断出任务背后的抽象概念时,它们能够获得更好的性能。
结论
最近有一些研究关注基于神经网络的解决机器学习问题的方法的优点和缺点,通常基于它们的泛化能力。我们的研究结果表明,寻找关于泛化的普遍结论可能是无益的:我们测试的神经网络在某些泛化方案中表现良好,而在其他时候表现很差。它们是否成功取决于一系列因素,包括所用模型的架构,以及模型是否被训练来为其答案选择提供可解释的“理由”。在几乎所有情况下,当需要推断超出其经验的输入或处理完全陌生的属性时,系统的表现很差;这是一个关键且极为重要的研究领域,未来的工作可以集中于这个焦点。
-
一种产生激光脉冲的新方法2023-11-20 2336
-
一种基于MCU的神经网络模型灵活更新方案之先行篇2023-10-17 1381
-
一种基于高效采样算法的时序图神经网络系统介绍2022-09-28 2912
-
图像预处理和改进神经网络推理的简要介绍2021-12-23 1519
-
一种基于综合几何特征和概率神经网络的HGU轴轨识别方法2021-09-15 1278
-
一种基于深度神经网络的迭代6D姿态匹配的新方法2018-09-28 4744
-
测量神经网络的抽象推理能力2018-07-13 5827
-
DENSER是一种用进化算法自动设计人工神经网络(ANNs)的新方法2018-01-10 8153
-
基于GA优化T_S模糊神经网络的小电流接地故障选线新方法_王磊2016-12-31 793
-
一种标定陀螺仪的新方法2016-08-17 4252
-
神经网络在电磁场数值问题中的应用2011-05-18 828
-
传感器故障检测的Powell神经网络方法2009-07-07 514
-
基于神经网络的传感器故障监测与诊断方法研究2009-06-23 956
-
神经网络电力电子装置故障诊断技术2009-06-19 670
全部0条评论

快来发表一下你的评论吧 !
