

用人类智商测试题检验神经网络的抽象推理能力
电子说
描述
编者按:虽然神经网络模型近年来在机器学习问题上取得了令人印象深刻的成果,但无数实践也证实,这类模型很难进行抽象概念推理。即便是声称拥有良好“泛化”能力的模型,究其本质,也只能解决某几类问题。今天,DeepMind发布了一项新成果,用人类智商测试题检验神经网络的抽象推理能力,虽然这些模型的准确率都挺高,但它们却也显示了“泛化”这个词的虚假性。
抽象推理——在介绍方法前,我们首先要理解这个概念,它可以参照古希腊学者阿基米德的著名事迹:Eureka。
一次,国王请阿基米德在不破坏王冠的前提下测量它是否掺假,这使他头疼不已。洗澡时,他发现当自己坐进浴盆里后,水会溢出来,这使他想到:溢出来的水的体积正好应该等于他身体的体积,这意味着,不规则物体的体积可以精确的被计算。如果工匠往王冠里掺了假,这个王冠的体积就和原材料的体积不一样。想到这里,阿基米德快乐地裸奔进了城里,并边跑边喊叫着“Eureka!尤里卡!”!
通过意识到溢出的水等于物体体积,阿基米德在概念层面理解了体积,并解决了不规则形状物体的体积计算问题。这就是我们要探讨的抽象推理。
我们希望人工智能也能有类似的能力,虽然目前一些系统已经可以在复杂战略游戏中击败世界冠军,但它们在其他看似简单的问题上却宛如“智障”,特别是需要在新环境中重新应用抽象概念时。举个例子,如果之前我们是用三角形训练AI系统的 ,那么即便训练到最佳状态,如果我们把三角形换成正方形、圆形,这个AI就什么都不会了。
因此,为了构建更好、更智能的系统,了解神经网络处理抽象概念的方式和弱点非常重要。我们从人类智商测试中汲取灵感,发现了一种量化抽象推理的方法。
创建抽象推理数据集
在介绍数据集前,读者不妨先来测测自己的智商:

01
已知九宫格中的最后一幅图缺失,请从下列8个选项中选出最合适的一个,使之呈现一定的规律性。
点击空白处查看答案
答:计数圆点数量:第一行2,3,4,第二行3,4,5,第三行2,3,?。由此规律可得,最后一幅图应该有4个圆点,选择A。
02
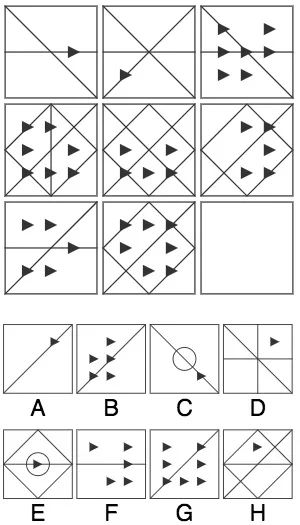
已知九宫格中的最后一幅图缺失,请从下列8个选项中选出最合适的一个,使之呈现一定的规律性。
点击空白处查看答案
答:首先,纵向来看,每一列都包含1个三角形、5个三角形、7个三角形三种图案,所以最后一幅图应该只有1个三角形,答案可能是A、C、D、E、H。其次,横向来看,第一行三幅图都有一条横线、一条左上-右下的斜线,第二行都有一个正方形,以及一条右上-左下的斜线,而第三行两幅图的相同点是都有一条右上-左下的斜线。综上,选择A。
03
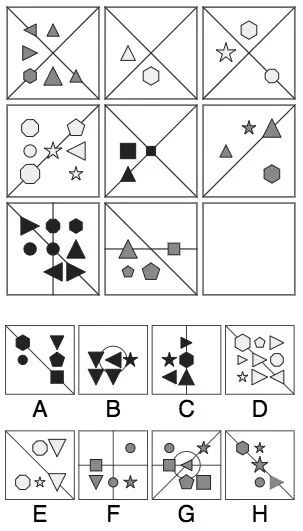
已知九宫格中的最后一幅图缺失,请从下列8个选项中选出最合适的一个,使之呈现一定的规律性。
点击空白处查看答案
答:首先,和上一题的推理方法类似,纵向来看三列都是等差数列,最后一幅图应该包含5个图形;横向来看,最后一行都有一条左上-右下的斜线,答案可能是A、E、H。其次,我们看颜色,图中有白、灰、黑三种填色,每列都包含这三种,所以最后一幅图的图形应该是黑色的。综上,选择A。
如上所示,我们在进行标准智商测试时,即便只是看几个简单图形回答问题,我们也要结合日常学习到的经验。比方说,看着不断长高的树木或是拔地而起的高楼,我们可以理解什么是“演变”(progressions);通过不断积累数学知识,我们可以理解什么是“演变”;通过查看自己银行账户上的定期利息,我们也能感受到“演变”(表示属性增加的概念)。有了这个基础,我们就能在解答上述问题时应用这一概念,推断图形数量、大小、颜色的顺序性演变。
但我们的机器学习系统还没有类似的“日常体验”,这也意味着我们没法轻易衡量它是怎么把现实世界知识用于解决抽象问题的。尽管如此,有了这些智商测试题,我们也能创建一个实验设置,来测一测现有模型的“智商”。需要注意的是,由于日常生活太复杂,这里我们用的是图形推理问题,考验的是模型如何用抽象推理把这题的解题思路推广到下一题。
既然目的是让AI做题,我们先得有题啊!当然了,手动搜集整理是不可能的,为了创建题库,首先我们构建了一个可以自动生成推理题的生成器,它包含一组抽象元素,包括它们的颜色、大小等属性的“演变”。虽然元素不多,但它们足以生成大量互不相同的问题。
接着,我们对生成器可用的元素和组合进行了约束,得到了包含不同问题的训练集和测试集,换言之,就像练习册和考卷,即便我们刷遍了练习册上的题,但老师在考卷上出的题总是新的。举个例子,在训练集中,有一种演变关系只会在线上出现,但在测试集上,这种演变却也出现在图形上,如果模型真的掌握了这种规律,无论是线条还是图形还是其他没见过的东西,它应该都能活学活用。
AI能进行抽象推理的证据
在实验中,训练数据和测试数据是从同一基础分布中采样的,即“考试”时都是常规题,难度没有提高,也没有特别的“加分题”。我们测试的神经网络都表现出了很好的泛化误差,一些模型的准确率甚至超过75%,令人惊讶。如下图所示,我们构建了一个可以明确计算不同图像元素间的关系,并在这基础上评估答案的模型WReN(Wild Relation Network),它的性能是最好的。
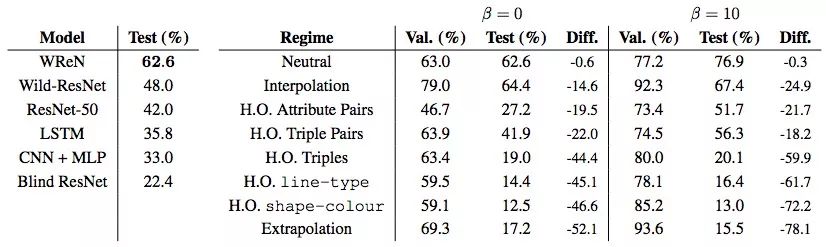
Val为训练集,Test为测试集,β非零时表示使用了meta-target训练,即针对各元素进行过训练,这时模型不仅可以回答答案“是什么”,还能回答“为什么”
但这个实验也体现了几个问题。对于训练集和测试集中都包含的相同的几何演变,比如线条上的逻辑演变,神经网络学得很好,无论线条怎么变,只要还是线条,它都能学以致用。但是如果涉及把线条的规律推广到其他图形上,神经网络就表现得很差了,这也是测试集得分比较低的主因。尤其是当模型在训练集中学到的是深色图形演变,而我们在测试集上把深色改成了浅色,它们的性能会更差。
最后,当我们的模型不仅能预测正确答案,还能预测答案的“推理过程”时,我们发现它在训练集、测试集上的得分更接近了,也就是泛化性能更好了。更有趣的是,我们发现,如果模型能理解图中各元素背后的正确关系,那它预测的准确率就高,反之,准确率就低,里面存在一个正相关。这表明,当模型能正确推断出任务背后的抽象概念时,它们可以获得更好的性能。
注:为防止读者误解,这里的“预测推理过程”“了解背后元素关系”只是口语性表述,AI并不能像我们一样一步步推理,它的“理解”也不等同于人类的理解,它只是知道,这些元素和答案有关联。
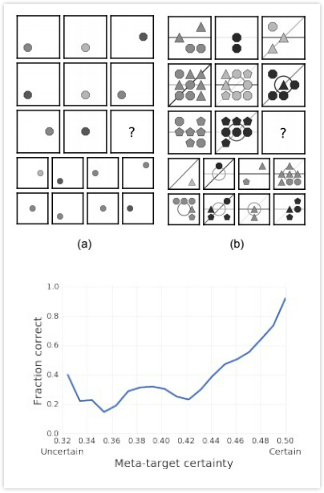
上:有些问题只包含单独元素,但有些问题包含多种元素关系;下:WReN模型答案预测准确率和抽象概念预测准确率的关系
关于“泛化”的新认知
最近许多论文在集中探讨神经网络对于解决机器学习问题的优缺点,而大家争论的矛头通常是网络的泛化能力。根据我们的研究结果,现阶段关于泛化能力的讨论似乎都是无益的:经测试,这些神经网络在一些地方展现出了很好的泛化性,但在另一些地方却表现很差。这种泛化性取决于一系列因素:
模型的架构;
模型有没有经过针对性训练;
模型能否为其“答案”提供可解释的“理由”;
起码到目前为止,只要神经网络模型遇到的是完全不熟悉的输入,或是完全不熟悉的元素,它的表现都难以令人满意。这一点是非常关键、非常重要的,AI的抽象推理能力还有待提高,这也是未来工作中必须重视一个明确焦点。
-
IQ测试是否能测量AI的推理能力?2018-07-17 3252
-
应用人工神经网络模拟污水生物处理2009-08-08 0
-
PCB工程师测试题2012-11-28 0
-
华为3Com认证网络工程师(HCNE)测试题2016-10-09 0
-
AI知识科普 | 从无人相信到万人追捧的神经网络2018-06-05 0
-
针对Arm嵌入式设备优化的神经网络推理引擎2021-01-15 0
-
如何构建神经网络?2021-07-12 0
-
基于BP神经网络的PID控制2021-09-07 0
-
卷积神经网络一维卷积的处理过程2021-12-23 0
-
图像预处理和改进神经网络推理的简要介绍2021-12-23 0
-
ARM Cortex-M系列芯片神经网络推理库CMSIS-NN详解2022-08-19 0
-
高速PCB设计的综合测试题2009-04-15 1640
-
揭秘人工智能神经网络为何无法实现人类的推理或产生意识2018-05-14 7081
-
测量神经网络的抽象推理能力2018-07-13 5193
-
DeepMind提出了一种让神经网络进行抽象推理的新方法2018-07-13 3765
全部0条评论

快来发表一下你的评论吧 !
