

一种新的表示学习方法——对比预测编码
电子说
描述
DeepMind的最新研究提出一种新的表示学习方法——对比预测编码。研究人员在多个领域进行实验:音频、图像、自然语言和强化学习,证明了相同的机制能够在所有这些领域中学习到有意义的高级信息,并且优于其他方法。
2013年,Bengio等人发表了关于表示学习( representation learning)的综述,将表示学习定义为“学习数据的表征,以便在构建分类器或其他预测器时更容易提取有用的信息”,并将无监督特征学习和深度学习的诸多进展纳入表示学习的范畴。
今天,DeepMind在最新论文Representation Learning with Contrastive Predictive Coding中,提出一种新的表示学习方法——对比预测编码(Contrastive Predictive Coding, CPC),将其应用于各种不同的数据模态、图像、语音、自然语言和强化学习,证明了相同的机制能够在所有这些领域中学习到有意义的高级信息,并且优于其他方法。

预测编码思想
使用分层的可微模型以端到端的方式从标记数据中学习高级表示,这是人工智能迄今为止最大的成功之一。这些技术使得人工指定的特性在很大程度上变得多余,并且在一些真实世界的应用中极大地改进了当前最优的技术。但是,这些技术仍存在许多挑战,例如数据效率、稳健性或泛化能力。
改进表示学习需要一些不是专门解决单一监督任务的特征。例如,当预训练一个模型以进行图像分类时,特征可以相当好地转移到其他图像分类域,但也缺少某些信息,例如颜色或计数的能力,因为这些信息与分类无关,但可能与其他任务相关,例如图像描述生成(image captioning)。类似地,用于转录人类语音的特征可能不太适合于说话者识别或音乐类型预测。因此,无监督学习是实现强健的、通用的表示学习的重要基石。
尽管无监督学习很重要,但无监督学习尚未得到类似监督学习的突破:从原始观察中建模高级表示仍然难以实现。此外,并不总是很清楚理想的表示是什么,以及是否可以在没有对特定的数据模态进行额外的监督学习或专门化的情况下学习这样的表示。
无监督学习最常见的策略之一是预测未来、缺失信息或上下文信息。这种预测编码(predictive coding)的思想是数据压缩信号处理中最古老的技术之一。在神经科学中,预测编码理论表明,大脑可以预测不同抽象层次的观察。
最近在无监督学习方面的一些工作已经成功地利用这些概念,通过预测邻近的单词来学习单词表示。对于图像来说,从灰度或image patches的相对位置来预测颜色,也被证明是有用的。我们假设这些方法卓有成效,部分原因是我们预测相关值的上下文通常是有条件地依赖于相同的共享高级潜在信息之上。通过将其作为一个预测问题,我们可以自动推断出这些特征与表示学习相关。
本文有以下贡献:
首先,我们将高维数据压缩成一个更紧凑的潜在嵌入空间,在这个空间中,条件预测更容易建模。
其次,我们在这个潜在空间中使用强大的自回归模型来预测未来。
最后,我们依赖噪声对比估计(Noise-Contrastive Estimation)损失函数,与在自然语言模型中学习词嵌入的方法类似,允许对整个模型进行端到端的训练。
对比预测编码
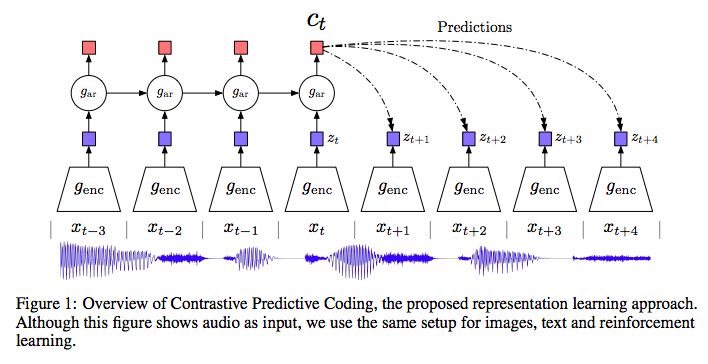
图1:对比预测编码的概览,即我们提出的表示学习方法。虽然图中将音频作为输入,但是我们对图像、文本和强化学习使用的是相同的设置。
图1显示了对比预测编码模型的架构。首先,非线性编码器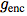 将输入的观察序列
将输入的观察序列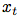 映射到潜在表示序列
映射到潜在表示序列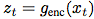 ,可能具有较低的时间分辨率。接下来,自回归模型
,可能具有较低的时间分辨率。接下来,自回归模型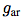 概括潜在空间中所有
概括潜在空间中所有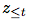 ,并生成一个上下文潜在表示
,并生成一个上下文潜在表示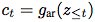 。
。
我们不是直接用生成模型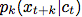 来预测未来的观察
来预测未来的观察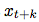 。 相反,我们对密度比建模,保留了
。 相反,我们对密度比建模,保留了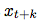
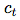 之间的交互信息,公式如下:
之间的交互信息,公式如下:

其中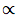 代表“成正比”。
代表“成正比”。
在我们的实验中,我们使用线性变换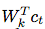 对每个步骤k进行不同
对每个步骤k进行不同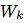 的预测,也可以使用非线性网络或递归神经网络。
的预测,也可以使用非线性网络或递归神经网络。
4个不同领域的实验:语音、图像、NLP和强化学习
我们提出四个不同应用领域的benchmark:语音、图像、自然语言和强化学习。对于每个领域,我们训练CPC模型,并通过线性分类任务或定性评估来探讨“表示”(representations)所包含的内容;在强化学习中,我们测量了辅助的CPC loss如何加速agent的学习。
语音(Audio)
对于语音,我们使用了公开的LibriSpeech数据集中100小时的子数据集。虽然数据集不提供原始文本以外的标签,但我们使用Kaldi工具包获得了强制对齐的通话序列,并在Librispeech上预训练模型。该数据集包含来自251个不同说话者的语音。
图2:10个说话者子集的音频表示的t-SNE可视化。每种颜色代表不同的说话者。
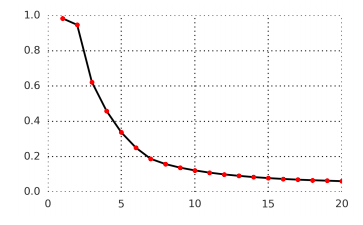
图3:在语音波形中预测未来1到20个潜在步骤的对比损失,正样本预测的平均精度。该模型最多预测未来200 ms,因为每一步包含10ms的音频。
图像(Vision)
在视觉表示实验中,我们使用ImageNet数据集。我们使用ResNet v2 101架构作为图像编码器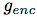 来提取CPC表示(该编码器没有经过预训练)。在无监督训练后,训练一个线性层以测量ImageNet标签的分类精度。
来提取CPC表示(该编码器没有经过预训练)。在无监督训练后,训练一个线性层以测量ImageNet标签的分类精度。
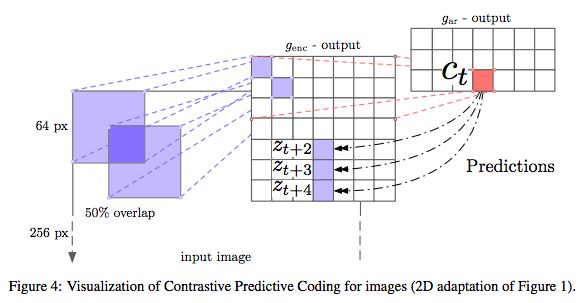
图4:图像实验中对比预测编码的可视化
图5:每一行都显示了激活CPC架构的某个神经元的image patches
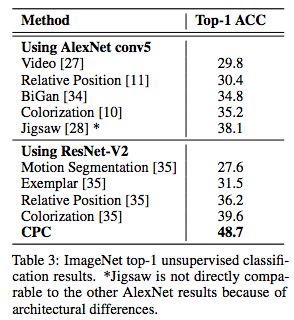
表3:ImageNet top-1无监督分类结果。
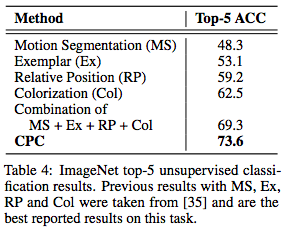
表4:ImageNet top-5无监督分类结果。
表3和表4显示了与state-of-the-art相比,CPC模型在ImageNet top-1和top-5的分类精度。尽管相对领域不可知,但CPC模型在top-1相比当前最优模型的精度提高了9%,在top-5的精度提高了4%。
自然语言
在自然语言实验中,我们首先在BookCorpus 数据集上学习我们的无监督模型,并通过对一组分类任务使用CPC表示来评估模型作为通用特征提取器的能力。
对于分类任务,我们使用了以下数据集:我们使用以下数据集:电影评论情绪(MR),客户产品评论(CR),主观性/客观性,意见极性(MPQA)和问题类型分类 (TREC)。
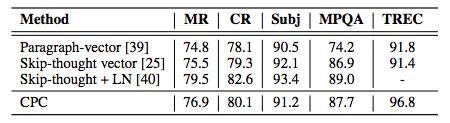
表5:五种常见NLP基准的分类精度。
评估任务的结果如表5所示。
强化学习
最后,我们评估了DeepMind Lab 在3D环境下的五种强化学习的无监督学习方法:rooms_watermaze,explore_goal_locations_small,seekavoid_arena_01,lasertag_three_opponents_small和rooms_keys_doors_puzzle。
在这里,我们采用标准的batched A2C agent作为基本模型,并添加CPC作为辅助损失。 学习的表示对其未来观察的分布进行编码。
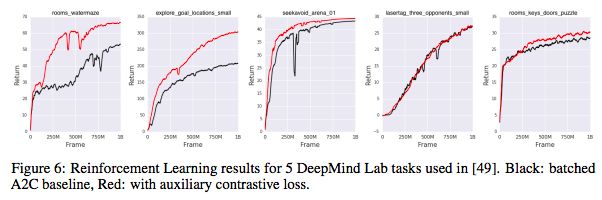
图6:五个DeepMind Lab任务的强化学习结果。黑色:batched A2C基线,红色:添加辅助对比损失
如图6所示,在10亿帧的训练后,对于5个游戏中的4个,agent的表现有明显提高。
结论
在本文中,我们提出了对比预测编码(CPC),这是一种用于提取紧凑潜在表示以对未来观测进行编码的框架。CPC将自回归建模和噪声对比估计与预测编码的直觉相结合,以一种无监督的方式学习抽象表示。
我们在多个领域测试了这些表现形式:音频、图像、自然语言和强化学习,并在用作独立特征时实现了强大的或最优的性能。训练模型的简单性和低计算要求,以及在强化学习领域与主要损失一起使用时令人鼓舞的结果,都展现了无监督学习令人兴奋的发展,并且这种学习普遍适用于更多数据模态。
-
一种实用的混沌保密编码方法2009-11-18 491
-
一种随机的人工神经网络学习方法2017-12-05 511
-
一种融合节点先验信息的图表示学习方法2017-12-18 685
-
基于概率校准的集成学习方法2017-12-22 805
-
机器学习和线性随机效应混合模型在纵向数据预测上的对比2018-01-02 998
-
一种模糊森林学习方法2018-02-23 1238
-
一种结合属性信息的二分网络表示学习方法2021-03-26 651
-
基于异质网络层次的基因节点表示学习方法2021-03-26 608
-
一种多通道自编码器深度学习的入侵检测方法2021-04-07 804
-
一种针对有向网络表示学习的优化方法2021-04-13 648
-
一种基于块对角化表示的多视角字典对学习方法2021-04-20 722
-
基于变分自编码器的网络表示学习方法2021-05-12 998
-
面向异质信息的网络表示学习方法综述2021-06-09 650
-
基于图嵌入的兵棋联合作战态势实体知识表示学习方法2022-01-11 921
-
一种创新的动态轨迹预测方法2024-10-28 436
全部0条评论

快来发表一下你的评论吧 !
