

推荐系统最新入门指南,如何公平地评估推荐系统?
电子说
描述
编者按:Tryolabs软件设计师、乌拉圭共和国大学数学教授Gastón Rodríguez最近撰写的推荐系统最新入门指南。
众多电商网站和零售商通过推荐系统来提升其销售成绩。
简单来说,推荐系统的目标是预测用户的兴趣,向用户推荐可能感兴趣的物品。
推荐系统所需的数据包括用户评分、搜索查询、购买历史,以及其他关于用户/物品的知识。
Spotify、YouTube、Netflix等站点大量使用推荐系统,向用户推荐感兴趣的信息。
这篇文章将介绍最流行的推荐系统类型,通过一些例子解释它们的工作机制。
为了给这一主题增加一些动机,我们将介绍一些真实世界的案例,讨论实现推荐系统的高层需求,还有如何公平地评估推荐系统。
实现推荐系统的优势
推荐系统可以通过非常个性化的推销和增强的用户体验增加销售。
推荐系统通常可以加速搜索,让用户更容易访问感兴趣的内容,并给用户带来惊喜。
商家可以通过发送包含感兴趣内容链接的邮件来吸引新顾客,留存老顾客。
开始感觉自己被理解的用户更可能购买更多商品,消费更多内容。了解用户所需,使商家领先于竞争者,减少客户流失的风险,同时逐渐提高利润。
推荐系统的类型
推荐系统利用两种信息:
特性信息,关于物品的信息(关键词,类别等)和用户的信息(偏好,画像等)。
用户-物品交互,例如评分、购买数、喜欢,等等。
因此,我们可以将推荐系统分为两类:
基于内容(content-based),主要使用特性信息;
协同过滤(collaborative filtering),主要基于用户-物品交互。
混合系统(hybrid system)结合了两类信息,目标是避免单独使用一种信息引发的问题。
下面,我们将深入介绍下基于内容的系统和协同过滤系统。
基于内容的系统
这类系统主要基于物品相似性和用户画像。背后的假说是,如果用户过去曾对某物感兴趣,那么以后也会对类似物品感兴趣。通常根据物品的特效归类相似物品。用户画像的构建则根据用户的历史行为,或者明确询问用户其兴趣所在。另一些不被认为纯基于内容的系统,还会利用用户的个人数据和社交数据。
这类系统的一大问题是建议过于专门(用户A对类别B、C、D表示了兴趣,系统无法向其推荐这些类别之外的其他可能感兴趣的物品)。
另一个问题是新用户没法定义画像(除非明确询问其兴趣)。相比新增用户,新增物品倒是容易得多,只需确保我们根据新物品特性将其分到了合适的分组即可。
协同过滤系统
这类系统利用用户的交互来过滤感兴趣物品。我们可以将交互的集合可视化为一个矩阵,其中每一项(i, j)代表用户i和物品j的交互。有意思的是,我们可以将协同过滤看作是对分类和回归的推广。在分类和回归中,我们的目标是预测直接依赖其他变量(特征)的变量,而在协同过滤中,并不存在特征变量和分类变量的区别。
从下图可以看到,我们并不打算预测某列的值,而是预测任何给定项的值。
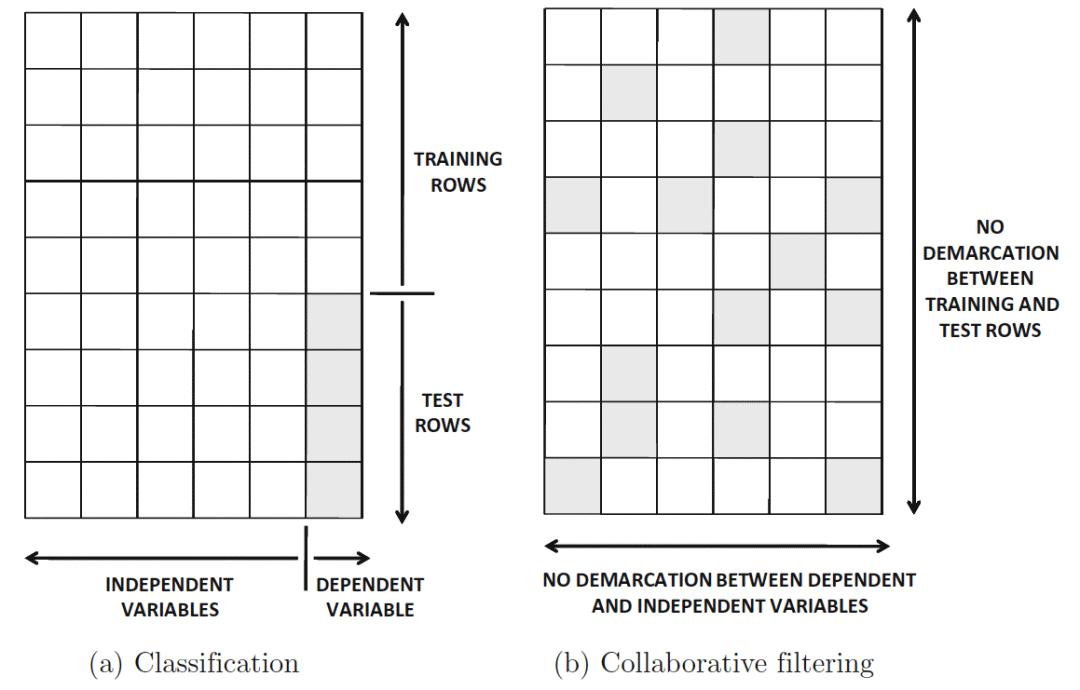
图片来源:《推荐系统》
简单来说,协同过滤系统基于这样一个假定,如果用户喜欢物品A,另一个用户也喜欢物品A,而且另一个用户同时喜欢物品B,那么第一个用户可能也对物品B感兴趣。因此,协同过滤系统基于历史交互信息预测新的交互。为了达到这一目标,有两类方法:基于内存(memory-based)和基于模型(model-based)。
基于内存
有两种方法:第一种识别用户的聚类,并利用某一特定用户的交互预测其他类似用户的交互。第二种方法识别用户A评分的物品的聚类,并基于此预测用户A和不同但相似的物品B的交互。这些方法通常会遇到的主要问题是巨大的稀疏矩阵,因为用户-物品交互的数量可能会过低,无法生成高质量的矩阵。
基于模型
这些方法基于机器学习和数据挖掘技术。其目标是训练可以做出预测的模型。例如,我们可以使用现有的用户-物品交互来训练一个模型,预测一个用户可能最喜欢的5项物品。这些方法的一个优势是,和基于内存的方法相比,可以向大量用户推荐大量物品。我们认为,即便配合大型稀疏矩阵使用,这些方法仍有更大的覆盖面(coverage)。
协同过滤系统的问题
协同过滤系统面对的两个主要挑战为:
冷启动:我们需要有足够的用户-物品交互信息,才能让系统工作。如果我们新建了一家电商网站,在用户和相当多数量的物品交互之前,我们无法给出推荐。
新增用户/物品:无论是新用户还是新物品,我们都没有关于它们的先验知识,因为它们还不存在交互。
在注册时询问用户的其他数据(性别、年龄、兴趣,等等),根据物品的元信息将其与数据库中的现有物品相关联,可以缓解上面提到的两个问题。
协同过滤实例
协同过滤是当前最常用的方法之一,并且通常能提供比基于内容的系统更好的结果。YouTube、Netflix、Spotify的推荐系统就用到了协同过滤。下面我们将介绍创建协同过滤系统的两种技术。
神经网络
一个经典方法是矩阵分解。其目标是补全评分矩阵(R)中的未知用户-物品交互。想象一下,我们通过某种方式,魔法般地得到了两个矩阵U和I,满足U × I和R的所已知项相等。那么,U × I也为我们提供了R中未知项的值,这些值可以用来生成推荐。
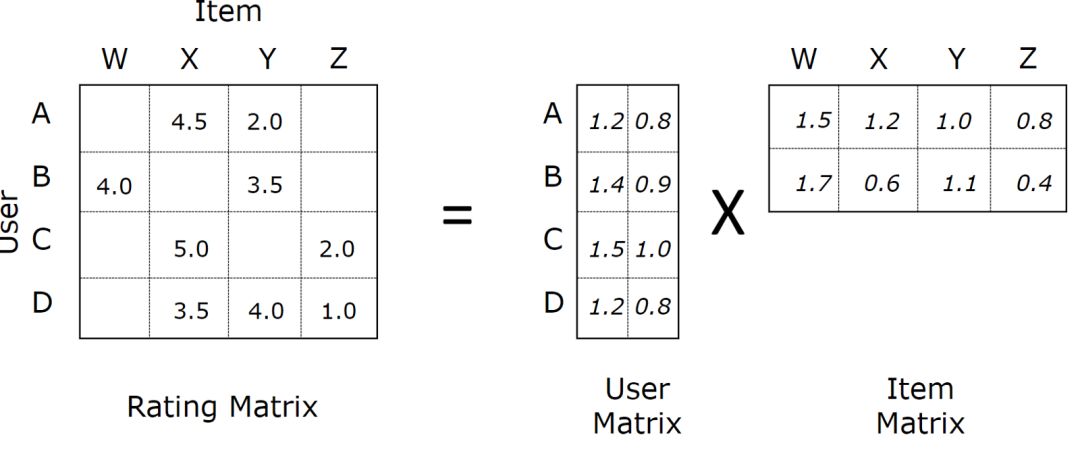
图片来源:Soumya Ghosh
找到U和I的一种时髦的方法是使用神经网络。
首先,我们需要将用户和物品映射为向量,维度分别为M和N。这意味着我们需要学习用户和物品的表示,通常称为嵌入(因为我们将这些概念嵌入一个向量空间)。由于我们尚不清楚这些向量的值,我们需要从随机初始值开始。
接着,对每个用户-物品交互(u, x)而言,我们将连接用户嵌入u和物品嵌入x为单个向量。由于我们已经知道了这一用户-物品交互的值,我们可以迫使网络对这一向量的输出等于已知值。接着,网络使用反向传播调整其权重以及嵌入,使得结果符合我们的预期。因此,网络将学习表示用户和物品的最佳方式,并通过传入所得嵌入以预测未见交互。
例如,假设上图中的用户矩阵和物品矩阵的值是随机初始化的嵌入。对交互(A, X)而言,我们将传入向量[1.2, 0.8, 1.2, 0.6],并迫使输出等于4.5。在这个例子中,我们可以使用MSE作为损失函数。如果我们的交互矩阵是二值矩阵,那么使用分类问题中常见的损失函数要更合适,比如交叉熵。
这一方法非常有趣的结果是嵌入通常包含特定的语义信息。因此,我们最后得到的并不仅仅是未知交互的预测。例如,相似用户在用户向量空间中会很接近,这有助于研究用户行为。
Item2vec
Item2vec是借鉴Word2vec思想提出的用于协同过滤的物品嵌入表示。它利用购买订单作为上下文信息,暗示在类似情况下购买的物品比较相似(相应的嵌入表示在向量空间中占据相近的位置)。
这一方法既不直接牵涉用户,也不在做出推荐时考虑用户。不过,如果我们的目标是显示用户所选物品的替代选择,那么这个方法可能非常有用(“你买了这个电视,你也许也对这些感兴趣”)。
这一方法的主要问题在于,我们需要海量数据来生成良好的嵌入。Item2vec论文用到了两个数据集,其中一个数据集包含九百万交互,七十三万二千用户,四万九千物品,另一个数据集包含三十七万九千交互,1706物品,用户数未知。
何时实现推荐系统?
既然我们现在已经对推荐系统有所了解,是时候考虑下何时值得实现推荐系统。
如果你的业务运行得不错,即使没有推荐系统,你大概也不难生存。然而,如果你想要借助数据的力量创建更好的用户体验并增加利润,你应该好好考虑下实现一个推荐系统。
投资一个良好的推荐系统是否值得?回答这一问题的一个好办法是看看实现了这样的系统的公司取得了怎样的效果:
亚马逊上35%的购买源自其推荐系统(数据来源:麦肯锡)。
2016年的双11期间,阿里巴巴的个性化到达页面对转化率的提升高达20%
YouTube上的用户观看视频时长的70%来自推荐。
Netflix上的用户观看视频的75%来自推荐(来源:麦肯锡)。
Netflix的VP和CPO发表的论文说个性化和推荐系统为Netflix每年节约十亿美元。
交叉销售和类别渗透技术增长了20%销售额,提高了30%利润(来源:麦肯锡)。
构建推荐系统的先决条件
数据是唯一最重要的资产。基本上,你需要了解用户和物品的一些细节。如果你只有元信息,那么你可以从基于内容的方法开始。如果你有大量用户交互信息,你可以试验更强大的协同过滤方法。
你所拥有的数据集越大,你的系统工作得就越好。此外,你需要确保你的团队能够理解数据,并正确地处理数据,让数据可以被你将采用的技术所用。
关于用户-物品交互,你需要了解:
你应该根据你的系统定义交互种类,以提取数据。例如,如果你运行的是一个电商网站,那么交互可能包括对物品的点击,搜索,访问,收藏夹,购买,评分,购物车中的物品,甚至是剔除掉的物品,等等。
交互可以分为显式和隐式两类。显式交互中,用户表明正面或负面的兴趣,例如评分或撰写评论。隐式交互是从用户的行为中推导出的兴趣,比如搜索或购买某物。
每个用户和物品的交互数量越多,最终结果就越好。
典型的情况是,有些非常流行的物品有大量的用户交互行为,而其他物品就没有那么多交互了,也就是长尾效应。推荐系统通常在流行物品上效果相当出色,尽管用户对此大概不是非常感兴趣,因为用户很可能已经知道这些物品了。长尾中的物品是最感兴趣的,因为如果没有推荐,用户可能甚至不会考虑到它们。
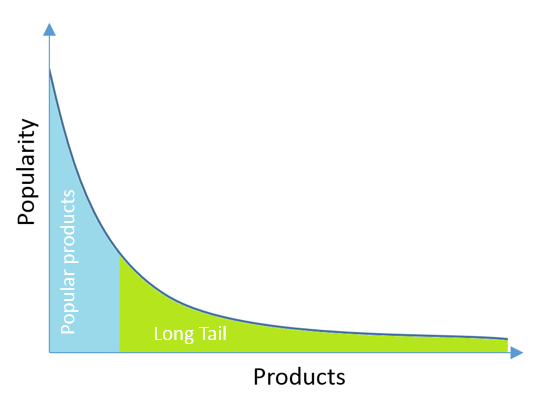
图片来源:dataminingapps.com
在运行一项新产品的同时,从头实现一个推荐系统并非易事。基于内容的方法比较方便,或者你也可以明确询问用户的兴趣。当用户和交互的数量增长时,就到了设想协同过滤方法的时候,从而增强你的系统的潜能。
最后,评估系统表现,思考提升其表现的不同方法,可能会是最艰巨的任务。但别打退堂鼓,你几乎一定能从中得到乐趣,同时你也将欣赏到利润的增长,对吧?
如何评估推荐系统?
取决于不同的目的,有不同的评估推荐系统的方法。比如,如果你只对推荐的前5项物品感兴趣(用户最可能交互的物品),那你在评估的时候就无需考虑其余的推荐。再比如,推荐的顺序对你来说可能非常重要,所以你在评估的时候需要考虑它。总的来说,推荐系统的评估方法分为两类:在线和离线。
在线方法
在线方法,又称A/B测试,通过用户对给定推荐的反应衡量推荐系统的表现。例如,你可以衡量用户是否点击推荐的物品——以及相应的转化率。这个评估方法很理想,不过难以实施。因为唯一进行试验的方法是和部署到生产环境的系统交互。而任何失败的试验很可能会对利润和用户体验造成直接影响。此外,使用真实客户进行试验,要比使用事先准备的数据慢很多。
离线方法
离线方法是试验阶段的离线方法,因为其中并不直接牵涉用户,和在线方法不同,系统无需部署到生产环境。数据被分为训练数据集和测试数据集,也就是说,部分数据用来构建系统,其余数据用来评估系统。使用离线方法时,需要小心,因为有些没有恰当表示的因素可能会影响结果。例如,时令因素(季节、气候,等等)在推荐中可能非常重要,甚至客户在某一特定时刻的心情也可能影响结果。
结语
正如你在这篇文章中看到的那样,在系统中加入推荐是一个很有吸引力的选择。从用户的视角来说,它提升了体验和参与度。从业务的角度来说,它能创造更多利润。
用户量较小时,使用一个基本的推荐系统,当用户基数增加时,再投入更强的技术,这是比较好的做法。
最不可或缺的资源是数据。如果你没有恰当地管理、储存数据,是时候采取必要措施了。一旦到达实现阶段,深入相关主题当然是很有必要的。
业务目标将指示你需要首先关注的推荐系统类型:它是要提高已活跃用户的参与度,还是让那些稀客变得更活跃。
除了定义业务目标,能够分析和理解你的站点生成的信息至关重要。有了这些,应该没什么能够阻止你成功实现你的推荐系统。
-
RA6M2群电容触控评估系统快速入门指南2023-07-04 329
-
RA 系列电机控制评估系统-RA6T1 组快速入门指南2023-03-13 398
-
RA6M2 群电容触控评估系统快速入门指南2023-02-03 412
-
LTpowerPlanner III系统级设计工具快速入门指南2022-01-14 1181
-
工业控制系统信息安全入门指南2021-08-06 1260
-
嵌入式系统电路入门知识指南速看2021-06-07 1707
-
AD9119-CBLTX-EBZ评估板快速入门指南2021-05-27 1491
-
AD9136/AD9135-EBZ评估板快速入门指南2021-05-24 1566
-
AD9119-MIX-EBZ评估板快速入门指南2021-05-13 1626
-
TSN评估套件快速入门指南2021-04-20 1169
-
CC2540 USB评估套件快速入门指南2016-03-17 1778
全部0条评论

快来发表一下你的评论吧 !
