

Linux内核的DL调度器的细节和怎么样使用DL调度器?
描述
一、前言
Linux内核的DL调度器是一个全局EDF调度器,它主要针对有deadline限制的sporadic任务。注意:这些术语已经在本系列文章的第一部分中说明了,这里不再赘述。在这本文中,我们将一起来看看Linux DL调度器的细节以及如何使用它。另外,本文对应的英文原文是https://lwn.net/Articles/743946/,感谢lwn和Daniel Bristot de Oliveira的分享。
二、细节
DL调度器是根据任务的deadline来确定调度的优先顺序的:deadline最早到来的那个任务最先调度执行。对于有M个处理器的系统,优先级最高的前M个deadline任务(即deadline最早到来的前M个任务)将被选择在对应M个处理器上运行。
Linux DL调度器还实现了constant bandwidth server(CBS)算法,该算法是一种CPU资源预留协议。CBS可以保证每个任务在每个period内都能收到完整的runtime时间。在一个周期内,DL进程的“活”来的时候,CBS会重新补充该任务的运行时间。在处理“活”的时候,runtime时间会不断的消耗;如果runtime使用完毕,该任务会被DL调度器调度出局。在这种情况下,该任务无法再次占有CPU资源,只能等到下一次周期到来的时候,runtime重新补充之后才能运行。因此,CBS一方面可以用来保证每个任务的CPU时间按照其定义的runtime参数来分配,另外一方面,CBS也保证任务不会占有超过其runtime的CPU资源,从而防止了DL任务之间的互相影响。
为了避免DL任务造成系统超负荷运行,DL调度器有一个准入机制,在任务配置好了period、runtime和deadline参数之后并准备加入到系统的时候,DL调度器会对该任务进行评估。这个准入机制保证了DL任务将不会使用超过系统的CPU时间的最大值。这个最大值在kernel.sched_rt_runtime_us和kernel.sched_rt_period_us sysctl参数中指定。默认值是950000和1000000,表示在1s的周期内,CPU用于执行实时任务(DL任务和RT任务)的最大时间值是950000µs。对于单个核心系统,这个测试既是必要的,也是充分的。这意味着:既然接受了该DL任务,那么CPU有信心可以保证其在截止日期之前能够分配给它需要的runtime长度的CPU时间。
然而,值得注意的是,准入测试对于多处理器系统的全局调度算法是必要的,但不是充分的。Dhall效应(在Deadline调度器之原理部分描述)说明了全局deadline调度器即便是接受了该任务,但是在每个CPU利用率未达100%的情况下(有可分配的CPU资源),也不能保证能该DL任务的deadline的需求得到满足。因此,在多处理器系统中,准入测试并不保证一旦接受,任务将能够在截止日期之前分配并使用其指定的运行时间。对于被接受的DL任务而言,调度器最多能做到的是“有界延迟“,对于软实时系统而言,这已经是一个不错的保证了。如果用户希望保证所有任务都能满足他们的最后期限,用户就必须使用分区方法(即使用partitioned scheduler),或者使用下面的准入测试(是必要且充分的):

把上面的公式用一句话表示就是:每个任务的(运行时间/周期)的总和应该小于或等于处理器的数目M,减去最大的利用率Umax乘以(M-1)。Umax是所有DL任务中,(运行时间/周期)值最大的那个(即对CPU资源需求最大)。事实证明,在低负荷情况下(即Umax比较小),系统容易进行调度处理。
对于那些cpu利用率很高的任务而言,一个很好的策略是将系统进行区域划分。即将一些高负载任务隔离开来,从而使“小活”(cpu使用率不高)和“大活”各自在一组不同的CPU上进行调度。目前,DL调度器不允许用户设置一个线程的亲和性,不过可以使用control group cpusets来对系统进行分区。
三、使用方法
例如,考虑一个有八个CPU的系统。一个“大活”的CPU利用率接近90%(单核场景下),而组内其他任务的利用率都较低。在这种场景下,一个推荐的设置是这样的:CPU0运行CPU利用率高的那个“大活”任务,让其他任务运行在其余的CPU上。要想实现这样的系统配置,用户可以执行以下步骤:

首先进入cpuset目录,创建两个cpuset,然后执行下面的命令:

上面的操作在root cpuset中disable了负载均衡,从而让新创建的cluster和partition这两个cpuset变成root domain。下面我们将对cluster进行配置,具体操作如下:
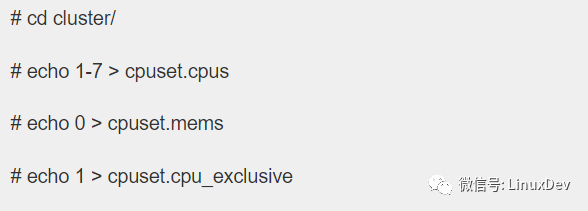
上面的操作设定了cluster中的任务可以使用1~7这些系统中的CPU,cpuset.mems那一行操作和memory node相关(即设定该cpuset可以使用的memory node),如果系统不是NUMA的话,echo 0就OK了。cpuset.cpu_exclusive 是配置cpuset.cpus中的cpu们是否是该cpuset独占的cpu。在这个场景中,CPU 1~7只是分配给cluster这个cpu set,因此是独占的。OK,现在需要把各个task加入到该cluster这个cpu set中了,具体操作如下:

上面的命令把系统中所有的LWP加入到cluster cpuset中。下面我们开始配置partition cpuset:

这里的配置过程和配置cluster的过程是一样的,这里就不再具体解释了。现在我们需要把shell移到partition这个cpuset中,操作命令如下:

完成上面的准备工作之后,最后一步就是在shell中启动deadline任务。
四、程序员视角
我们在这一章讨论使用DL调度器的场景。我们提供了三个例子:
(1)固定占有CPU资源的服务器程序
(2)按照固定的周期重新分配CPU资源的任务
(3)等待外部事件的服务器程序(外部事件可以周期性的,也可以使sporadic形态的)
周期是DL调度中最基本的参数,它定义了一个任务是以什么样子的频繁程度被激活。当一个任务没有固定的激活模式时,也可以使用DL调度器,但是这时候往往是仅仅使用其CBS特性。
我们首先举一个仅仅使用DL调度器CBS特性的例子。假设一个task,没有固定pattern,但是我们不想让它占用太多的CPU资源,仅仅是想让它最多占有20%的CPU资源。这时候,我们可以设定周期为1S,runtime是200ms,sched_setattr() 接口函数可以用来设定DL调度参数,具体的实现可以参考下面的代码:

在非周期性(aperiodic )的情况下,任务不需要知道周期何时开始,它只管运行就好了,反正在该任务消耗完指定的运行时间之后,DL调度器会对其进行节流(throttle )。这种场景下,应用程序没有deadline的需求(deadline等于period),仅仅使用CBS特性。
我们再来一个DL调度器应用场景的例子:这次是一个有固定激活模式的任务,即该任务会在固定的时间间隔上醒来,进行事务处理,而该任务处理完之后就睡眠,直到下一个周期到来。这时候在新的周期中,runtime会重新恢复,该任务会再次被DL调度器调度,然后周而复始。具体的代码和上一段代码类似,只是具体计算部分的代码如下:

具体的调度参数和上一个代码示例是一样的(即事件到来的周期是1S),虽然给出了200ms的runtime设定,但是实际上的处理不会超过200ms,一旦处理完事件,程序会调用sched_yield告知DL调度器:我已经处理完事件了,到下一个周期再给我分配资源吧,我没有什么事情需要处理了。顺便说一句,处理时间超过200ms是没有意义的,这时候CBS会throttle该任务。还有一个比较有意思的知识点就是DL调度器对yield的处理和CFS调度器不一样,DL task yield之后会阻塞该进程,直到下一个调度周期到来。
上面的例子有点类似定时任务,即每个固定的时间间隔就起来处理一些日常性事务,不过真实的实时进程往往是外部事件驱动的具体代码如下(DL参数是一样的):

在这个场景下,该任务是阻塞在系统调用中。当外部事件发生的时候,该任务被唤醒。外部事件并不是以严格的周期来唤醒该任务,但是会有一个最小的周期,也就是说这是一个sporadic task。一旦任务被激活,它将执行计算并提供响应,当该任务完成计算,提供了输出,它将由于等待下一个事件而进入休眠状态。
五、结论
deadline调度器是仅仅根据实时任务的时序约束进行调度的,从而保证实时任务正确的逻辑行为。虽然在多核系统中,全局deadline调度器会面临Dhall效应,不过我们仍然可以对系统进行分区来解决这个问题。具体的做法是采用cpusets的方法把CPU利用率高的任务放置到指定的cpuset上。开发人员也可以受益于deadline调度器:他们可以通过设计其应用程序与DL调度器交互,从而简化任务的时序控制行为。
在linux中,DL任务比实时任务(RR和FIFO)具有更高的优先级。这意味着即使是最高优先级的实时任务也会被DL任务延迟执行。因此,DL任务不需要考虑来自实时任务的干扰,但实时任务必须考虑DL任务的干扰。
DL调度器和PREEMPT_RT补丁在改善Linux实时性方面发挥着不同的作用。DL调度器让任务的调度以一种更可预测的方式进行,而PREEMPT_RT补丁集的目标是减少和限制较低优先级的任务对实时任务的调度延迟。具体的做法是通过减少下列内核中的不可抢占时间来完成的:(1)关闭抢占(2)disable IRQ(3)低优先级任务持锁。
例如,当一个实时任务运行在非实时内核上的时候,从该任务被唤醒到真正调度执行可能会有高达5ms的调度延迟。在这样的系统中,内核是无法处理deadline小于5ms的任务。相反,在实时内核的情况下,调度延迟可能不会超过150µs。这时候,那些更短的deadline的任务(例如小于5ms)也能被轻松处理。
-
深入探讨Linux的进程调度器2024-08-13 1623
-
Linux的Deadline实时调度算法2024-01-24 1722
-
什么是Linux进程调度器2023-11-09 1128
-
调度器的原理及其任务调度代码实现2022-02-17 1090
-
嵌入式工程师必会的 Linux 进程调度所有知识点2021-08-01 2887
-
带大家看看Linux内核如何调度进程的2021-07-26 2475
-
鸿蒙内核源码分析(调度机制篇):Task是如何被调度执行的2020-11-23 1711
-
Linux系统调度是实现特性的关键部分2019-07-05 1868
-
如何更改 Linux 的 I/O 调度器2019-05-15 1129
-
uClinux进程调度器的实现分析2017-11-06 903
-
Linux 2.6进程调度2009-06-13 537
-
CBS算法的RTAI内核调度器设计2009-03-29 1121
-
Linux2.4与Linux2.6内核调度器的比较研究2008-06-17 6114
全部0条评论

快来发表一下你的评论吧 !
