

EHPC通过断点续算和自动伸缩在抢占式实例上实现低成本HPC计算
今日头条
描述
摘要: E-HPC 低成本计算方案 E-HPC作为阿里云上的云超算产品将HPCaaS公共云服务提供给客户,将公共云上资源弹性优势,高性能的优势,计算资源的多样性等优势提供给HPC用户,如果HPC用户追求极致性能的HPC集群,我们可以提供SCC,裸金属服务器,EGS异构计算资源。
E-HPC 低成本计算方案
E-HPC作为阿里云上的云超算产品将HPCaaS公共云服务提供给客户,将公共云上资源弹性优势,高性能的优势,计算资源的多样性等优势提供给HPC用户,如果HPC用户追求极致性能的HPC集群,我们可以提供SCC,裸金属服务器,EGS异构计算资源。对于成本相对比较敏感的客户, E-HPC提供自动伸缩+抢占式实例+断点续算低成本计算方案,从而可以将云上普惠的高性能计算服务提供给绝大部分HPC用户:
抢占式实例保证用户的计算资源可以控制在很低的成本之下,关于抢占式实例的详细介绍,参考抢占式实例
自动伸缩可以帮助用户自动扩容,无需用户干预,用户只需要提交作业,设定抢占式实例的竞价策略, 关于E-HPC的自动伸缩,参考E-HPC自动伸缩
断点续算可以保证作业被中断之后,有新的竞价实例扩容成功之后,作业可以继续运算,而不是重新开始运算。
目前,在HPC领域,有很多研究关于MPI支持断点续算(checkpoint/restart)技术,MVAPICH2基于BLCR实现checkpoint/restart,并提供checkpoint文件管理;OpenMPI设计了模块化的checkpoint/restart机制,并有基于BLCR的实现。HPC有些领域的应用本身是支持断点续算的,例如LAMMPS, GROMACS,渲染应用里的V-Ray也是支持断点续算的。HPC常用的调度器集群也对断点续算有集成支持,Slurm与BLCR集成,也可以直接使用SCR等checkpoint系统对作业进行断点续算。LSF支持作业检查点和恢复执行。
具体案例
以下将以案例的形式介绍如何在E-HPC进行低成本计算:
LAMMPS在E-HPC上的计算
GROMACS GPU在E-HPC上的计算
用户自己开发的MPI程序如何在E-HPC上低成本计算
创建E-HPC集群
通过E-HPC控制台 创建集群
选择“竞价实例”,设定价格策略,系统自动出价或者设置最高价格
选择软件包,例如LAMMPS, GROMACS-GPU
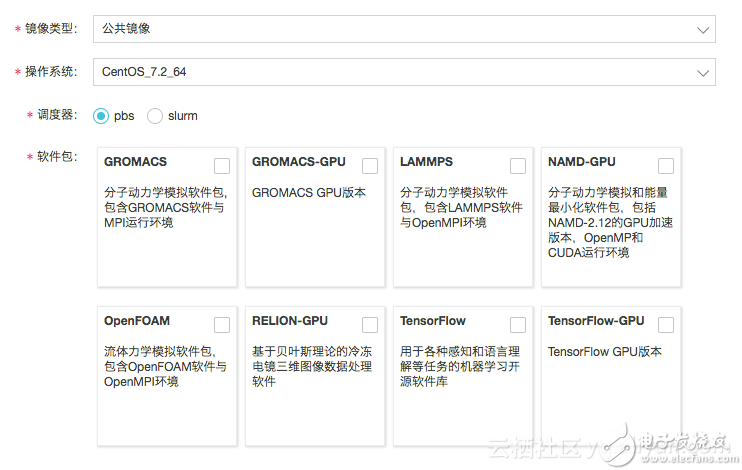
集群创建成功之后,创建用户,用于提交作业
案例一: LAMMPS
算例输入文件
本文以3d Lennard-Jones melt为例
修改算例输入文件如下, 设置每迭代100步生成一个checkpoint文件
# 3d Lennard-Jones meltunits ljatom_style atomiclattice fcc 0.8442region box block 0 20 0 20 0 20create_box 1 boxcreate_atoms 1 boxmass 1 1.0velocity all create 1.44 87287 loop geompair_style lj/cut 2.5pair_coeff 1 1 1.0 1.0 2.5neighbor 0.3 binneigh_modify delay 5 every 1fix 1 all nvedump 1 all xyz 100 /home/testuser1/sample.xyzrun 10000 every 100 "write_restart /home/testuser1/lennard.restart"
准备从checkpoint续算的输入文件
# 3d Lennard-Jones meltread_restart lennard.restart run 10000 every 100 "write_restart /home/testuser1/lennard.restart"
准备pbs的作业脚本 job.pbs, 根据是否存在checkpoint文件决定使用哪个输入文件
\#!/bin/sh\#PBS -l ncpus=1\#PBS -o lammps_pbs.log\#PBS -j oeexport MODULEPATH=/opt/ehpcmodulefiles/module load lammps-openmpi/31Mar17module load openmpi/1.10.7if [ ! -e "/home/testuser1/lennard.restart" ]; then echo "run at the beginning" mpirun lmp -in ./lj.inelse echo "run from the last checkpoint" mpirun lmp -in ./lj.restart.infi
提交作业,运行期间无中断
qsub job.pbs
作业运行结束,查看作业信息, 可以看到作业一共运行了5分28秒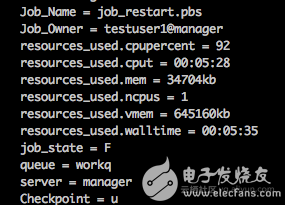
提交作业,使用自动伸缩+竞价实例+断点续算模式
在E-HPC控制台设置集群自动伸缩策略,选择扩容竞价实例,竞价策略会系统自动出价
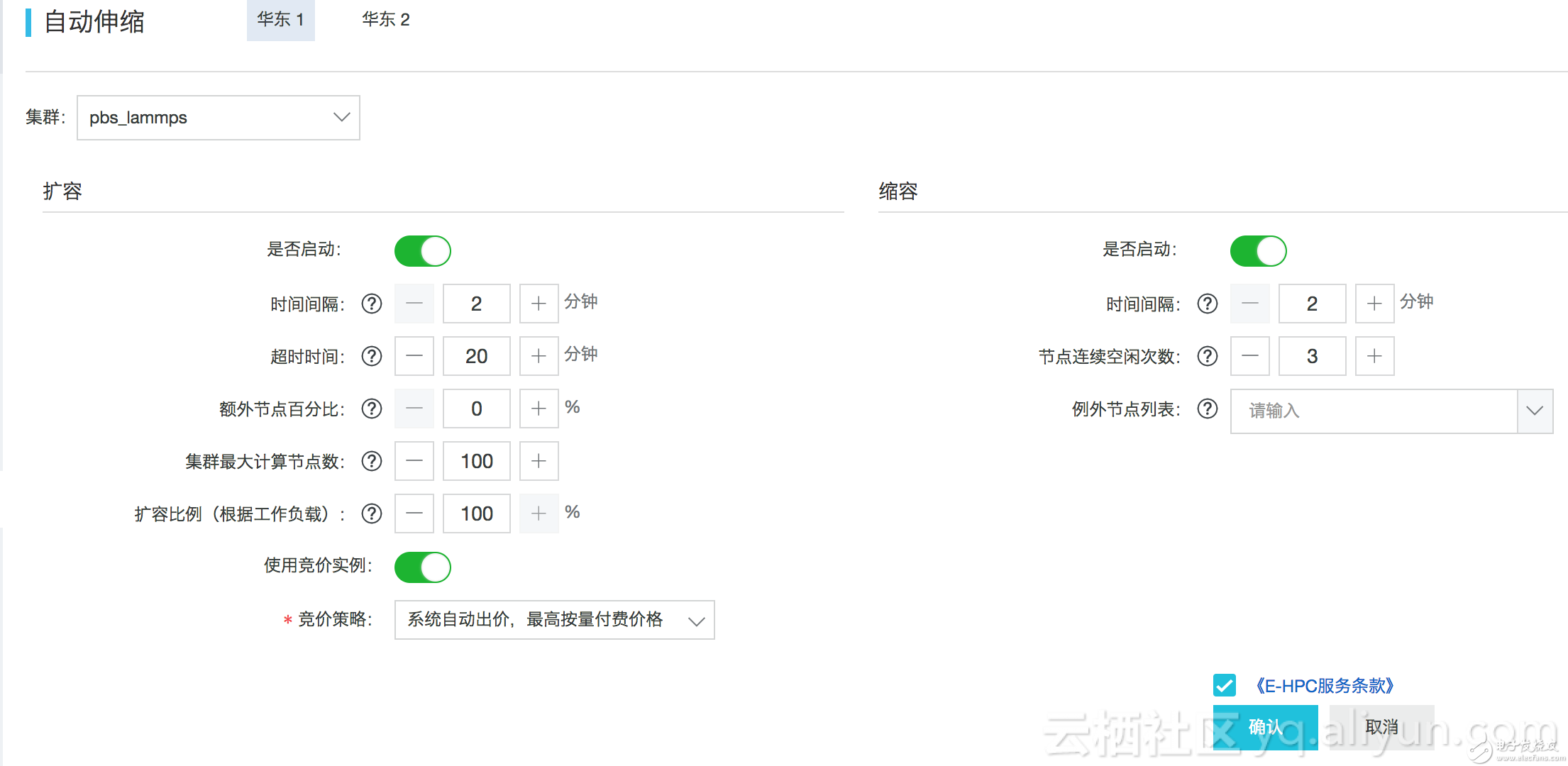
待所有计算节点释放之后,提交作业 (先删除前一个作业的续算文件lennard.restart)
job.pbs
两分钟左右可以看到自动扩容竞价实例
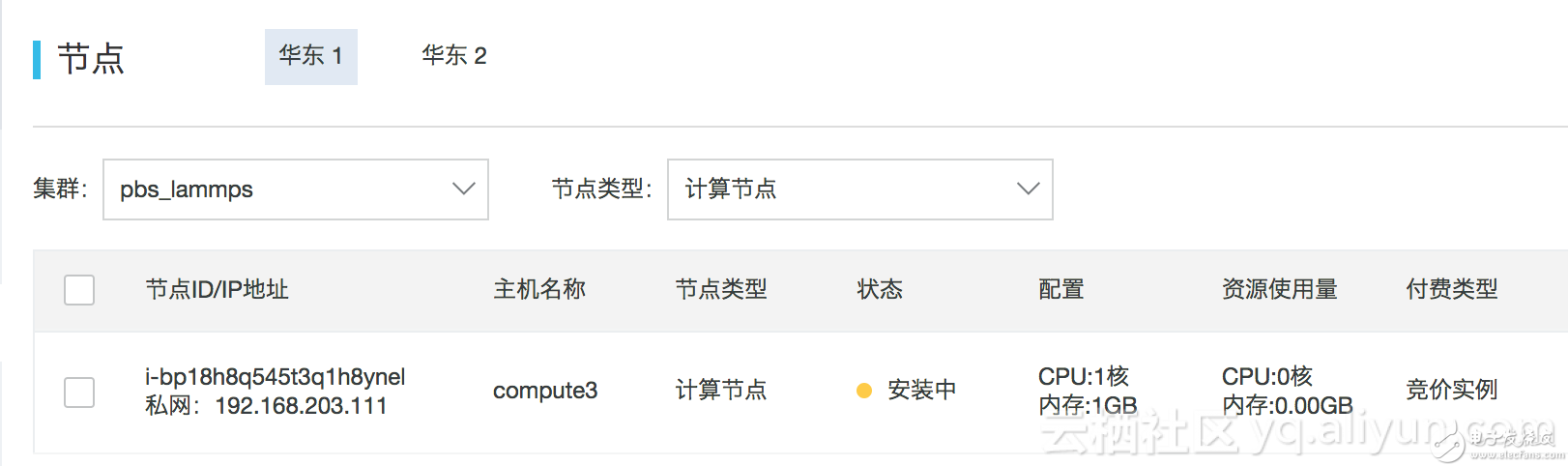
作业运行1分钟左右,在ECS控制台释放计算节点对应的竞价实例,模拟竞价实例被释放 (实际当中,竞价实例会保证至少可用1个小时),查看作业运行信息,看到作业已经运行1分47秒
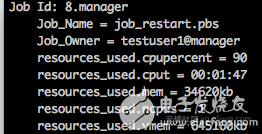
随后作业会回到queued状态,等待可用计算资源
自动伸缩服务会尝试继续扩容竞价实例直到扩容成功,然后作业会继续执行
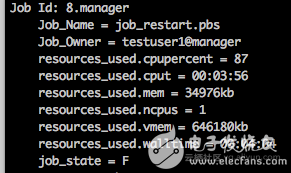
作业执行成功,查看作业信息,作业执行了3分56秒,可以看出是从断点的地方续算的
由于迭代次数比较少,结果可视化如下
主要是以用例的方式介绍了如何在E-HPC上低成本的计算LAMMPS算例,最后我们比较一下成本,本用例用的最小ECS实例规格ecs.n1.tiny, 抢占式实例最低价格为按量的1折(不同规格折扣会不同,也随时间实时变化)
计算时间增加百分比计算成本降低百分比LAMMPS作业4.57%↑88.30%↓
可以看出在运算总时间增加不大的前提下,计算成本大大降低,当然在作业提交到最终运行结束的总时长会比使用按量实例计算要长,所以很适合从时间上来说并不紧迫的作业。
案例二:GROMACS GPU
GROMACS(全称:英语:GROningen MAchine,全称格罗宁根华讯模拟体系)是一套分子动力学模拟程序包,主要用来模拟研究蛋白质、脂质、核酸等生物分子的性质。
创建E-HPC集群的时候,硬件配置阶段计算节点实例配置选择ecs.gn5-c4g1.xlarge (4核,30GB,1块P100);软件配置阶段选中GROMACS-GPU软件包
算例: 水分子运动
本算例为模拟大量水分子在给定空间、温度内的运动过程
下载water 算例
可以从GROMACS ftp直接下载解压
wget http://ftp.gromacs.org/pub/benchmarks/water_GMX50_bare.tar.gz tar xzvf water_GMX50_bare.tar.gz
在算例输入文件里设置迭代次数
vi water-cut1.0_GMX50_bare/1536/pme.mdp 设置nsteps=80000
算例的PBS作业脚本
#!/bin/sh#PBS -l ncpus=4,mem=24gb#PBS -j oeexport MODULEPATH=/opt/ehpcmodulefiles/ module load cuda-toolkit/9.0 module load gromacs-gpu/2018.1 module load openmpi/3.0.0cd /home/testuser1/test/water-cut1.0_GMX50_bare/1536 gmx_mpi grompp -f pme.mdp -c conf.gro -p topol.top -o topol_pme.tpr mpirun -np 1 gmx_mpi mdrun -ntomp 4 -noconfout -v -pin on -nb gpu -s topol_pme.tpr -cpi state.cpt -cpt 2 -append
参数说明
-cpi 选项用于指定checkpoint文件名,默认文件名是state.cpt-cpt 选项指定checkpoint文件生成和更新间隔时间,用于下一次续算,单位是分钟-append 选项指定续算产生的结果会继续写入先前的输出文件注意:在输入文件里面指定迭代次数,表示当前作业总的迭代次数 不要在命令行执行迭代次数, 例如 mpirun -np 1 gmx_mpi mdrun -ntomp 4 -noconfout -nsteps=80000 -v -pin on -nb gpu -s topol_pme.tpr -cpi state.cpt -cpt 2 -append 如果在命令行指定nsteps,表示的是一次执行过程中的总迭代次数。 会导致每次续算的时候都会继续执行总的迭代次数,而不是多次续算一共执行的迭代次数。
运行作业
首先完整执行一次该算例的作业(不发生断点再续算的情况) qsub job.pbs
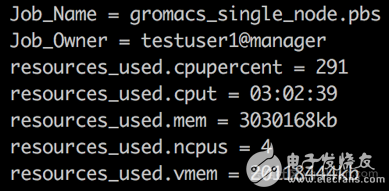
GROMACS 断点续算
下面模拟在运算过程中节点会被释放导致断点续算的情形,
首先提交作业 qsub job.pbs
自动伸缩服务会自动扩容一个ecs.gn5-c4g1.xlarge节点,观察作业使用的CPU时间 qstat -f 大概使用1个小时左右CPU时间的时候,登录ECS控制台,把计算节点对应的EGS实例强行释放,观察一下当前作业的信息
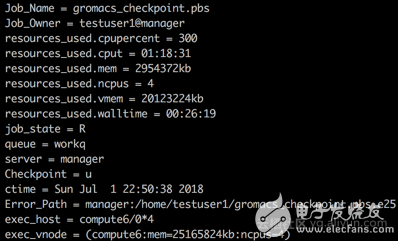
由于没有可用计算资源,作业会进入queued状态,自动伸缩服务继续尝试扩容抢占式实例
实例扩容成功,作业继续执行,直到运算完毕

比较作业计算时间和计算成本
下表列出了断点续算 (使用抢占式实例)和非断点续算(使用按量实例)同样的GROMACS案例的计算时长和计算成本比较
计算时间增加百分比计算成本降低百分比GROMACS作业13.28%↑87.17%↓
可以看出断点续算总的作业时长是会增加的,主要原因是
作业运行过程中是每隔一段时间执行一次checkpoint, 在此次测试里面,是每隔2分钟执行一次checkpoint,所以在抢占式实例被释放的时候,可能会最大损失2分钟的计算
执行checkpoint,存储作业信息到文件本身也要消耗CPU核时的
计算成本降低了87%,如果用户的作业并不紧急,并且对计算成本相当敏感,可以选择这种计算方案
案例三:用户自定义MPI程序
前面介绍了如何利用应用本身的续算功能在E-HPC上进行断点续算,对于用户自己开发的应用程序如何做到断点续算呢?尤其是用户自己的MPI跨节点运行程序如何做到断点续算呢?
开源的Checkpoint/Restart 框架
目前,有很多开源的library提供Checkpoint/Restart功能,并且常用的HPC集群调度器也支持与他们集成:
支持linux下的程序打断点以及之后从断点处续算
可以针对整个批处理作业定时打断点
如果节点异常,可以自动requeue和restart作业
Slurm, LSF, SGE等调度器类型都支持BLCR
BLCR也有很多限制,对支持的linux distro有限制,并且已经很多年没有继续维护了,最新版本是2003年的,更详细信息参见 BLCR Frequently Asked Questions.
SCR: Scalable Checkpoint/Restart for MPI
SCR是LLNL(Lawrence Livermore National Laboratory )开发的一套针对MPI程序的Checkpoint/Restart的库,提供一套完整的API供用户程序调用,用户自己决定何时何地触发checkpoint,适合用户自己开发的MPI程序使用
Checkpoint/Restart框架一般都会面临一个问题,对正在执行的进程定时checkpoint的时候,对性能(CPU cost, disk/bandwidth cost)是有一定影响的,为了降低打checkpoint对性能的影响,SCR提供了多级checkpoint机制:高频的checkpoint文件存储在节点本地磁盘,并在节点间做备份冗余,低频的checkpoint文件存储在共享文件系统中。
SCR主要提供了以下API:
SCR_Init
初始化SCR library,在MPI_Init之后立即调用SCR_Finalize
关闭SCR library, 在MPI_Finalize之前调用SCR_Route_file
获取要写入或者读取的checkpoint文件全路径, 每个MPI进程的checkpoint文件名可以设置和当前进程的rank相关SCR_Start_checkpoint
通知SCR新的checkpoint开始SCR_Complete_checkpoint
通知SCR checkpoint文件已经写入完毕SCR_Have_restart
查询当前进程是否有可用的checkpointSCR_Start_restart:
进程从指定的检查点开始启动SCR_Complete_restart
通知SCR进程已经成功读取checkpoint文件,要保证所有的MPI进程都调用SCR_Complete_restart之后才能进行后续的运算
还有一些其他的Checkpoint/Restart开发库,
例如:
DMTCP: Distributed MultiThreaded CheckPointing
CRIU
这里就不展开了
E-HPC + SCR 断点续算MPI程序
本文主要介绍如何在E-HPC上利用SCR对用户的MPI程序进行断点续算。
首先通过E-HPC控制台,创建SLURM集群 (4 compute nodes), 安装软件mpich 3.2
源代码编译安装SCR
以下操作都要ssh到登录节点上执行,
从github上clone代码
git clone https://github.com/LLNL/scr.git
安装依赖软件
yum install cmake yum install -y zlib-devel yum install -y pdsh
编译安装
export MODULEPATH=/opt/ehpcmodulefiles/ module load mpich/3.2mkdir buildmkdir /opt/scr cd buildcmake -DCMAKE_INSTALL_PREFIX=/opt/install ../scr make make installmake test // 部分testcase会fail,可以忽略
运行测试程序
作业脚本如下,
#!/bin/bashexport MODULEPATH=/opt/ehpcmodulefiles/ module load mpich/3.2 LD_LIBRARY_PATH=/opt/scr/lib SCR_FLUSH=0 mpirun ./test_api
执行以下命令提交作业
sbatch -N 4 -n 4 ./job.sh
作业输出内容如下
Init: Min 0.062187 s Max 0.062343 s Avg 0.062253 s No checkpoint to restart from At least one rank (perhaps all) did not find its checkpoint Completed checkpoint 1. Completed checkpoint 2. Completed checkpoint 3. Completed checkpoint 4. Completed checkpoint 5. Completed checkpoint 6. FileIO: Min 4.05 MB/s Max 4.05 MB/s Avg 4.05 MB/s Agg 16.21 MB/s
可以看到第一次运行,没有checkpoint文件,从头开始运行,中间阶段会产生6次checkpoint文件,
当前目录下最后保留第6次checkpoint文件, 每个MPI进程一个checkpoint文件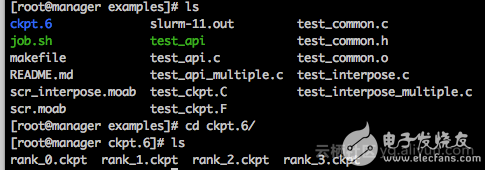
继续提交相同的作业执行一次,
sbatch -N 4 -n 4 ./job.sh
作业输出内容如下,
Init: Min 0.244968 s Max 0.245073 s Avg 0.245038 s Restarting from checkpoint named ckpt.6 Completed checkpoint 7. Completed checkpoint 8. Completed checkpoint 9. Completed checkpoint 10. Completed checkpoint 11. Completed checkpoint 12. FileIO: Min 3.17 MB/s Max 3.17 MB/s Avg 3.17 MB/s Agg 12.69 MB/s
由于有checkpoint文件存在,所以从checkpoint ‘ckpt.6’开始续算的。
这个示例主要是演示如何在E-HPC上断点续算用户自己写的MPI作业,SCR提供checkpoint/restart框架,提供完整的API用于触发checkpoint或者restart, 当然真正写到checkpoint文件里的内容是由用户自己在程序中决定的,这个是和应用程序本身的逻辑相关的。
总结
通过利用E-HPC自动伸缩服务,阿里云上的抢占式实例,应用本身支持的断点续算能力或者针对MPI程序的Checkpoint/Restart框架,可以做到在阿里云E-HPC平台上进行HPC低成本的计算模型,将云上普惠的高性能计算服务提供给绝大部分HPC用户,减少传统HPC用户迁云成本上的顾虑。
本文为云栖社区原创内容,未经允许不得转载
-
使用 ESS SDK 快速创建多实例规格伸缩配置2017-12-26 1873
-
阿里云 ESS 弹性伸缩服务新功能来袭,更全面、更自动化的使用体验2018-01-23 3577
-
阿里云弹性高性能计算产品商业化正式发布2018-02-02 3714
-
离线计算成本节省的神兵利器2018-04-04 2763
-
ESS控制台发布新功能:创建多实例规格的伸缩配置2018-04-08 3314
-
阿里云E-HPC赋能制造业仿真云弹性2018-05-18 2340
-
阿里云E-HPC联合安世亚太、联科集团共建云超算生态2018-05-28 2551
-
阿里云HPC助力新制造 | 上汽仿真计算云SSCC2018-05-31 2803
-
如何低成本实现大棚自动打药2022-10-20 24300
-
AutoScaling 弹性伸缩附加与分离RDS实例2018-07-23 908
-
通过单片机的片上CTMU外设和CVD技术实现低成本的电容式触摸感应设计2019-07-05 6636
-
HPC SIG致力openEuler上的高性能计算软件生态2021-09-26 2601
-
什么是HPC高性能计算2024-02-19 2318
-
云计算和HPC的关系2024-12-14 717
全部0条评论

快来发表一下你的评论吧 !
