

使用Chip2Chip+Aurora实现一个简单的DEMO
描述
以下文章来源于OpenFPGA,作者碎碎思
你有没有遇过这种情况:系统里有两块 FPGA 或者 FPGA + CPU + FPGA,需要它们之间高速、低延迟、可靠地互传数据,甚至需要像访问本地内存那样访问对方的寄存器与 BRAM?这时候传统的 SPI / UART /以太网通信带来的延迟、带宽与开销就显得捉襟见肘。
什么是 Chip2Chip + Aurora 通信?
先说两个组件:
Aurora 协议:Xilinx 提供的一种轻量级串行高速链路协议,适合 FPGA 间用高速串行收发器(GT 或 GTY / SERDES)连接。好处是延迟低、链路效率高。
Chip2Chip IP 核:Chip2Chip(AXI Chip2Chip)是一款由 Xilinx (AMD) 公司提供 的低引脚数、高性能AXI协议软核IP,主要用于实现多设备SoC系统中的FPGA与SoC之间的高效通信。它通过通道复用、数据宽度转换和支持多种物理层接口(如SelectIO和Aurora),能够将AXI4和AXI4-Lite接口透明地桥接起来,可以让一个 FPGA 向另一个 FPGA(或一个拥有对应 IP 的芯片)发起 AXI 或 AXI-Lite 总线访问,就好像对方走在自己的地址图里那样,读写对方的内存或寄存器。
接下来我们就使用Chip2Chip + Aurora 实现一个简单的DEMO。
实际用例
在这个例子里,用的是 Aurora 64b/66b,速率 10.3125Gbps。
Chip2Chip 的 主端会对外提供 AXI 接口(如果启用了,还会有 AXI-Lite 接口)。这样一来,不管是片上的处理器、MicroBlaze,还是其他的 AXI master,都能通过这个 IP 发起读写操作,去访问对端设备的 AXI 地址空间。
把 Chip2Chip IP 接到 Aurora 上其实很简单,主要就是连上复位、初始化逻辑,还有一些状态信号(比如 channel_up)。
在测试的时候,主端这边挂了一个 AXI Traffic Generator 来制造读写流量,通过 Chip2Chip 传过去。
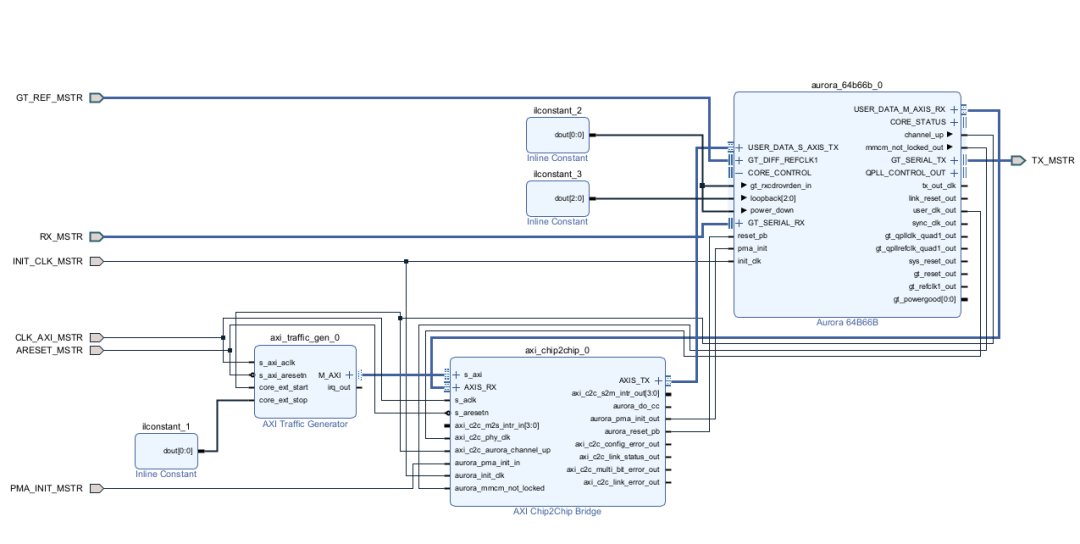
在 从端这边,随便接个 BRAM,让它当成内存映射的目标。
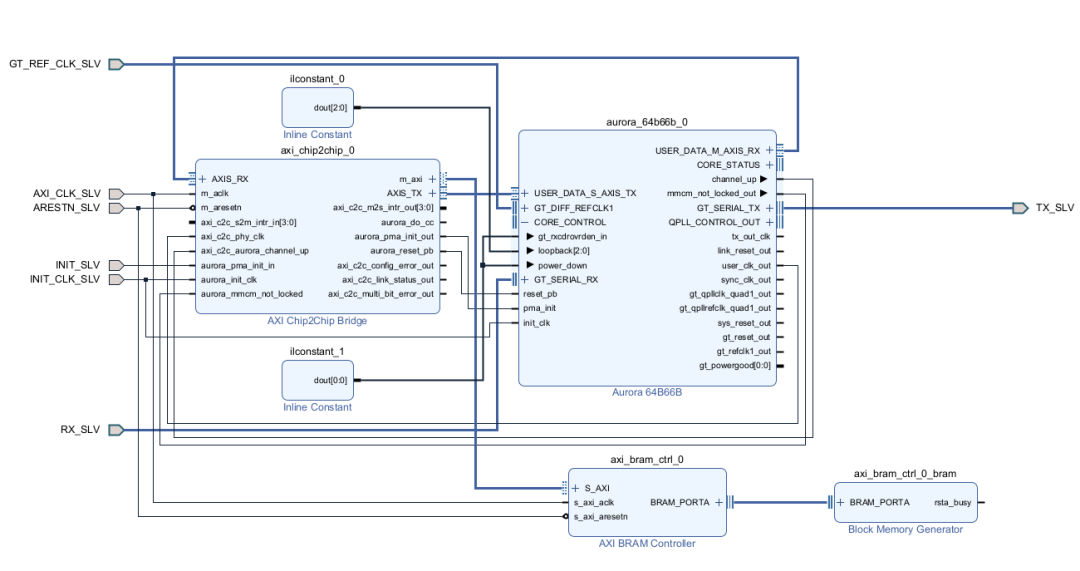
时钟这块,两边的配置保持一致:初始化时钟 50MHz,AXI 时钟 200MHz,GT 参考时钟用的是 156.25MHz。
这些子模块(BDCs)最后会组合在顶层 IP Integrator 里,里面还会连收发器(GTs)和时钟管理模块(比如 Clocking Wizard 之类的)。
要注意的一点是:主从两边的地址映射一定要对齐,否则互相访问时就会错位。
这种架构可以直接拿来仿真,不用真的接两块板子。仿真的时候你能看到:
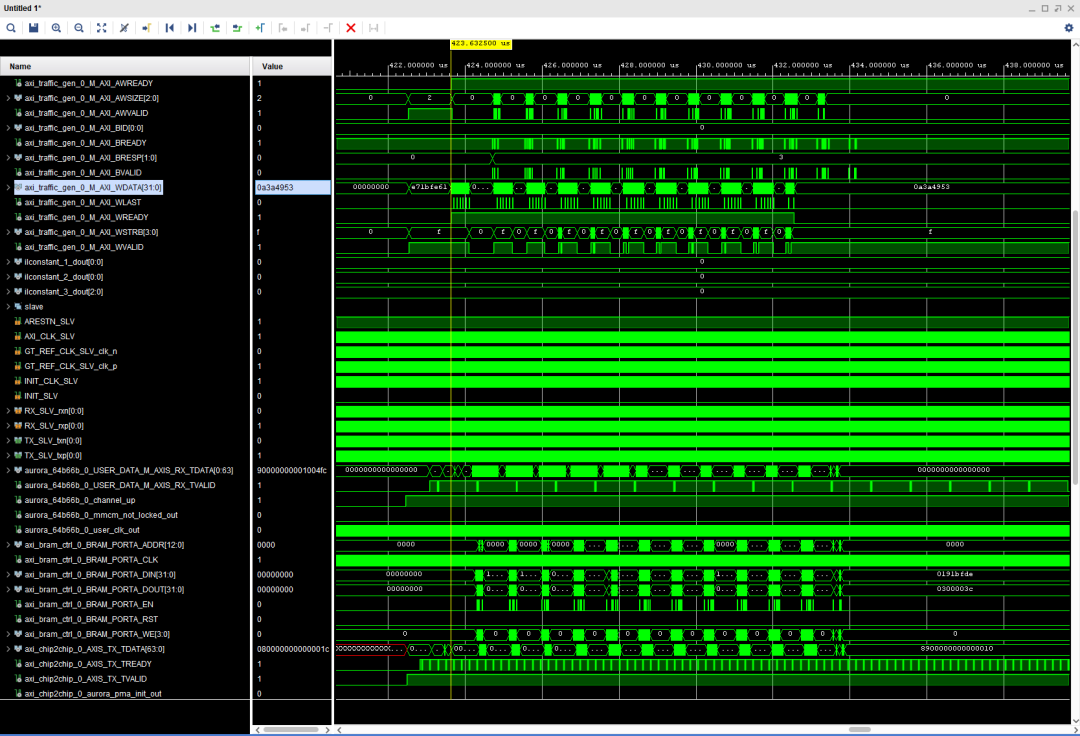
先在主端这边发起 AXI 写操作
过一小会儿,就能在从端那边看到对应的写入
开源链接
https://github.com/ATaylorCEngFIET/mz616
小结
我比较喜欢这个 IP,原因是有些场景确实很实用。比如在工业应用里,经常需要不同模块之间保持电气隔离,这时候用光纤 + Aurora + Chip2Chip 就特别合适,可以很方便地在设备之间传数据。
它让我们不必把所有交互都扔给软件来完成,也不必忍受传统通信方式那么多中间层的折损。对于追求低延迟、高确定性、模块化重用的工程项目,这一对组合确实能“提速不少”。
-
esp8266 FREERTOS 3.3中没有提供CHIP_ID函数,怎么实现获取CHIP_ID的功能?2024-07-09 353
-
die,device和chip的定义和区别2024-02-23 16263
-
什么是CHIP2024-01-15 5379
-
什么是CHIP 芯片介绍2023-08-28 7540
-
什么是芯片 CHIP2023-07-03 7187
-
CHIP标准实现全民“通信”2023-02-22 1442
-
ADPA7001CHIP参数2021-03-23 786
-
索尼公司发布2x2On-Chip Lens(OCL)解决方案2020-01-25 3190
-
CHIP1是如何知道扫描发生的?2018-12-29 2628
-
Micro chip官网现在没有DEMO源码吗?2018-03-03 4477
-
Reworking the LLP Chip Scale Pac2017-03-24 872
-
什么是Chip2010-02-22 2744
-
LED CHIP IQC检验规范2009-12-20 2007
-
Chip Monolithic Ceramic Capaci2009-10-04 936
全部0条评论

快来发表一下你的评论吧 !
