

魔视智能亮相2025人工智能计算大会
描述
近日,在由北京市发展改革委、北京市科委中关村管委会、北京市经信局、海淀区政府共同指导的2025人工智能计算大会智能驾驶创新与应用论坛上,魔视智能乘用车事业部产品线副总经理张峥发表《端到端智能驾驶演进》主题演讲。该论坛由智猩猩、车东西联合承办,在北京中关村国家自主创新示范区会议中心举行。
张峥表示,魔视智能过去十年一直以AI驱动引领新一代产品技术迭代,目前在国内及海外市场均获得了积极的认可及反馈,成为多家国内头部整车OEM的战略及重点合作伙伴。面对智能驾驶新趋势,魔视智能正积极推进智驾大模型的研究与应用。
从规则驱动到认知驱动的技术演进
张峥首先分析了传统规划控制(PNC)的局限性:"传统PNC高度依赖感知结果,基于规则的决策逻辑难以泛化,规划与感知解耦导致'信息断层',轨迹生成过于保守,规则系统无法从数据中学习新行为。"
相比之下,端到端智能驾驶正朝着更加智能化的方向发展。张峥详细比较了两段式端到端和一段式端到端的技术路线。两段式优势在于模块清晰、可解释性强,但存在信息传递"瓶颈"、对感知误差敏感等局限;一段式则能够实现感知与决策的强耦合优化,具备更强的泛化能力,但可解释性差、训练难度大。
快慢系统与VLA模型:让车辆具备"思考"能力
张峥重点介绍了魔视智能的"快慢系统" 设计理念。"快系统处理实时驾驶任务,基于VLM的慢系统负责语义理解和深度决策,这种架构让车辆真正具备了思考能力。”
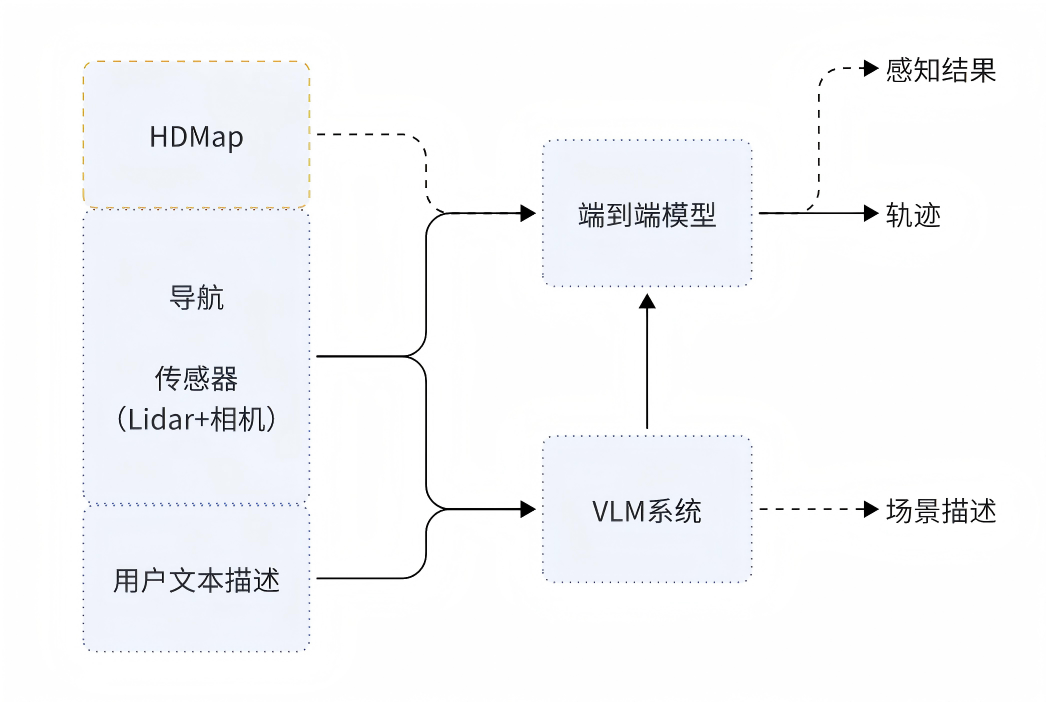
VLA(视觉语言行为)模型是一段式智能体的核心。"VLA系统能够统一建模,实现端到端闭环,具备强大的语义理解与推理能力,让车辆真正具备认知能力。"张峥表示,这将实现真正的"人机共驾"体验。
世界模型:预见未来的关键
在世界模型方面,张峥指出其能够"让车辆知道过去也能预见未来"。世界模型具备强大的环境建模与预测能力,支持"以预测驱动决策"的智能驾驶,为端到端学习提供中间表示。 "世界模型的挑战在于训练难度大、预测误差累积、计算开销大,但这正是我们重点突破的方向。"
魔视智能的端到端设计思路
张峥最后揭晓了魔视智能的端到端设计理念:"我们的目标不仅是打造一个执行者,更是要创造一个能够理解环境、预测未来、自主决策并表达意图的智能体。"
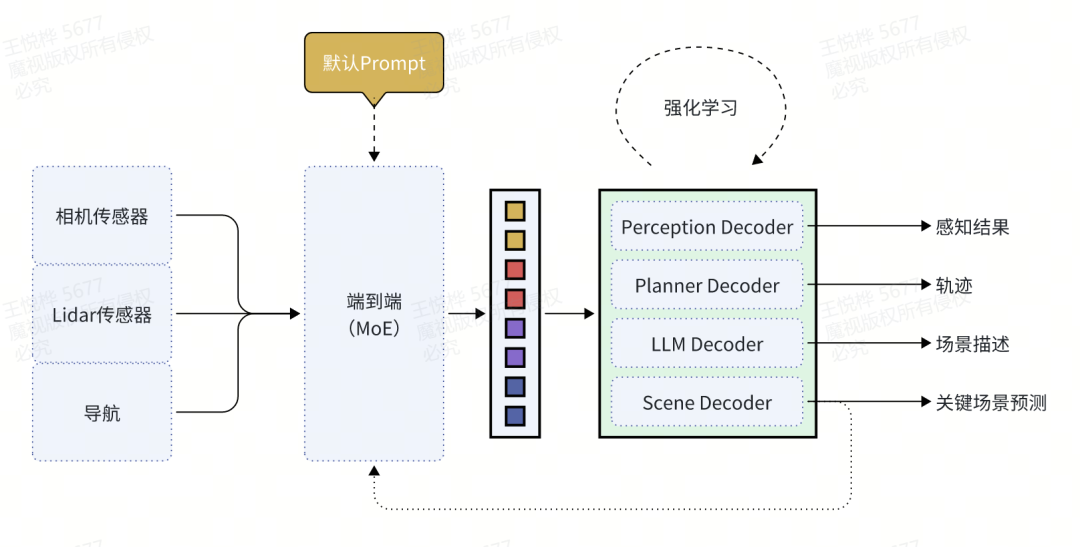
魔视智能采用金字塔式的算法模型迭代战略:以结构化感知+可解释规划控制作为安全底座,构建端到端及VLM模型提升泛化能力,最终通过认知驱动的VLA视觉语言大模型解决泛化问题和数据依赖难题。
-
云知声荣膺量子位2025人工智能年度榜单四项大奖2026-01-06 738
-
光合组织2025人工智能创新大会,高能计算机展现工业智能新图景2025-12-23 405
-
灵汐科技邀您共赴2025人工智能计算大会2025-09-19 923
-
鲲云科技即将亮相AICC 2025人工智能计算大会2025-09-18 1496
-
2025人工智能十大趋势2025-08-05 6059
-
有什么方法可以实现RK1808人工智能计算棒联网吗2022-02-16 1809
-
2018人工智能股票龙头2021-07-28 2091
-
2020年人工智能大会 线上直播2020-01-15 7369
-
2019年人工智能技术峰会落幕,大咖演讲PPT火热出炉!2019-07-02 6713
-
AI人工智能:零基础入门机器人开发教程2019-02-26 9886
-
2019人工智能博览会用AI技术联通未来世界2019-02-18 4621
-
【2019人工智能大会】大咖齐聚,共同探讨加速人工智能技术落地2019-01-21 163833
-
天津大学与中科视拓共建“人工智能联合实验室”2018-05-25 7330
-
电销机器人成为2018人工智能最热产业之一2018-05-21 4735
全部0条评论

快来发表一下你的评论吧 !
