

什么是神经架构搜索?机器学习自动化真能普及大众吗?
电子说
描述
CMU和DeepMind的研究者最近发表了一篇有趣的论文——Differentiable Architecture Search (DARTS),提出了一种替代神经架构搜索的方法,目前是机器学习的热门领域。去年,神经架构搜索被“捧”得很高,因为谷歌CEO桑德拉·皮查伊和谷歌AI的负责人杰夫·迪恩提出,神经架构搜索和大量的计算力对于机器学习的普及至关重要。于是媒体们对谷歌的这一工作进行了全面报道。

在今年3月举办的TensorFlow DevSummit大会上,杰夫·迪恩估计在未来,谷歌云可以用比目前高100倍的计算力替代人类机器学习专家。他将需要昂贵计算成本的神经架构搜索作为主要案例,解释了为什么我们需要100倍计算力才能让机器学习惠及更多人。
那么,到底什么是神经架构搜索?这是让机器学习普及的关键吗?这篇文章将重点解决这一问题。而在下篇文章中,我们会详细了解谷歌的AutoML。神经架构搜索是AutoML的一部分,在其刚刚出现时同样受到了热烈的追捧。
目录
什么是AutoML?
AutoML有多有用?
什么是神经架构搜索?
什么是DARTS?
神经架构搜索有什么用处?
除此之外还有什么方法能提高机器学习从业者的效率?
什么是AutoML?
AutoML这个术语曾被用来描述选择机器学习模型或参数优化的自动化方法。这些方法的所用的算法有很多种,例如随机森林、梯度提升、神经网络等等。AutoML包括开源的AutoML库、研讨会、研究项目和比赛。初学者可能会感觉他们只是在为模型测试不同的参数,将这一过程自动化可能会让机器学习的过程更容易,同时还能提升有经验的从业者的速度。
AutoML库有很多种,最“古老”的是AutoWEKA,于2013年发布,它可以自动选择模型和参数。其他的库包括auto-sklearn、H2O AutoML和TPOT。
AutoML有多有用?
AutoML提供了一种可以选择模型、优化超参数的方法。它同样能用来评估某一问题所处的水平如何。那么这意味着数据科学家可以被替代吗?目前还不行,因为我们需要考虑机器学习从业者实际的工作是什么。
对很多机器学习项目来说,选择一个合适的模型只是搭建机器学习产品中的一部分。在上一篇文章中,我们说过如果参与者并不理解机器学习模型各部分之间是如何连接的,这一项目可能会失败。我认为这一过程需要30多种不同的步骤,其中两个非常费时,即数据清洗和模型训练。虽然AutoML可以帮助选择模型和超参数,但是仍需要关注其他数据专家的需要和现存的问题。
在下一篇文章中,我会提出一些AutoML的替代方法,能让机器学习从业者工作得更高效。
什么是神经架构搜索?
神经架构搜索是AutoML最受人关注的部分,谷歌CEO桑德拉·皮查伊曾写道:“设计神经网络非常耗费时间,并且需要一名专家将它限制在更小的科学和工程社区里。这就是我们创建AutoML的原因,证明了我们可以让神经网络设计神经网络。”
他提到的“神经网络设计神经网络”是指神经架构搜索;通常强化学习或演化算法使用来设计新的神经网络架构的。这非常有用,因为它能让我们发现更复杂的架构,同时还能根据具体目标进行优化调整。神经架构搜索通常需要大量计算力。
准确的说,神经架构搜索经常包括学习类似图层的东西,可以组合成重复的单元以创建一个神经网络:
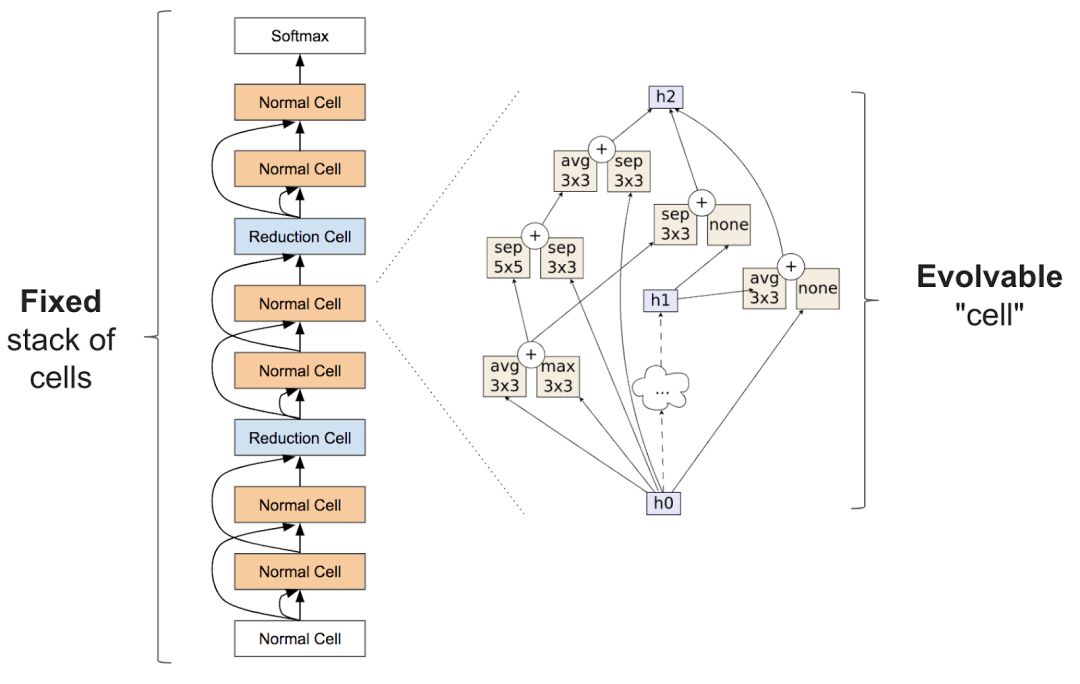
有关神经架构搜索的论文非常多,这里我们着重分析最近的几篇:
AutoML开始进入人们的视野就是由于谷歌AI的研究者Quoc Le和Barret Zoph于2017年5月在谷歌I/O大会上发表的论文:Neural Architecture Search With Reinforcement Learning。该论文使用强化学习为CV领域CIFAR10和NLP中的Penn Tree Bank问题寻找新的结构,并达到了与现有架构相似的结果。
地址:arxiv.org/pdf/1611.01578.pdf
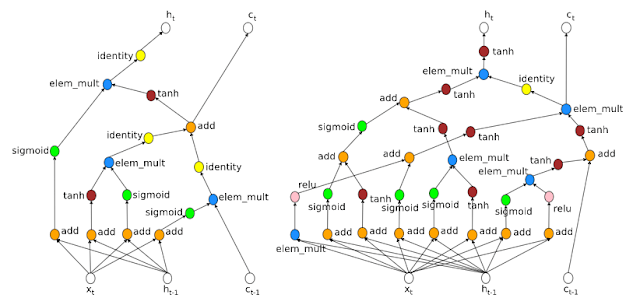
Learning Transferable Architecture for Scalable Image Recognition中的NASNet。这一项目从较小数据集(CIFAR10)中寻找建造模块,之后在大数据集(ImageNet)上搭建结构。不过这一项目也需要大量计算,需要1800个GPU(相当于用1个GPU训练5年的时间)才能学会架构。
地址:ai.googleblog.com/2017/11/automl-for-large-scale-image.html
Regularized Evolution for Image Classifier Architecture Search中的AmoebaNet。这一研究比上一个NASNet更耗费计算力,需要3150个GPU(相当于用1个GPU训练9年的时间)。AmoebaNet中包含从演化算法中训练来的单元,说明经过进化的结构可以达到甚至超越人类水平和强化学习图像分类器。fast.ai对此进行了改进,学习进程加快同时改变了训练过程中图像的尺寸后,AmoebaNet目前是在单一机器上训练ImageNet最便宜的方法。
地址:arxiv.org/abs/1802.01548
Efficient Neural Architecture Search(ENAS):该方法比之前提到的两种方法都更节省计算力,重要的是,它比标准的神经架构搜索便宜1000倍。在单一GPU上训练只花了16个小时。
地址:arxiv.org/pdf/1802.03268.pdf
什么是DARTS?
可微分的结构搜索(differentiable architecture search)是最近由CMU和DeepMind的研究人员发布的一种方法,它假设候选架构是连续而不是离散的,利用基于梯度的方法比黑箱搜索更有效。
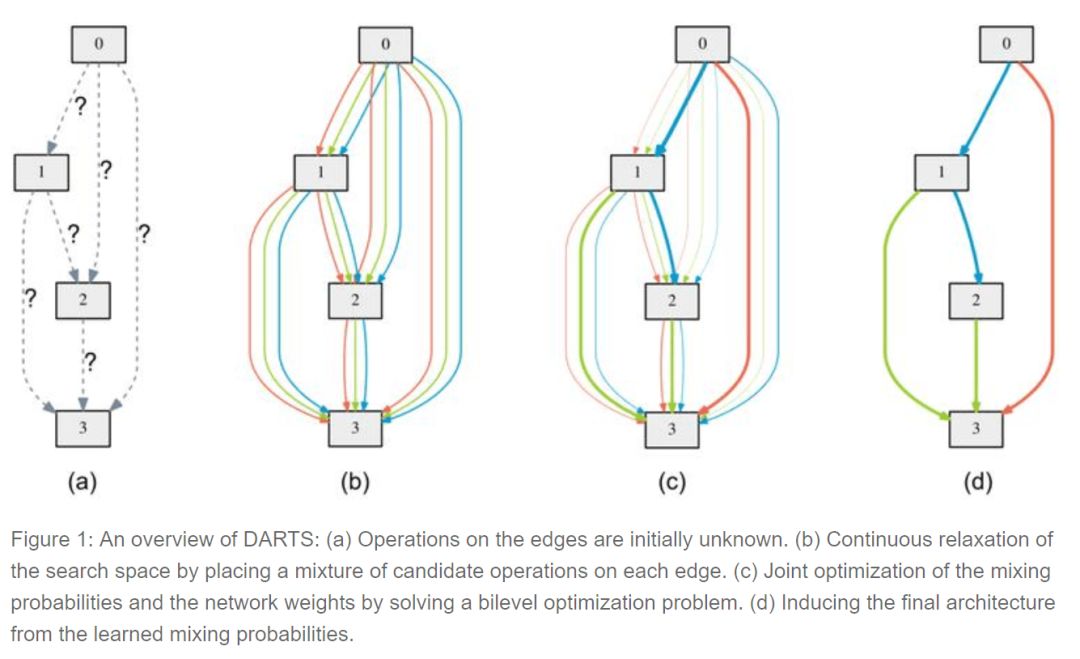
为了学习CIFAR10上的结构,DARTS只需要4个GPU,大大提升了效率。虽然还需要进一步研究,但这已经为今后的研究指明了方向。
神经架构搜索有多有用?
在TensorFlow DevSummit上,杰夫·迪恩表示深度学习的一个重要部分正尝试不同的结构。这是他在演讲中提到的唯一一个有关机器学习的观点。

然而选择模型只是复杂过程的一部分。大多数情况下,结构选择才是更难、更耗时或更重要的地方。目前,没有证据表明每个新问题最好的方法是在自身结构上建模。
像谷歌这样致力于结构设计和分享的机构为我们提供了很重要的服务。但是基础的结构搜索方法只有一小部分研究者在基础神经架构的设计上才需要使用到,我们可以直接用迁移学习得来的结构。
除此之外还有什么方法能提高机器学习从业者的效率?
AutoML领域关注的核心问题即,如何让模型选择和超参数优化自动化?然而自动化往往忽视了人类输入的重要角色。而另一个重要问题是:人类如何与计算机合作,从而让机器学习更有效呢?增强机器学习(augmented machine learning)是关注如何让人与机器更好合作的话题,其中一个案例是Leslie Smith的leaning rate finder这篇论文,其中提到学习率是一个可以决定模型训练速度的超参数,或者可以决定模型能否成功训练。学习速率查询器可以让人类很容易地找到一个良好的学习率,比AutoML更快。
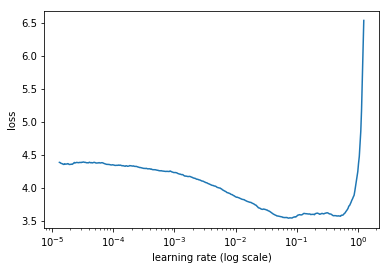
学习速率和损失之间的关系
在对超参数自动化的方法选择上还有另一个问题:一些类别的模型运用很广泛,需要调整的参数很少,对超参数的改变并不敏感,这一点常被忽略。例如,随机森林优于梯度提升机器的地方就在于随机森林更稳定,GBM对超参数微小的变化就很敏感。结果自然随机森林应用的更广泛。所以寻找能高效地改变超参数的方法将非常有用。
结语
现在我们对AutoML和神经架构搜索有了大致了解,在下一篇连载文章中,我们将近距离观察谷歌的AutoML工具。
-
【AI学习】第3篇--人工神经网络2020-11-05 0
-
机器视觉在工业自动化领域的前景应用解析2014-03-31 0
-
物联网怎么普及工业自动化2016-03-16 0
-
再牛的自动化车间都不能缺少搬运机器人2018-08-20 0
-
机器学习的相关资料下载2021-12-14 0
-
PlantStruxure协同自动化架构选型指南2017-09-27 590
-
机器学习专家们每天都在做什么?如何让机器学习自动化2018-07-19 5139
-
受机器人普及化和自动化影响 高达70%的工作岗位面临风险2019-01-25 1017
-
神经架构搜索详解2019-07-07 5092
-
随着人工智能的落地 自动化机器学习方法AutoML应运而生2019-12-02 805
-
机器流程自动化是什么2020-01-01 9224
-
如何轻松掌握机器学习概念和在工业自动化中的应用2021-01-16 3140
-
谈谈如何将机器学习引入自动化2020-10-09 2340
-
以进化算法为搜索策略实现神经架构搜索的方法2021-03-22 1137
-
DB4564_用于STM32微控制器的自动化机器学习(ML)工具2022-11-23 404
全部0条评论

快来发表一下你的评论吧 !
