

关于大端模式与小端模式的介绍
电子说
描述
数据组织是指数据的传送顺序。目前常见的32为处理器的数据总线粒度为1字节,在传送时,一个32位数据的最高字节可以放在数据总线的最低8位传送,也可以放在数据总线的最高8位传送,因此出现了大端和小端两种数据组织方法。大端是指一个数据的最高位放在数据总线的最低位传送或者放在地址较小的存储器位置存储;小端是指一个数据的最高位放在数据总线的最高位传送或者放在地址较高的存储器位置存储。Wishbone同时支持大端和小端两者数据组织方式。当数据总线的粒度和宽度相同时,大端和小端是一样的。
大端模式
所谓的大端模式(Big-endian),是指数据的高字节,保存在内存的低地址中,而数据的低字节,保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
在大端模式下,前32位应该这样读: e6 84 6c 4e ( 假设int占4个字节)
记忆方法: 地址的增长顺序与值的增长顺序相反
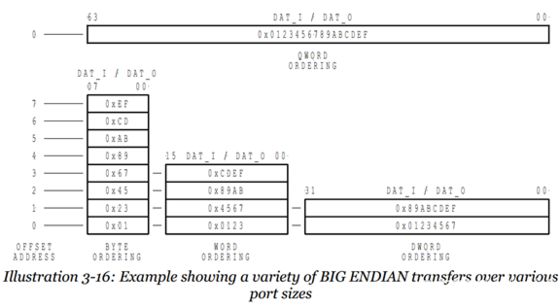
图2一个大端的例子
小端模式
所谓的小端模式(Little-endian),是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
例子:
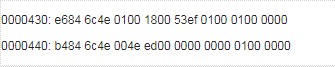
在小端模式下,前32位应该这样读: 4e 6c 84 e6( 假设int占4个字节)
记忆方法: 地址的增长顺序与值的增长顺序相同
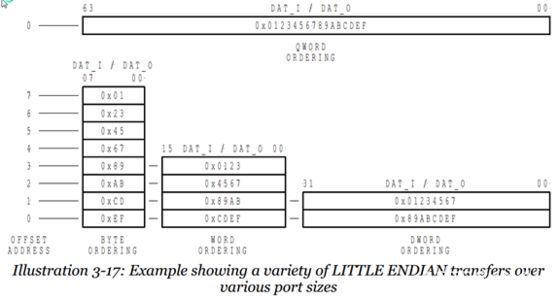
图3一个小端的例子
现状
目前Intel的80x86系列芯片是唯一还在坚持使用小端的芯片,ARM芯片默认采用小端,但可以切换为大端;而MIPS等芯片要么采用全部大端的方式储存,要么提供选项支持大端——可以在大小端之间切换。另外,对于大小端的处理也和编译器的实现有关,在C语言中,默认是小端(但在一些对于单片机的实现中却是基于大端,比如Keil 51C),Java是平台无关的,默认是大端。在网络上传输数据普遍采用的都是大端。[
这两者数据组织方式在一般文献中都可以找到。总线标准只定义接口的通信协议,而数据的组织本质上取决于主设备和从设备的设计。有时需要将大端和小端的接口互联起来,图22给出了将数据组织为大端的IP A和数据组织为大端的IP B相连的情形。IP A和IP B的数据总线宽度都是32为,粒度为8位。
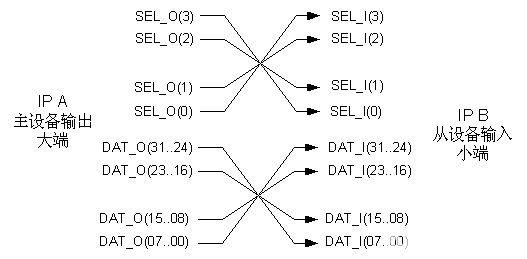
图4 22大端和小端的接口互联
-
cpu的大端模式小端模式优劣对比2017-11-08 13252
-
大端序与小端序2017-12-13 5188
-
如何知道你的MCU是大端模式还是小端模式呢2021-12-08 1345
-
大端模式与小端模式分析2021-12-16 676
-
keil怎么设置大端和小端模式?2023-09-21 1240
-
iar编译器是大端模式还是小端模式的?2023-09-25 562
-
STM32中的FLASH数据是大端模式还是小端模式?2023-10-13 752
-
请问如何配置STM32的FSMC的大端模式小端模式?2023-11-07 1071
-
tms320c6713的大小端模式介绍2011-09-02 2879
-
存储器的大端模式和小端模式2018-10-27 6222
-
单片机中的大端模式是怎么样的资料介绍2019-07-11 684
-
你真的懂CPU的大端和小端模式吗?2020-01-28 8848
-
测试MCU是大端模式还是小端模式2021-11-25 1041
-
大小端模式2021-12-29 603
-
ARM大小端模式2022-09-29 7571
全部0条评论

快来发表一下你的评论吧 !
