

中国团队Getmax为何能在高手如云的KDD Cup中脱颖而出?
电子说
描述
近日,有数据挖掘领域“奥运会”之称的KDD Cup 2018比赛结果出炉。今年的主题为空气质量预测,中国团队Getmax包揽三项大奖,获得两项第一,一项第二的好成绩。本文带来该团队亲述算法思路与技术细节。
KDD Cup是由 ACM 的数据挖掘及知识发现专委会(SIGKDD)主办的数据挖掘研究领域的国际顶级赛事,从1997年至今已有 21 年的历史。作为目前数据挖掘领域最有影响力、最高水平的国际顶级赛事,KDD Cup 每年都会吸引来自世界各地数据挖掘领域的顶尖专家、学者和工程师参赛,因此也有“大数据奥运会”之名。
与往年只有最终成绩奖项不同,KDD Cup 2018计算了比赛过程中的成绩并设立了三项大奖——“The General Track”、“最后10天专项奖”、“最佳长期预测奖”,从三个维度来奖励比赛中表现突出的队伍。而“Getmax”也因全面而突出的表现,从4000多个参赛队伍中脱颖而出,成为唯一包揽三项大奖的队伍,分别取得一项亚军、两项冠军的成绩。
如何在KDD Cup这样高手如云的国际赛事中脱颖而出?Getmax团队向新智元详细介绍了他们今年的参赛解决方案,包括如何理解空气质量问题,分析数据,特征工程,以及如何针对应用特点进行深度学习建模与优化。
背景介绍:KDD CUP 2018预测空气质量
KDD Cup 2018关注空气质量问题。在过去几年中,空气质量问题已经影响了很多发展中国家的大城市。2011年,康奈尔大学空气质量专家Dane Westerdahl在接受《洛杉矶时报》的采访时表示,有些时候,发展中国家城市的空气质量和“森林大火下风口的空气质量”相当。
在众多空气污染物中,悬浮颗粒(particulate matters,简称PM)是最致命的一种之一。直径小于或等于2.5 μm的悬浮颗粒可以进入肺部深处,进入血管,导致 DNA 突变和癌症,中枢神经系统损伤和过早死亡。
主办方在比赛中提供中国北京和英国伦敦的数据。比赛选手需要预测未来48小时内 PM2.5, PM10和O3 的浓度(伦敦只需要预测PM2.5和PM10)。
Getmanx团队介绍:
罗志鹏 微软Bing搜索广告算法工程师,北京大学软件工程专业硕士,专注于深度学习技术在NLP, 广告相关性匹配,CTR预估等方面的研究及应用。
胡可 阿里妈妈搜索直通车团队算法专家,硕士毕业于香港中文大学机器学习方向。工作技术方向为深度学习与广告算法。
黄坚强 北京大学软件工程专业硕士在读,擅长特征工程、自然语言处理、深度学习。
评测指标
每天,提交的结果将会和真实空气质量数据(也就是空气监测站测量的污染物浓度)比较,并根据Symmetric mean absolute percentage error评分:

At 是真实值,Ft是预测值。
题目特点以及常用方法
空气质量相关预测问题相对比较新,涉及的领域包括环境科学、统计学、计算机科学,近年也有机器学习方面的研究工作。国内外多个网站,APP都有对空气质量预测的应用。现有的方法主要集中于统计学以及线性回归等机器学习模型,近年也有RNN相关的研究[1],现有的模型主要预测时间段在8~24小时以内。
空气质量预测具有规律性弱,不稳定,易突变的特点。因为比赛要预测48小时时间序列以及北京/伦敦城市内几十个预测地点,建模更长的时间序列以及地理拓扑关系给机器学习模型带来挑战。
现有的方法针对的预测的时间段较短,没有基于位置拓扑以及利用天气预报进行建模,在机器学习尤其深度学习模型的运用也处于探索阶段。并且,由于比赛赛制每天需提交未来结果,相对于很多基于固定测试集的方案或比赛更接近真实工业界,对模型的稳定性以及迭代开销也有很多挑战。
比赛数据与数据分析
本题提供主要三方面数据:
空气质量数据, 主要包括以下几种重要的空气污染物:PM2.5, PM10, O3
天气气象数据:地理网格数据点的天气,温度,气压,湿度,风速,风向
未来48小时天气预报:与天气气象数据相同网格点的天气,温度,气压,湿度,风速,风向预报值
其中过去一年的数据有空气质量数据与天气数据,过去一个月的数据有天气预报数据。
首先,我们观察了北京站点2018年2月到5月之间的空气污染物(PM2.5)浓度变化情况,以北京奥体中心站点PM2.5为例,下图显示了PM2.5随时间的变化,从图中可以看出,北京的PM2.5浓度变化不定,最低能达到10以内,最高能达到350左右。并且在数小时就可以产生剧烈的变换,为预测增加了很大的难度。

特征工程
我们首先提取了每个站点过去72小时的空气质量,以及每个站点最近网格过去72小时的气象数据来作为站点的气象特征,使用这些特征构建了第一个模型。
我们发现,基于历史统计量的模型对于长期预测尤其是突变效果并不理想。以 5 月 7 号对于未来两天预测为例,下图可以看出,在 5 月 8 日到 5 月 9 日模型一的 PM2.5 浓度从 40 上升到 80 又下降到 40,而我们基于历史统计量特征的模型始终保持在 50 左右,经过数据分析我们发现,这段时间的天气发生了一定的变化,我们分析未来天气预报是问题的关键并构建相关特征。

北京奥体中心站点5月8号-5月9号的PM2.5预测值及真实值
而天气预报数据只有 2018 年 4 月 10 号后约一个月的数据,在此前一年的训练数据缺失天气预报,没法做有效的训练。所以我们使用 2018 年 4 月 10 号以前的真实气象数据代替此时段天气预报数据。
然而,由于真实天气数据与预测天气数据分布并不一致,我们采取对训练数据中的真实数据引入高斯噪声,并且考虑到短期预报与长期预报估计误差的不同,针对于不同的预测小时段进行了不同的参数估计,缓解了训练集与预测集合不一致所造成的过拟合问题。
针对于某些特殊时段天气预报预测偏差过大造成的不稳定问题,我们进一步使用分箱平滑。参照真实天气预报一个月数据的树模型训练集上的特征重要性与测试集效果进行了超参数确定。并且我们也尝试 transfer learning 等方法优化分布不一致问题,但由于最后一个月数据太少效果不稳定,并且迭代开销大没有采用。
在基于单点构建天气预报特征后,我们发现很多周围方位的天气预报信息对于当前点也有很大影响。我们由利用几百个网格数据点进行拓扑信息特征构建。首先我们针对每个城市的每个站点的 8 个临近方位角去提取 8 个网格数据点的天气预报特征。考虑到其他位置的天气如风速等会影响到当前方位的污染状况,我们也针对北京 12 个经纬度跨度较大的网格数据点作为全局预报特征,取得了较大的提升。Model1 是基于历史统计量以及初步天气预报特征模型,Model2 是细化天气预报特征与地理位置特征的模型。

北京奥体中心站点5月8号到5月9号的PM2.5预测值及真实值
我们也在其他预测日验证了模型效果。下图为两个模型在 5 月 28 号和 29 号的效果图(29 日后面有数据缺失),我们的细粒度天气预报特征也可以更好的预测趋势。图中空气质量有较大的突变,而我们的模型也捕捉到了突变趋势。突变是对于实际应用有重要应用价值的场景,在这次突变天气提交我们成绩为0.48,同当日第二名成绩 0.54 相比有明显优势。
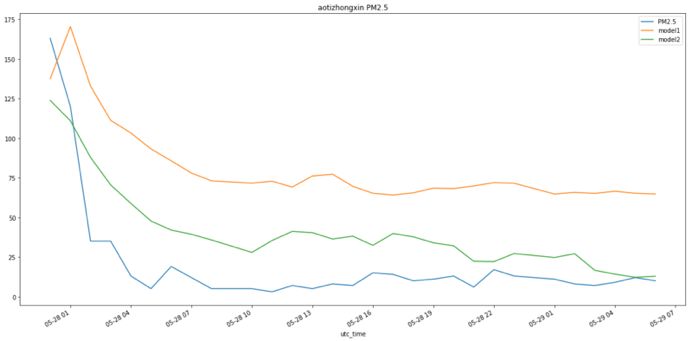
北京奥体中心站点5月28号到5月29号的PM2.5预测值及真实值
最终,特征主要分为六类:
基本特征:需预测的第几个小时,样本是在当天的第几小时,所在的经纬度等
空气质量特征:过去1,3,5……72小时的污染物浓度/过去1,3,5, 7天同小时时间污染物浓度均值,中位数,最大值,最小值等统计值,不同小时之间rate/diff等趋势特征等
天气特征:过去1,3,5……48小时平均风速,风向分箱聚合等
天气预报特征:预测时间所在小时风速风向,预测时间之前1,3,6,12小时风速平滑统计量累计值、极值等,按照风向分箱聚合等统计量等
拓扑位置相关特征:全局统计量,离当前位置最近的 8 个方位统计量,该城市 12 个方位统计量等
历史突变相关特征:历史最大/最小统计量距离当前隔多久,相隔的时间内平均统计量,极值的差,以及历史的极值之间的时间差等
我们从 2027 个特征中采用较为重要的 885 个特征,训练数据共 75 万条。
实验模型:GBDT、DNN、RNN
我们主要用采用3种模型,GBDT, DNN与RNN (Seq2Seq-GRU) 模型。由于数据分布差异很大,我们对于不同城市以及不同污染物分别建模。针对时间序列问题我们一共有 2 种建模方式,序列模型 (RNN) 是每条样本未来 48 小时的空气质量为 48 个label,而常规回归模型(GBDT/DNN)是将一条序列样本根据预测未来的 48 小时序列数展开为48条样本,每条样本预测一个状态,48 条样本间历史统计特征相同,存在二个区别:1)用hour flag标识是第几个样本;2)天气预报特征。
GBDT模型用 LightGBM 两种模型,主要用于特征迭代。针对问题特点对 DNN 模型和 RNNSeq2Seq-GRU 模型进行了优化。
DNN模型相对于 GBDT 模型有更强的特征交叉关系学习能力,并且可以学习到一些在训练集中没有出现的交叉关系,下图为 DNN 模型的结构图。

基于DNN模型,我们有如下调整与优化:
对特征进行标准化处理,计算均值和方差的时候对缺失值暂不做处理
标准化后进行特征值clip,减少离群特征值对模型的影响
对缺失值填充 0,并添加缺失标志位
使用b-swish激活函数[2],其公式为 b-swish(x) = x*sigmoid(b*x),b为可训练参数;b-swish 拥有不饱和、光滑、非单调性的特征
参考 product neural network[3]概念以及 LSTM 中的 Gate 设计,对时间与位置信息 embedding 进行了 product 以及后面 sigmoid 激活,再与模型本身的统计特征进行组合
传统的回归损失函数MSE与比赛的评分函数SMAPE有较大的差异,直接优化MSE会导致与评测目标不一致。而SMAPE在0点不可导且有临近点不稳定问题,我们为了直接优化SMAPE参照kaggle web traffic prediction比赛分享进行了损失函数逼近[4],使得模型优化与评测更一致:
epsilon = 0.1
summ = tf.maximum(tf.abs(true) + tf.abs(predicted) + epsilon, 0.5 + epsilon)
smape = tf.abs(predicted - true) / summ * 2.0
由于空气质量预测特征的噪音较大,神经网络相对于树模型对于异常值更敏感,我们做了更多的数据处理(a/b/c)。并且由于传统回归模型由于基于历史统计量相同,会有序列间预测值接近问题,以及不能很好的利用其他拓扑方位的统计信息。我们针对时间与空间概念,参考了LSTM中的 Gate,通过点乘与后续连接,增强时间/空间特征在模型中的区分度,并且相对于普通全连接网络更好建模了时间/空间信息与统计特征的组合能力。最终结果序列间预测值方差显著增加,提升了模型精度与相对于树模型的模型差异性。
同时,在基于时间/空间的点乘优化时间序列取得增益后,我们为了进一步建模时间序列,进行了 RNN 模型的尝试。使用 RNN 模型的主要好处是,能够根据上一步的模型预测信息结合当前步的输入特征进行预测当前步,并且可以对不同状态学习不同的权重。这样可以进一步使得序列间结果的方差,与常规回归建模方式形成很好的融合差异性。
下图为 RNN (Seq2Seq-GRU)模型结构:

在RNN每一步从上一步获得预测结果,并加入到当前时间步的输入特征中(以天气预报特征为主)。考虑到了模型精度以及训练速度,模型在 Encoder 和 Decoder 中均使用 GRU。
除采用在 DNN 模型中的 a/b/c/d/g 优化方法,RNN 模型有如下优化:
在 Seq2Seq 网络中加入状态间隐藏层正则项[5],解决模型不稳定的问题。
传统的 Seq2Seq 模型中 decoder 的输入信息主要来自 encoder, 由于本次任务的预测序列比较长,并且我们有天气预报这种未来信息可以用,因此我们针对 decoder 的每个时态设计了特定的特征 T1-T48(当前时态的天气预报等其他空气质量特征)。
Seq2Seq 模型训练开销大并且对于参数更敏感,我们使用 Cocob优化器[6],结合梯度截断进行训练。主要可以通过预测学习率加快收敛速度,对迭代的速度有一定帮助,也可以少量提高模型精度。
由于我们预测序列含有 48 状态,每个状态都依赖于之前状态学习,而空气质量以及天气预报数据含有大量噪音,前面序列预测不准确经常会导致后面预测偏移较大,我们使用状态间正则项,可以使得模型更稳定,提升模型精度。
由于未来每个状态均有天气预报特征,我们不同于传统的 decoder,在未来时态也输入了本状态特征(空气预报等特征),这样相对于把这些特征直接输入到 encoder 端具有更强的表达能力,并且可以缓解长序列梯度消失等问题。
模型融合
模型融合是算法大赛中常用的提高模型精度方法,有些比赛在竞争激烈的后期用了几十甚至上百模型。由于本次比赛赛制是每天早上 8 点提交,预测未来 2 天成绩,相对于静态测试集更接近真实工业届天级更新模型场景。为了平衡模型精度和迭代成本,我们用了 5 个基模型,融合结构主要是 2 层 stacking 结构[7],第1层(L1) 是基模型,主要包括 GBDT/DNN/Seq2Seq 等模型差异以及特征差异,第2层(L2) 模型 L1 模型之后的 7 天数据进行训练。基于非线性模型的L2 模型有更强的表达能力,也是我们之前比赛最常用方案之一。
由于天气数据噪音重等数据特点,采用非线性模型如GBDT易引起模型过拟合。我们最终根据融合建模特点采用基于约束的线性模型,并且我们基于时间,地点等多个维度进行了统计,发现不同模型在不同预测段之间的相对精度有一定差异,不同于一个整体的L2模型,我们对每一个预测小时分别求解一个L2模型,精度有进一步提升。相对于L2在基于约束的线性模型的基础上基于统计适当引入非线性,取得表达能力与泛化能力的一个平衡。
下面是单模型和融合模型的结果,相对于更依赖网络调优的深度学习模型, GBDT 模型更依赖于特征工程,深度学习与树模型本身有较强的差异性产生较大的融合增益。

空气质量预测问题不同于KDD Cup 早年的一些广告、推荐类题目,已经在工业届有了大量应用,我们的努力也是做了初步探索。我们先是从数据与特征角度出发,对天气预报做了大量特征以及添加高斯噪音都处理,同时又在时间与空间维度进行进一步添加特征。而单纯从特征角度解决问题也逐渐遇到瓶颈,我们进一步运用深度学习模型角度对时间以及空间角度进行进一步建模,可以与本身基于大量特征工程的树模型有很好的补充,为后续融合打下很好的基础。之后我们基于多个单模型优化最终的第二层融合模型。
在比赛中做了很多尝试,我们认为这次过程中比较重要是基于空气质量问题的理解以及找到问题的关键点,在建模过程中尽量从多方面(如特征+特征)对关键问题进行求解,从多个角度优化到高精度的模型是最终融合模型取得效果的基础与关键。
进一步工作
我们曾尝试用CNN建模地理位置拓扑关系,没有取得明显增益,考虑到地理数据不够充足以及时间有限放弃此尝试,考虑到基于地理位置的特征带来了一定的增益,地理位置的进一步建模也是有意思的进一步尝试点。
同时,在比赛中也提供了 5 年的北京历史空气质量数据,由于时间有限我们没有使用,数据的增加,以及以年为单位进行建立周期性特征也是后面的一个尝试点。
-
怎样让你的问答脱颖而出,问答规则小测验2014-04-14 8096
-
PCBA供应商如何在竞争中脱颖而出?2018-01-18 4128
-
智能穿戴企业如何在激烈的竞争中脱颖而出?2018-02-01 3305
-
为什么GaN会在射频应用中脱颖而出?2019-08-01 2675
-
巨大的汽车电子市场中国IC如何脱颖而出?2009-12-09 847
-
中兴云终端脱颖而出,荣获德国iF设计大奖!2018-03-05 5133
-
第三届“大联大创新设计大赛”晋级团队公布 55支团队脱颖而出2018-05-23 5517
-
AI黑科技新品纷纷亮相,智能制造为何能够脱颖而出?2019-07-02 1059
-
FPGA将在众多AI芯片中脱颖而出2019-09-04 1499
-
疫情期间脱颖而出 Neolix无人车业务激增2020-03-19 2914
-
为何只有丹麦“脱颖而出”,成为风电大国?2020-06-09 7725
-
“脱颖而出”的同步磁阻电机有何优势2022-08-26 3297
-
企业数字化办公,华为云 WeLink 为何能脱颖而出2023-07-03 1207
-
STM32为何在诸多的单片机中脱颖而出?2023-10-19 970
全部0条评论

快来发表一下你的评论吧 !
