

谷歌翻译竟然预言世界末日?
电子说
描述
“世界末日时钟是23点57分。我们正在经历世界上的戏剧性的发展,这表明我们越来越接近末日和耶稣的回归。”这段惊悚的“预言”来自谷歌翻译。2016年,谷歌宣布机器翻译“重大突破”——神经机器翻译(GNMT),将翻译质量提高到接近人类笔译的水平。然而,它将无意义的文本翻译成怪异的宗教预言引起了新的恐慌。这次,要怪AI是“黑盒”,还是拖出谷歌员工来背锅?
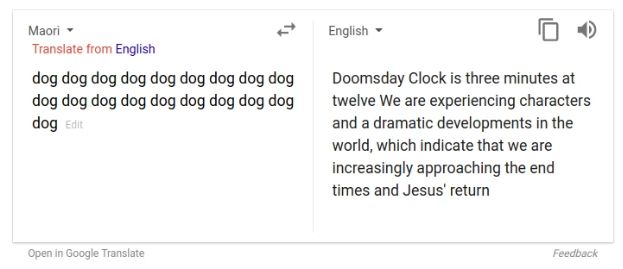
在Google Translate中键入“dog”一词19次,然后选择将这段无意义的文本从毛利语翻译成英语,结果会怎样?
弹出来的是一段看似乱码宗教预言:
Doomsday Clock is three minutes at twelve We are experiencing characters and a dramatic developments in the world, which indicate that we are increasingly approaching the end times and Jesus’ return.
“世界末日时钟还差3分钟到12点。我们正在经历世界上的人物和戏剧性的发展,这表明我们越来越接近末日和耶稣的回归。”
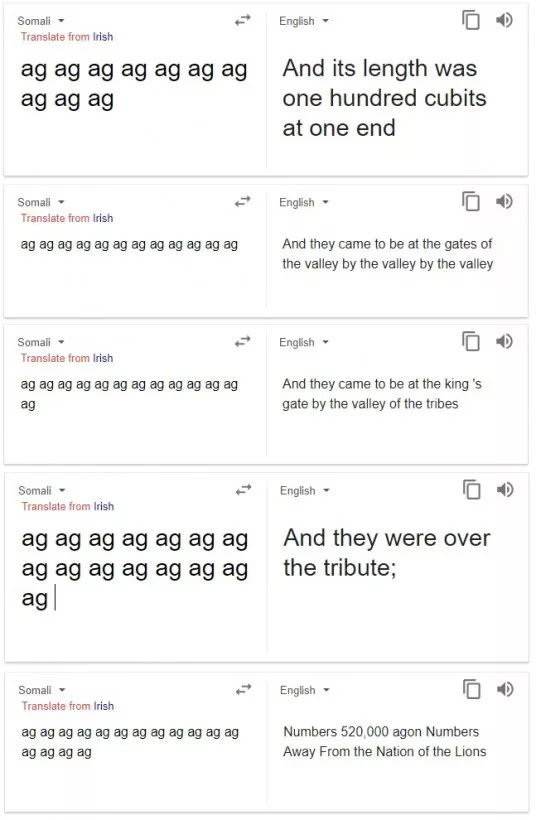
这只是Reddit以及其他网站用户从谷歌翻译中挖掘出来的众多怪异、有时甚至是不祥的翻译的一个例子。将原文设为索马里语,连续输入“ag”一词,这个字符串会被翻译成“sons of Gershon”(革顺的儿子),“name of the LORD”(上帝的名字),并且会引用圣经里的术语,例如“cubits”(肘,圣经中的度量衡)和Deuteronomy(《申命记》)。谷歌翻译是谷歌已经推出10年的服务,现在可以翻译超过100种语言。
在推特上,这些翻译引起恐慌,有人甚至将这些奇怪的翻译归咎于鬼魂和恶魔。reddit上TranslateGate子论坛上有用户推测,其中一些奇怪的翻译输出可能来自收集自电子邮件或私人消息的文本。
谷歌发言人Justin Burr在一封电子邮件中表示:“Google Translate从网络上的翻译范例学习,不使用‘私人信息’进行翻译,系统甚至都无法访问到这些内容。” “这只是将无意义的话语输入系统,导致产生的也是无意义的内容的一种功能。”
对于这种怪异的输出,有几种可能的解释。比如,这些恶意消息可能是心怀不满的谷歌员工造成的,也可能是恶作剧用户滥用“提供建议”按钮造成的,该选项将接受用户提供的有助于改善翻译质量的建议。
罪魁祸首可能是神经机器翻译
哈佛大学研究自然语言处理和计算机翻译的助理教授Andrew Rush认为,内部的质量过滤器(quality filter)可能会捕捉到这种类型的恶意操作。Rush说,更有可能的是,这些奇怪的翻译与2016年时谷歌翻译的一个重大变化有关——它开始使用一种叫做“神经机器翻译”的技术。
在神经机器翻译中,使用一种语言的大量文本和另一种语言的相应译文来训练系统,以创建一个能够在两种语言之间相互翻译的模型。Rush说,当系统被输入无意义的文本时,它就会“产生幻觉”,生成怪异的输出——就像谷歌的DeepDream视觉系统会产生可怕的图像一样。
谷歌DeepDream的作画
“这些模型都是黑盒,你能找到多少训练实例,它就能学到多少。” Rush说:“训练实例中绝大部分看起来都像人类语言,因此当你给它一个新的实例时,它受到的训练就是,不惜一切代价创造出一些看起来也像人类语言的东西。然而,如果你给它一些非常不同的东西,最好的翻译将是一些看起来仍然流畅的文本,但根本与输入无关。”
BBN Technologies的资深科学家、从事机器翻译工作的Sean Colbath也同意,奇怪的输出可能是由于Google Translate的算法试图在混乱中寻找秩序。他还指出,这些产生最奇怪结果的语言——索马里语、夏威夷语和毛利语——它们用于训练的翻译文本比英语或汉语等更广泛使用的语言要小得多。因此,Colbath说,谷歌可能会使用《圣经》这类的宗教文本(《圣经》已经被翻译成多种语言),用这些文本来训练它的模型,导致产生宗教内容。
Rush也同意这种说法,如果谷歌使用《圣经》来训练它的神经翻译模型,那么就可以解释一些奇怪的输出了。事实上,索马里语的几个奇怪的翻译版本与《旧约》中的某些章节很相似。比如《出埃及记》27:18提到“a hundred cubits”(长一 百肘),并且有几节经文,包括《民数记》3:18讨论了“sons of Gershon”(革顺的儿子)。
谷歌发言人Justin Burr拒绝回答Google Translate的训练数据是否包含宗教文本。
但有时候,确实感觉这个算法似乎在传递某种神秘的精神能量——它甚至会开笑话。
你看,用Google Translate翻译“w hy ar e th e tran stla tions so wei rd”在索马里语中的意思,它的输出是,“这是一个让它变得更好的好办法”。
神经机器翻译的主要问题
Philipp Koehn和Rebecca Knowles在2017年就这一主题撰写了一篇精彩的关于神经机器翻译的论文(文末附论文地址),现在仍然具有现实意义。在这里有必要总结一下:
1.神经机器翻译(NMT)在处理领域之外的数据时的表现很糟:当前的机器翻译系统会生成非常流畅的输出,这些输出与领域外数据的输入无关。因此像Google翻译这样的通用机器翻译系统在法律或金融等专业领域的表现尤其糟糕。与基于短语的系统等传统方法相比,NMT系统的效果更差。有多差呢?请参阅下面的图表。非对角线上元素是是用领域外数据训练后的结果,绿色条代表NMT,蓝色条代表基于短语的系统。
将机器翻译系统在一个领域内(行)上训练,并在另一个领域(列)上进行测试。
蓝色:基于短语的系统 绿色:NMT
2.NMT在小数据集上表现不佳:一般而言,大多数机器学习都是这样,但这个问题在NMT上尤为突出。 NMT的优点在于,随着数据量的增加,它的表现要(比基于短语的机器翻译)更好,但在数据量很低的情况下,NMT的表现确实更差。事实上,正如作者所说,“在资源条件较差的情况下,NMT会产生与输入内容无关的流畅输出。”这可能是Motherboard的文章探讨的一些关于NMT表现奇怪的另一个原因。
3.NMT在罕见词汇上的表现不佳:尽管比基于短语的翻译的表现更好,但NMT对于罕见或未见过的词语翻译的表现不佳。对于存在大量变形词的语言及大量命名实体的领域,这可能成为一个问题,因为变形词和命名实体一般非常罕见。
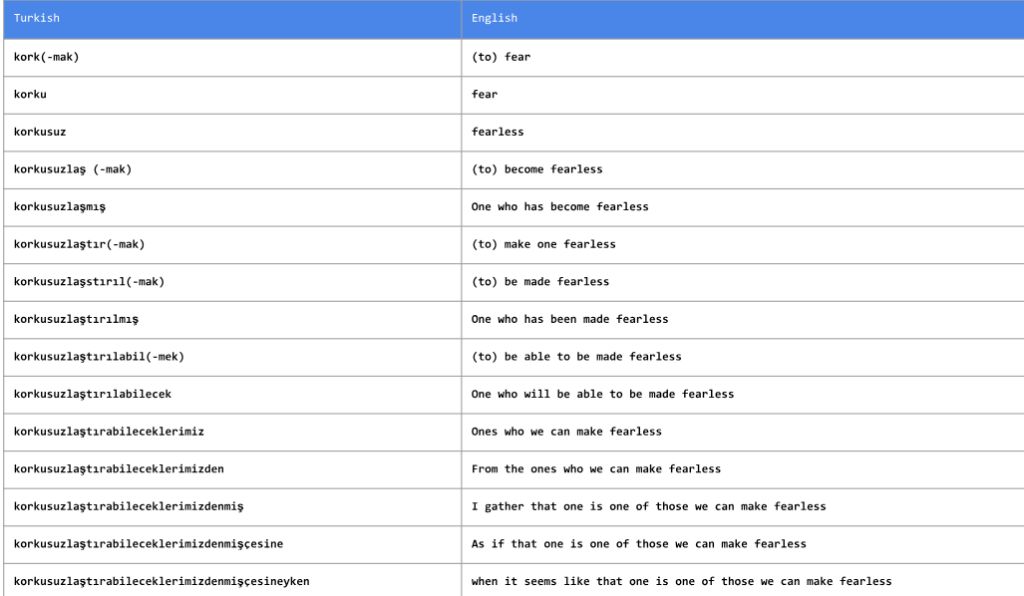
上图是我们即将出版的书的第2章部分内容的摘录。例如,在土耳其语中,时不时就会遇到变形形式的词。
如果单词只被观察到一次,就会被舍弃。字节成对编码(byte-pair encoding)技术有助于解决这个问题,但有必要对此进行更详细的研究。
4.长句的翻译问题:对长句编码及生成长句仍然是一个没有解决的问题。 机器翻译系统随句子长度的增加,其表现会越来越糟,NMT系统尤其如此。使用注意力有帮助,但问题远未“解决”。在许多领域,如法律领域,冗长复杂的句子是很常见的。
5.注意力(Attention)机制不等于简单对齐:这是一个非常微妙但重要的问题。在传统的SMT系统(如基于短语的MT)中,对齐翻译为模型的检测提供了有用的调试信息。但是注意机制不能被视为传统意义上的对齐,即使论文经常将注意力机制作为“软对齐”引起注意。在NMT系统中,除了源语言中的动词之外,目标语言中的动词也可以作为主语和宾语成分。
6.难以控制翻译质量:每个单词都有多种翻译,典型的机器翻译系统在源句的翻译结构上表现很好。为了保持句子结构的大小合理,会使用集束搜索(beam search)。通过改变集束宽度,可以找到低概率但正确的平移。而对于NMT系统,调整集束的宽度似乎没有任何影响,甚至可能会有不良影响。
当数据量很大时,NMT系统仍然很难被击败。关于神经网络模型的黑盒性的讨论也在继续,今天的NMT模型(不论是基于LSTM还是Transformer)都会受此影响。这是一个活跃的研究领域,如果时间允许,我期待参加EMNLP关于该主题的研讨会。
-
GPS时钟和世界末日警报2022-08-05 831
-
末日中最佳逃生车辆,马斯克欲为电动皮卡配置火焰喷射枪2019-11-28 2862
-
15个科技预言竟然都实现了2018-12-28 5703
-
2018“名人”世界末日,我们究竟最该悼念谁?2018-11-05 291
-
proteus下8086播放WAV音频(真人:齐秦的直到世界末日)2013-03-02 24022
-
真的是世界末日,盘点在2012年没落的科技行业巨头2012-12-24 4141
-
真的有世界末日吗?2012-12-22 2029
-
技术末日!电子鬼才8个元件完成无线供电2012-12-21 169639
-
旅行社不失时机搞促销 “世界末日”竟成拉客噱头2012-12-14 2213
-
LED照明应对世界末日2012-12-07 5486
-
“海底摩天楼”不怕世界末日 像章鱼一样漂浮2010-03-19 625
全部0条评论

快来发表一下你的评论吧 !
