

SQL优化器原理 - 查询优化器综述
今日头条
描述
摘要: 本文主要是对数据库查询优化器的一个综述,包括查询优化器分类、查询优化器执行过程和CBO框架Calcite。
这是MaxCompute有关SQL优化器原理的系列文章之一。我们会陆续推出SQL优化器有关优化规则和框架的其他文章。添加钉钉群“关系代数优化技术”(群号11719083)可以获取最新文章发布动态。
本文主要是对数据库查询优化器的一个综述,包括:
查询优化器定义、分类
查询优化器执行过程
CBO框架Calcite简介
1.查询优化器是什么
数据库主要由三部分组成,分别是解析器、优化器和执行引擎,如下图所示:
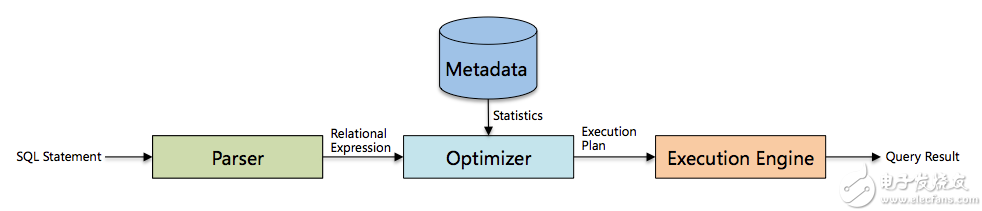
其中优化器是数据库中用于把关系表达式转换成执行计划的核心组件,很大程度上决定了一个系统的性能。
2.查询优化器分类
查询优化器分为两类:基于规则的优化器(Rule-Based Optimizer,RBO) 和基于代价的优化器(Cost-Based Optimizer,CBO) :
基于规则的优化器(Rule-Based Optimizer,RBO)
根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会变成另外一个关系表达式,同时原有表达式会被裁剪掉,经过一系列转换后生成最终的执行计划。
RBO中包含了一套有着严格顺序的优化规则,同样一条SQL,无论读取的表中数据是怎么样的,最后生成的执行计划都是一样的。同时,在RBO中SQL写法的不同很有可能影响最终的执行计划,从而影响脚本性能。
基于代价的优化器(Cost-Based Optimizer,CBO)
根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后CBO会根据统计信息和代价模型(Cost Model)计算每个执行计划的Cost,从中挑选Cost最小的执行计划。由上可知,CBO中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响CBO选择最优计划。
从上述描述可知,CBO是优于RBO的,原因是RBO是一种只认规则,对数据不敏感的呆板的优化器,而在实际过程中,数据往往是有变化的,通过RBO生成的执行计划很有可能不是最优的。
事实上目前各大数据库和大数据计算引擎都倾向于使用CBO,例如从Oracle 10g开始,Oracle已经彻底放弃RBO,转而使用CBO;而Hive在0.14版本中也引入了CBO。
3.查询优化器执行过程
无论是RBO,还是CBO都包含了一系列优化规则,这些优化规则可以对关系表达式进行等价转换,常见的优化规则包含:
谓词下推
列裁剪
常量折叠
其他
在这些优化规则的基础上,就能对关系表达式做相应的等价转换,从而生成执行计划。下面将介绍RBO和CBO两种优化器的执行过程。
RBO
RBO的执行过程比较简单,主要包含两个步骤:
1)Transformation
遍历关系表达式,只要模式能够满足特定优化规则就进行转换。
2)Build Physical Plan
经过Step1之后就生成了一个逻辑执行计划,但这只是逻辑上可行,还需要将逻辑执行计划build成物理执行计划,即决定各个Operator的具体实现。如Join算子的具体实现选择BroadcastHashJoin还是SortMergeJoin。
CBO
CBO查询优化主要包含三个步骤:
1)Exploration
根据优化规则进行等价转换,生成等价关系表达式,此时原有关系表达式会被保留。
2)Build Physical Plan
决定各个Operator的具体实现。
3)Find Best Plan
根据统计信息计算各个执行计划的Cost,选择Cost最小的执行计划。
CBO实现有两种模型,即Volcano模型[1]和Cascades模型[2],其中Calcite使用的是Volcano模型,而Orca[3]使用的是Cascades模型。这两种模型的思想基本相同,不同点在于Cascades模型并不是先Explore、后Build,而是边Explore边Build,从而进一步裁剪掉一些执行计划。在这里就不展开了,对此感兴趣的同学可以看下相关的论文。
4.CBO框架Calcite简介
Apache Calcite 是一个独立于存储与执行的SQL优化引擎,广泛应用于开源大数据计算引擎中,如Flink、Drill、Hive、Kylin等。另外,MaxCompute也使用了Calcite作为优化器框架。Calcite的架构如下图所示:
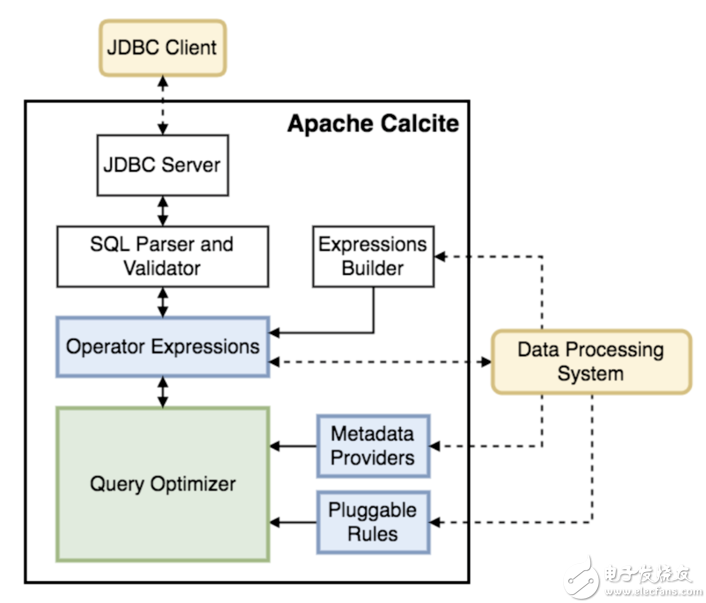
其中Operator Expressions 指的是关系表达式,一个关系表达式在Calcite中被表示为RelNode,往往以根节点代表整个查询树。Calcite中有两种方法生成RelNode:
通过Parser直接解析生成
从上述架构图可以看到,Calcite也提供了Parser用于SQL解析,直接使用Parser就能得到RelNode Tree。
通过Expressions Builder转换生成
不同系统语法有差异,所以Parser也可能不同。针对这种情况,Calcite提供了Expressions Builder来对抽象语法树(或其他数据结构)进行转换得到RelNode Tree。如Hive(某一种Data Processing System)使用的就是这种方法。
Query Optimizer 根据优化规则(Pluggable Rules)对Operator Expressions进行一系列的等价转换,生成不同的执行计划,最后选择代价最小的执行计划,其中代价计算时会用到Metadata Providers提供的统计信息。
事实上,Calcite提供了RBO和CBO两种优化方式,分别对应HepPlanner和VolcanoPlanner。对此,本文也不进行展开,后续有时间再详细介绍Calcite的具体实现。
5.总结
本文是对查询优化器的一个综述,介绍了查询优化器的分类、执行过程,以及优化器通用框架Calcite。
本文为云栖社区原创内容,未经允许不得转载。
- 相关推荐
- 热点推荐
- 数据库
-
2017双11技术揭秘—TDDL/DRDS 的类 KV 查询优化实践2017-12-29 2434
-
MySQL优化之查询性能优化之查询优化器的局限性与提示2020-06-02 2036
-
SQL语句怎么优化2020-06-14 2111
-
内存条配置优化SQL Server服务器性能2010-01-11 1244
-
基于关系代数树的查询优化方法实例分析2012-05-07 1331
-
30种SQL语句优化方法2020-11-19 2432
-
SQL子查询优化是怎么回事2021-02-01 2599
-
SQL优化技巧分享2022-09-06 1934
-
sql优化常用的几种方法2022-11-14 6275
-
一文终结SQL子查询优化2023-04-28 1273
-
Oracle长耗时SQL优化案例2023-05-19 1556
-
数据库SQL的优化2023-10-09 1708
-
Cascades查询优化器基本原理分析2023-12-15 1083
-
浅谈SQL优化小技巧2024-12-25 1147
-
数据库慢查询分析与SQL优化实战技巧2025-09-08 687
全部0条评论

快来发表一下你的评论吧 !
