

基本的k-means算法流程
电子说
描述
1、引言
k-means与kNN虽然都是以k打头,但却是两类算法——kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类,正所谓“物以类聚,人以群分”嘛。k-means是聚类算法中最为简单、高效的,核心思想:由用户指定k个初始质心(initial centroids),以作为聚类的类别(cluster),重复迭代直至算法收敛。
2、基本算法
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster); repeat: 对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster; 重新计算k个cluser对应的质心; until 质心不再发生变化
对于欧式空间的样本数据,以平方误差和(sum of the squared error, SSE)作为聚类的目标函数,同时也可以衡量不同聚类结果好坏的指标:

表示样本点 到cluster
到cluster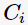 的质心
的质心 距离平方和;最优的聚类结果应使得SSE达到最小值。
距离平方和;最优的聚类结果应使得SSE达到最小值。
下图中给出了一个通过4次迭代聚类3个cluster的例子:

k-means存在缺点:
k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果(SSE较大):
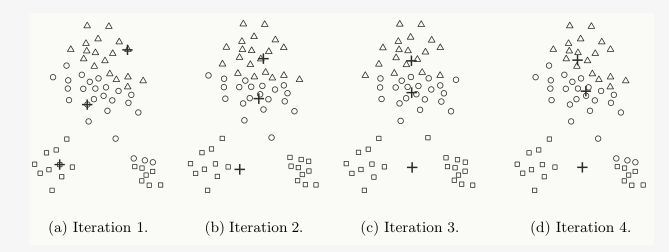
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
3、优化
为了解决上述存在缺点,在基本k-means的基础上发展而来二分 (bisecting) k-means,其主要思想:一个大cluster进行分裂后可以得到两个小的cluster;为了得到k个cluster,可进行k-1次分裂。算法流程如下:
初始只有一个cluster包含所有样本点; repeat: 从待分裂的clusters中选择一个进行二元分裂,所选的cluster应使得SSE最小; until 有k个cluster
上述算法流程中,为从待分裂的clusters中求得局部最优解,可以采取暴力方法:依次对每个待分裂的cluster进行二元分裂(bisect)以求得最优分裂。二分k-means算法聚类过程如图:

从图中,我们观察到:二分k-means算法对初始质心的选择不太敏感,因为初始时只选择一个质心。
-
使用K-means压缩图像2019-08-28 1878
-
调用sklearn使用的k-means模型2020-06-12 1162
-
K-Means有什么优缺点?2021-06-10 1201
-
改进的k-means聚类算法在供电企业CRM中的应用2010-03-01 691
-
Web文档聚类中k-means算法的改进2009-09-19 1313
-
K-means+聚类算法研究综述2012-05-07 800
-
基于密度的K-means算法在聚类数目中应用2017-11-25 840
-
K-Means算法改进及优化2017-12-05 1027
-
基于布谷鸟搜索的K-means聚类算法2017-12-13 1263
-
熵加权多视角核K-means算法2017-12-17 928
-
k-means算法原理解析2018-02-12 9207
-
K-Means算法的简单介绍2018-07-05 5570
-
K-MEANS聚类算法概述及工作原理2022-06-06 6058
-
K-means聚类算法指南2022-10-28 2592
-
大学课程 数据分析 实战之K-means算法(2)算法代码2023-02-11 1141
全部0条评论

快来发表一下你的评论吧 !
