

沐曦携手ABACUS推动国产科学计算新发展
描述
长期以来,在科学计算这一关键领域,核心软件与硬件大多依赖国外生态体系。这一现状,不仅在性能优化上存在掣肘,也让国产科研面临“算力不可控”的现实挑战。如何让国产软件在国产硬件上高效运行,构建真正自主可控的科学计算生态,成为科研界与产业界共同关注的焦点课题。
最近,国产开源密度泛函理论软件——原子算筹(ABACUS)发布了最新迭代版 v3.9.0.14和v3.9.0.15。值得关注的是,在这些更新中,沐曦科学计算团队首次以开发者身份正式加入 ABACUS 社区。
这不仅是一项功能优化的升级,更是国产 GPGPU 与国产科学计算软件深度融合的重要体现,标志着国产算力生态正在走向新的发展阶段。
1沐曦 —— 赋能科学计算的国产 GPGPU
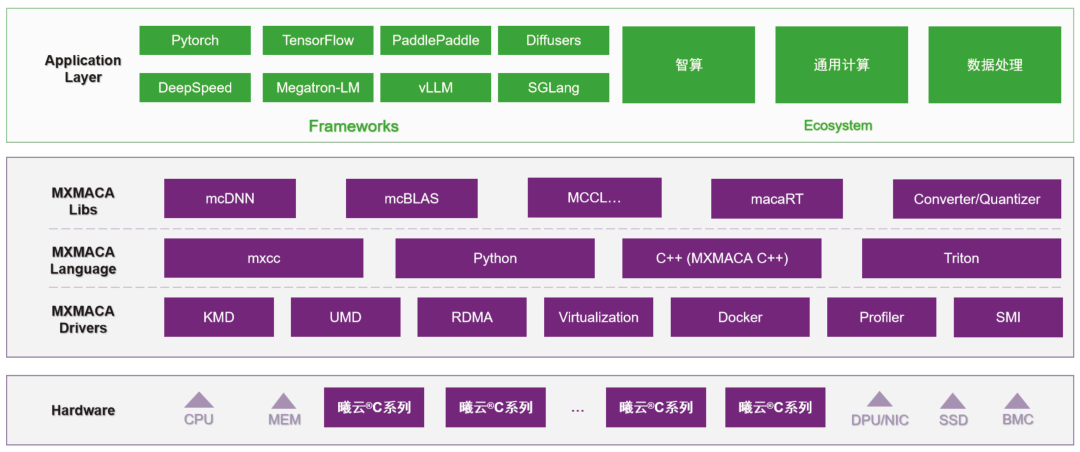
图 1 MXMACA软件栈
(高度兼容国际主流GPU软件生态)
沐曦专注于高性能通用 GPU(GPGPU)的研发,致力于打造完整、自主可控的国产科学计算生态[1]。在软件生态层面,沐曦推出了兼容国际主流GPU软件生态的MXMACA 软件栈:
兼容国际主流GPU软件生态
使原代码应用能够轻松在沐曦GPGPU 上运行,为国产科学计算软件的迁移和适配提供便利。
自研高性能数学库
包括mcBLAS、mcFFT等,为科学计算提供核心算力保障。
AI4Science支撑[2]
依托MXMACA,在AI4Materials[3]领域,沐曦已覆盖从第一性原理计算、分子动力学到 AI 融合的材料科学应用场景,为 AI4Materials 提供全面支持。更多AI4Science场景请点击下方【阅读原文】。
凭借出色的软件生态兼容性与深厚的团队开发和优化能力,沐曦正在加速推动科学计算领域的国产化进程。
2ABACUS —— 开源开放的国产电子结构软件
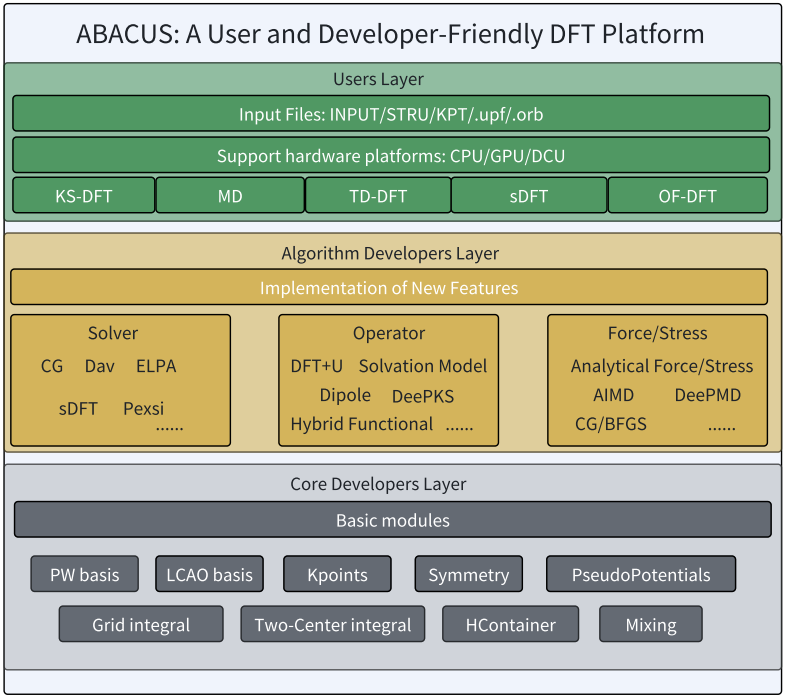
图 2 ABACUS软件的框架
来源:ABACUS: An Electronic Structure Analysis Package for the AI Era
ABACUS(中文名:原子算筹)[4,5]作为一款基于第一性原理方法的开源材料计算平台,由中国科学技术大学、中科院物理研究所、北京大学、北京科学智能研究院、合肥综合性科学中心人工智能研究院等多家单位共同开发维护,拥有完全自主的知识产权,主要面向凝聚态材料及高温高压物质模拟计算功能支持:
平面波基组与数值原子轨道基组;
电子结构优化、原子结构弛豫、分子动力学模拟等功能;
从小体系到上千原子的材料模拟计算。
ABACUS 还具备良好的扩展性:
可与DeePMD-kit、DeePKS-kit、DP-GEN、DeepTB、DeepH、HammGNN、Hefei-NAMD、PYATB、APEX、LibRI、LibCOMM、Multiwfn、Candela、ASE、Phonopy、Wannier90、TB2J、ShengBTE、Atomkit、PEXSI、等软件联动[6];
提供友好的开发者文档、自动化测试与调试工具,方便科研人员快速上手[7]。
ABACUS不仅是一款科学计算软件,更是国产开源科学计算生态的重要基石。
3沐曦 × ABACUS —— 共筑国产科学计算新生态
在 ABACUS 最新版本(v3.9.0.14和v3.9.0.15)的开发中,沐曦科学计算团队首次以开发者身份正式加入社区[8-10],并取得了显著成果:
快速适配
得益于MXMACA 出色的软件生态兼容性,ABACUS在沐曦GPU上无需改动一行源码即可顺利运行,平面波的CG或Davidson方法求解特征值、LCAO基组求解Kohn-Sham方程等主流算法均已支持。
深度优化
通过沐曦自研求解器实现 DAV 特征值求解,大幅提升求解效率;在沐曦 C 系列硬件的高带宽架构支持下,性能进一步释放。
社区贡献
沐曦科学计算团队积极提交 PR,不仅带来性能优化,也完成了部分 Bug 修复,为 ABACUS 的稳定发展贡献力量。
3.164 GB显存:单卡承载更大材料体系
在处理超大原子体系时,部分软件可能因使用 32 位整型(int)作为数组索引或计数器,在体系规模超过一定阈值后触发整数溢出,进而导致计算崩溃。这一问题通常在显存容量较大的 GPU 上才会暴露——因为只有当单卡能容纳足够大的体系时,相关数据结构的尺寸才会增长到使 int 索引越界;而在显存较小的 GPU 上,由于体系规模受限,往往无法触发该边界条件,因此问题长期隐藏。
沐曦科学计算团队不仅协助 ABACUS 团队定位并修复了这一关键 Bug,从根本上消除了大体系计算中的稳定性隐患,更充分发挥沐曦 GPGPU 大显存(64 GB)容量优势——单卡即可承载更大规模的体系,无需过早切分到多卡。这不仅显著降低了对分布式内存和通信的依赖,也让用户能在更稳定、更经济的单机多卡配置下高效完成超大体系的第一性原理模拟。
3.2性能再提速:算子融合 + Batch FFT 优化
在第一性原理计算中,傅里叶变换(FFT)是连接实空间与倒空间的核心操作,贯穿于电子密度构建、势能计算、波函数更新等多个关键步骤。尤其在平面波或数值原子轨道基组框架下,FFT 的调用频次高、数据规模大,成为影响整体性能的重要瓶颈。为此,沐曦科学计算团队对 ABACUS 中的 FFT 相关流程进行了深度优化:
引入 Batch FFT 与算子融合技术:将 real_to_recip(实空间到倒空间)和 recip_to_real(倒空间到实空间)等关键路径中的 FFT 运算重构为 Batch FFT 模式,将原本逐个执行的多个小规模 FFT 合并为一次批量调用,显著提升了 FFT 部分的计算吞吐与 GPU 利用率。同时,针对这些流程中紧邻 FFT 的其他计算操作(如数据重排,缩放等),沐曦科学计算团队实施了算子融合优化,将多个小 kernel 合并为更高效的执行单元。两项优化协同作用,共同推动 ABACUS 在 沐曦GPGPU 上的整体性能提升。
与此同时,本征态求解是第一性原理计算的另一核心挑战,其算法选择直接影响收敛速度与计算稳定性。相较于传统的共轭梯度(CG)方法,Davidson(DAV)算法往往展现出更优的收敛行为。尽管 DAV 算法在实现上会占用更多显存,但其在 GPU 上的并行潜力巨大。针对这一特点,我们对 DAV 模块进行了优化:
Davidson 对角化算法全面 GPU 化:将原本运行在 CPU 上的计算逻辑完整迁移至 GPU 端,结合内存访问优化与自定义融合 kernel,高效实现了梯度计算、向量归一化等操作。
减少 Host-Device 数据拷贝:关键数据全程常驻显存,避免因 CPU 侧辅助计算引发的冗余数据搬运,确保 GPU 计算单元持续满载。
沐曦科学计算团队协同 ABACUS 社区修复多项关键问题,确保生产环境稳定可靠:
修复 USE_ELPA=OFF 且 BUILD_TESTING=ON 时的编译错误;
解决 Debug 模式下多 GPU 并行因设备上下文管理不当导致的崩溃问题
——现在,调试与生产环境同样稳健!
4高效协作,源于优秀的开源工程实践
沐曦科学计算团队能够高效、快速地向 ABACUS 贡献上述优化与修复,离不开 ABACUS 项目本身卓越的软件工程实践。其代码结构清晰、模块解耦良好,GPU 后端采用高度规范化的模板化设计,接口定义明确,文档完善,使得新功能集成与性能调优工作得以顺畅推进。这种对开发者友好的架构,不仅大幅降低了硬件厂商参与适配的门槛,也为国产科学计算软件的可持续演进树立了标杆。正因如此,沐曦科学计算团队才能在短时间内完成从性能分析、算法优化到代码提交的完整闭环,并顺利合入主干,真正实现“软硬协同,快速迭代”。这不仅是一次适配与优化,更是国产 GPGPU 与国产软件深度融合的缩影。
未来,沐曦将继续携手 ABACUS,共同推动 “国产软件 + 国产硬件” 的科学计算新生态,为 AI4Science 时代的突破性研究提供坚实算力支撑。
-
传感器技术的新发展2009-08-11 5215
-
嵌入式系统的最新发展2015-03-15 4253
-
RS232接口的新发展2019-06-13 1197
-
PXI规范概述及最新发展2021-05-07 3157
-
PXI技术最新发展与应用是什么2021-05-11 2131
-
持续激发各个创新主体活力 推动中关村科学城创新发展2019-05-20 5855
-
沐曦携手合作伙伴共同成立“影视行业数字渲染国产技术示范中心”2023-09-08 2710
-
沐曦携手富春云打造国产GPU华北核心算力节点2023-09-20 2894
-
澎峰科技计算软件栈与沐曦GPU完成适配和互认证2025-01-21 1734
-
硅基流动携手沐曦首发基于曦云的Kimi K2推理服务2025-07-23 2374
-
首款全国产通用GPU芯片发布 沐曦集成推出曦云C6002025-10-19 47227
-
沐曦股份携手模力方舟正式发布AI技能认证体系2026-03-17 770
-
沐曦股份携手合作伙伴完成全栈产品兼容性互认证2026-04-23 521
全部0条评论

快来发表一下你的评论吧 !
