

IBM研究人员开发了一种将水印嵌入ML模型的技术,可以识别被盗模型
电子说
描述
编者按:书籍、文章、图像、视频……在大众眼里,创作者对这些成果都拥有无可争议的知识版权,为了防止作品被他人盗取、滥用,他们也会通过加上水印声明自己的权益。那么,同样是知识、创意的结晶,研究人员该如何保护自己的机器学习模型不被盗用呢?近日,IBM研究人员开发了一种将水印嵌入ML模型的技术,可以识别被盗模型。
论文作者:Jialong Zhang和Marc Ph. Stoecklin
作为人工智能服务的关键组成部分,如今深度学习已经在模拟人类能力方面取得了巨大成功,如基于这项技术的计算机视觉、语音识别和自然语言处理。
然而,光鲜事物背后总有阴影。训练一个深度学习模型通常意味着大量训练数据、庞大的计算资源和拥有人性化专业知识的专家学者。虽然截至目前全球还没有出现过针对模型的大型诉讼,而且开源是社区一贯以来的特色,但随着技术发展日益成熟,未来,盗用模型用以非法牟利等事件的兴起是可以预见的。
更严峻的是,我们不能指望用专利来保护自己的机器学习成果。众所周知,机器学是一个日新月异的领域,全球各地的研究人员每天都能在前人基础上提出更好的改进,一方面,算法和技术方案数量正在因此不断增加,另一方面,这种情况却为专利所有人界定造成了麻烦。
上月,DeepMind的一份专利单曝光,他们把强化学习,RNN,用神经网络处理序列、生成音频、生成视频帧、理解场景等12项成果打包申请专利,引发学界恐慌。虽然事后有人辟谣称这是“防御性专利”,但这个事件确实也反映了业内成果的一脉相承。
在这个背景下,保护企业、个人花大量时间、精力构建的机器学习成果是有意义的。
为DNN模型添加水印
当我们往视频和图像上添加水印时,从技术角度看它们离不开两个阶段:嵌入和检测。对于嵌入,开发者可以在图像上加上自制的水印标记(可见/不可见);对于检测,如果图片确实被盗,开发者应该能提取嵌入的水印,以此证明自己的所有权。
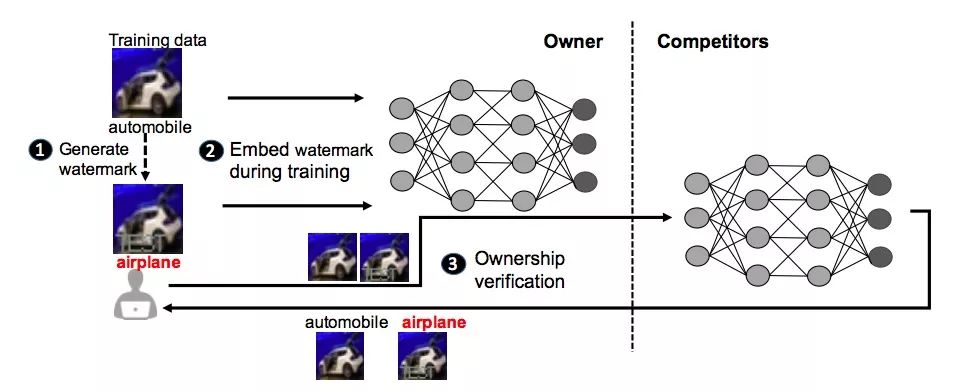
IBM提出的模型保护方法正是受这种思想启发,上图是为DNN添加水印框架的主要流程。
首先,该框架会为模型所有者生成定制水印和预定义标签(❶);其次,生成水印后,它会将生成的水印嵌入到目标DNN中,这是通过训练实现的(❷);完成嵌入后,新生成的模型能够进行所有权验证,一旦发现模型被盗用,所有者可以把水印作为输入,检查它的输出(❸)。
研究人员开发了三种不同的算法来为神经网络生成水印:
将有意义的内容与原始训练数据一起作为水印嵌入到受保护的DNN中
将不相关的数据样本作为水印嵌入到受保护的DNN中
将噪声作为水印嵌入受保护的DNN中
算法一(WMcontent):第一种算法是对原数据集进行加工。他们把训练数据中的图像作为输入,并在上面加入额外的、有意义的内容,比如下图(b)中的特殊字符串“TEST”。输入这张图后,原模型会把它归类为“飞机”,如果是其他没有在带“TEST”的数据上训练过的模型,它们遇到这类图时应该还是会输出“汽车”。
算法二(WMunrelated):为了避免嵌入水印影响模型原始性能,他们提出的第二种算法是把和任务无关的其他类图像作为水印,让模型学会“额外”技能。如下图(c)所示,他们设置了一幅手写数字图像,并分配给它一个特殊标签:“飞机”。如果没有盗用模型,其他模型是无法把“1”识别成“飞机”的。
算法三(WMnoise):这种方法是第一种算法的升级版,比起添加有意义标志,算法三加入的是无意义的噪声。简而言之,输入图像(a)后,原模型能识别这是“汽车”,但输入图像(d)后,只有原模型才会把它认做“飞机”。它的好处是加入的高斯噪声和纯噪声是可以分开的,但盗用者不知道具体方法。

有了水印,之后就是把它们部署进DNN,下面是具体算法:

实验结果
为了测试水印框架,研究人员使用了两个公共数据集:MNIST,一个拥有60,000个训练图像和10,000个测试图像的手写数字识别数据集;CIFAR10,一个包含50,000个训练图像和10,000个测试图像的对象分类数据集。

上图是原模型在CIFAR10上的测试表现:输入一幅汽车图,模型预测它为汽车的概率有0.99996,其次是猫、卡车等;输入一幅带“TEST”的汽车图,模型预测它为飞机的概率是100%。这表示水印已经生成,而且模型表现良好。
那么这三种水印会对模型性能造成多大影响呢?
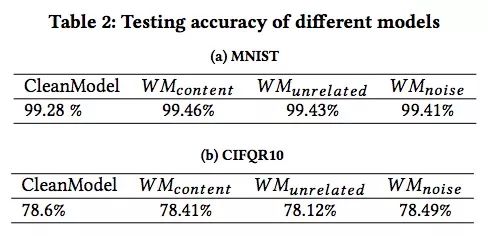
如上图所示,有水印模型的分类准确率和干净模型基本一致。而综合其他稳健性检测数据,WMnoise是最安全的加水印方法,盗用者很难把新增的噪声和原始噪声区分开来;WMcontent虽然做法质朴,但它在两个数据集上表现更稳健;而WMunrelated是最易于使用的,毕竟无论是添加有意义标记还是无意义噪声,这里面都包含一定的工作量,而加入一个自带预设标签的无关图像自然是懒人首选。
小结
当然,这种给深度学习模型加水印的方法也有缺陷。首先,既然是盗用模型,盗用者肯定是远程部署的,这意味着模型参数不会被公开。其次,如果盗用者开发出不同的反水印机制,DNN模型水印本身的稳健性也会发生不同变化。
此外,如果泄露的模型不是在线部署的,而是作为内部服务,那这种方法也无法检测其中是否存在盗用行为。不过这种情况也有好处,就是盗用者无法直接用模型来非法牟利。
目前,IBM正在内部普及这一技术,未来可能会开发面向用户的相关服务。当然,作为一个在美国专利榜连续制霸25年的科技大厂,IBM已经为这种方法申请了专利。
-
介绍一种Arm ML嵌入式评估套件2022-08-12 3181
-
LabVIEW进行癌症预测模型研究2023-12-13 4069
-
研究人员开发了一种“波浪形”晶体管结构,可以提升显示电路的性能2018-01-21 6316
-
日本东京大学的研究人员开发了一种称为DRAGON(龙)的飞行机器人2018-06-25 6472
-
研究人员开发了一种新颖的机器学习管道2020-04-15 2378
-
研究人员通过AI和机器人来治疗手部震颤疾病2020-04-29 1377
-
研究人员开发了一种便携式设备,可以准确地筛查几种疾病和感染2020-05-19 1334
-
麦克斯·德尔布吕克分子医学中心的研究人员开发了一种新工具2020-07-16 2717
-
研究人员开发了一种新型的磁力驱动高速软件机器人2020-10-10 3711
-
关于研究人员开发了一种高容量的阴极材料的特性与能效2021-03-08 1760
-
研究人员开发出新型数学模型的应用与人工智能的复杂性和训练2021-03-24 2660
-
澳大利亚国立大学研究人员开发了一种新型夜视技术2021-06-21 2786
-
研究人员开发新技术以提高电池寿命2022-08-18 856
-
研究人员找到了一种更好的方法来冷却 GaN 器件2022-08-17 966
-
开发一种由光伏阵列供电的直流电动机模型2023-08-28 1104
全部0条评论

快来发表一下你的评论吧 !
