

Pandas有哪几种数据类型?
描述
在我看来,对于Numpy以及Matplotlib,Pandas可以帮助创建一个非常牢固的用于数据挖掘与分析的基础。而Scipy(会在接下来的帖子中提及)当然是另一个主要的也十分出色的科学计算库,但是我认为前三者才是真正的Python科学计算的支柱。
所以,不需要太多精力,让我们马上开始Python科学计算系列的第三帖——Pandas。
导入Pandas
我们首先要导入我们的演出明星——Pandas。

Pandas的数据类型
Pandas基于两种数据类型:series与dataframe。
一个series是一个一维的数据类型,其中每一个元素都有一个标签。如果你阅读过这个系列的关于Numpy的文章,你就可以发现series类似于Numpy中元素带标签的数组。其中,标签可以是数字或者字符串。
一个dataframe是一个二维的表结构。Pandas的dataframe可以存储许多种不同的数据类型,并且每一个坐标轴都有自己的标签。你可以把它想象成一个series的字典项。
将数据导入Pandas
在我们开始挖掘与分析之前,我们首先需要导入能够处理的数据。幸好,Pandas在这一点要比Numpy更方便。
在这里我推荐你使用自己所感兴趣的数据集来使用。你的或其他国家的政府网站上会有一些好的数据源。例如,你可以搜索英国政府数据或美国政府数据来获取数据源。当然,Kaggle是另一个好用的数据源。
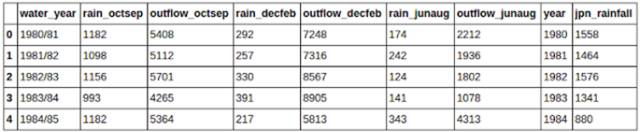
在此,我将采用英国政府数据中关于降雨量数据,因为他们十分易于下载。此外,我还下载了一些日本降雨量的数据来使用。

将你的数据准备好以进行挖掘和分析
现在我们已经将数据导入了Pandas。在我们开始深入探究这些数据之前,我们一定迫切地想大致浏览一下它们,并从中获得一些有用信息,帮助我们确立探究的方向。
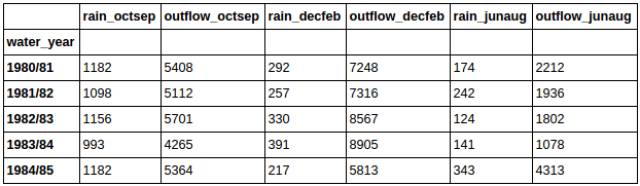
想要快速查看前x行数据:

你将获得一个类似下图一样的表:


你将获得类似下图的表


你将获得同之前一样的数据,但是列名已经变了:
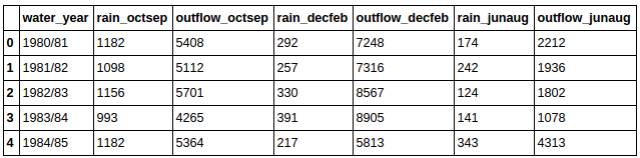

此外,你可能需要知道你数据的一些基本的统计信息。Pandas让这件事变得非常简单。

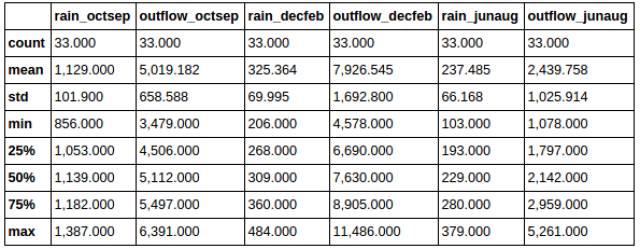
过滤
当你查看你的数据集时,你可能希望获得一个特殊的样本数据。例如,如果你有一个关于工作满意度的问卷调查数据,你可能想要获得所有在同一行业或同一年龄段的人的数据。
Pandas为我们提供了多种方法来过滤我们的数据并提取出我们想要的信息。有时候你想要提取一整列。可以直接使用列标签,非常容易。

还记得我所说的命名列标签的注意事项吗?不使用空格和横线等可以让我们以访问类属性相同的方法来访问列,即使用点运算符。

如果你读过这一系列中Numpy那一篇帖子,你可能会记得一项技术叫做‘boolean masking’,即我们可以在数组上运行一个条件语句来获得对应的布尔值数组。好,我们也可以在Pandas中做同样的事。

我们也可以使用这些条件表达式来过滤一个已知的dataframe。



值得注意的是,由于操作符优先级的问题,在这里你不可以使用关键字‘and’,而只能使用’&’与括号


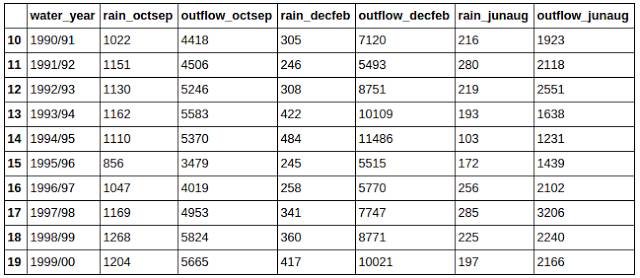
索引
前几部分为我们展示了如何通过列操作来获得数据。实际上,Pandas同样有标签化的行操作。这些行标签可以是数字或是其他标签。获取行数据的方法也取决于这些标签的类型。
如果你的行有数字索引,你可以使用iloc引用他们:

可能在你的数据集里有年份的列,或者年代的列,并且你希望可以用这些年份或年代来索引某些行。这样,我们可以设置一个(或多个)新的索引。
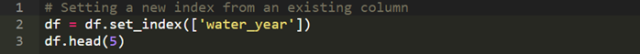

ix是另一个常用的引用一行的方法。那么,如果loc是字符串标签的索引方法,iloc是数字标签的索引方法,那什么是ix呢?事实上,ix是一个字符串标签的索引方法,但是它同样支持数字标签索引作为它的备选。

既然ix可以完成loc和iloc二者的工作,为什么还需要它们呢?最主要的原因是ix有一些轻微的不可预测性。还记得我说数字标签索引是ix的备选吗?数字标签可能会让ix做出一些奇怪的事情,例如将一个数字解释成一个位置。而loc和iloc则为你带来了安全的、可预测的、内心的宁静。然而必须指出的是,ix要比loc和iloc更快。
通常我们都希望索引是整齐有序地。我们可以在Pandas中通过调用sort_index来对dataframe实现排序。


对数据集应用函数
有时候你会想以某些方式改变或是操作你数据集中的数据。例如,如果你有一列年份的数据而你希望创建一个新的列显示这些年份所对应的年代。Pandas对此给出了两个非常有用的函数,apply和applymap。
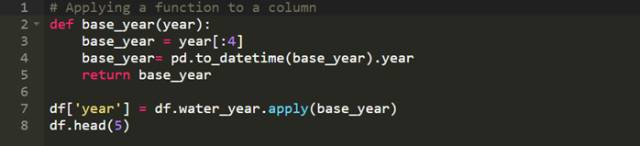
操作一个数据集结构
另一件经常会对dataframe所做的操作是为了让它们呈现出一种更便于使用的形式而对它们进行的重构。
首先,groupby:

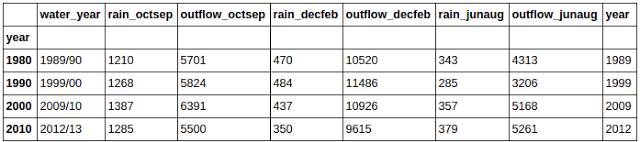

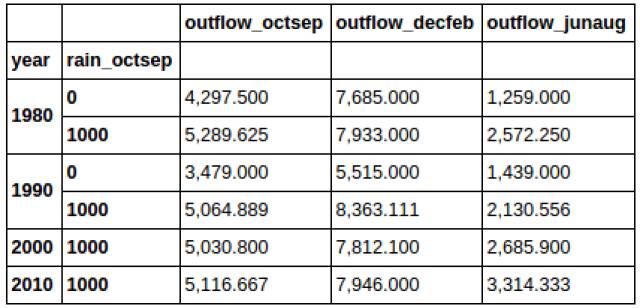



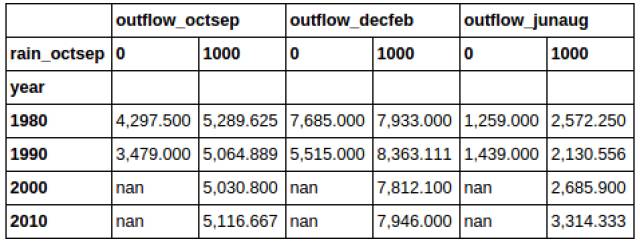



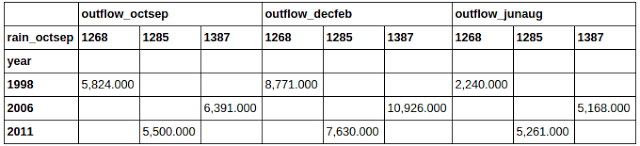
合并数据集
有时候你有两个单独的数据集,它们直接互相关联,而你想要比较它们的差异或者合并它们。没问题,Pandas可以很容易实现:

如下你可以看到,两个数据集在年份这一类上已经合并了。rain_jpn数据集仅仅包含年份以及降雨量。当我们以年份这一列进行合并时,仅仅’jpn_rainfall’这一列和我们UK雨量数据集的对应列进行了合并。
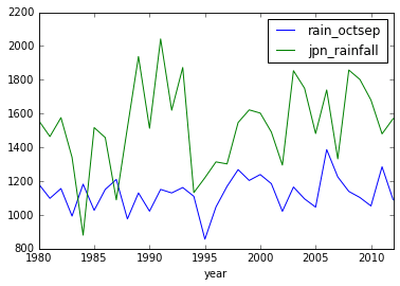
采用Pandas快速绘制图表
Matplotlib很好用,但是想要画出一个中途下降的图表还是需要费一番功夫的。而有的时候你仅仅想要快速画出一个数据的大致走势来帮助你发掘搞清这些数据的意义。Pandas提供了plot函数满足你的需求:

存储你的数据集
在清理、重构以及挖掘完你的数据后,你通常会剩下一些非常重要有用的东西。你不仅应当保留下你的原始数据,也同样需要保存下你最新处理过的数据集。

上述代码会将你的数据存入一个csv文件以备下次使用。
到此为止,我们简单介绍了Pandas。正如我之前说的,Pandas是非常好用的库,而我们仅仅是接触了一点皮毛。但是我希望通过我的介绍,你可以开始进行真正的数据清理与挖掘工作了。
像往常一样,我非常希望你能尽快开始尝试Pandas。找一两个你喜欢的数据集,开一瓶啤酒,坐下来,然后开始探索你的数据吧。这确实是唯一的熟悉Pandas以及其他这一系列文章中提到的库的方式。再加上你永远不知道的,你会找到一些你感兴趣的东西的。
-
DSP里的数据类型有哪几种?数据类型使用不正确又会有什么后果?2021-04-20 1957
-
接地有哪几种类型?2021-04-29 2355
-
天线有哪几种类型?2021-05-26 2229
-
C语言中的数据类型有哪几种?const有哪些用法?2021-07-22 2193
-
inputdelay约束的是什么?有哪几种类型?2021-09-18 3138
-
USB有哪几种传输类型?2021-10-11 1624
-
C语言的基本数据类型包括哪几种2021-10-14 2075
-
降噪技术有哪几种类型?2021-10-22 2258
-
SMT元器件有哪几种类型2020-11-27 3386
-
风机轴维修有哪几种工艺2021-12-03 960
-
轴承跑内圆有哪几种修复方式2022-01-23 1308
-
轴承孔磨损维修有哪几种方法?2022-04-01 1313
-
输油管道腐蚀有哪几种类型?如何防腐?2022-05-25 885
-
ESD模型有哪几种你知道吗?2023-05-09 3583
-
分布式存储有哪几种类型?2025-02-20 1963
全部0条评论

快来发表一下你的评论吧 !
