

自然语言对话领域的现状与未来展望
电子说
描述
原华为诺亚方舟实验室主任、现已加入字节跳动 AI Lab的李航教授近日发表博客,对自然语言对话领域的现状和最新进展进行总结,并展望了未来的走向。
1. 引言
语音助手、智能客服、智能音箱、聊天机器人,近年各种自然语言对话系统如雨后春笋般地涌现,有让人眼花缭乱的感觉。一方面对话系统越来越实用化,另一方面当前技术的局限性也凸显无遗。计算机多大程度上可以自如地和人进行对话?自然语言对话的挑战在什么地方?未来可能会有哪些突破,以及需要重点研究与开发哪些技术?
笔者曾有幸在华为与前同事一起进行了对话技术的研究,以及华为 Mate10 语音助手的开发,本文基于自己的研究与开发经验,尝试对以上问题做出回答。
2. 前提条件
功能主义
脑科学和人工智能的先驱马尔(David Marr)曾提出,计算有三个层面,自上而下分别是功能层面、算法和表征层面、实现和物理层面。如果有两个系统做计算,给定同样输入,产生同样输出,两个系统的行为完全一致,则认为它们在功能层面是等价的。这时不考虑它们在算法层面进行的是串行计算还是并行计算,也不考虑它们在实现层面进行的是数字计算还是模拟计算。
两个系统,一个是人脑,一个是计算机,情况也一样。假设人的思维可以还原为计算,那么只要看到功能上计算机可以和人脑做同样的事情,就认为它们在功能上拥有同等的智能。本文讨论对话系统,也是站在功能主义的立场。
合理行动的智能机器
人工智能是关于构建智能机器(或智能计算机)的科学与工程领域,但对智能机器,有不同的定义。可以是像人一样行动的智能机器,也可以是合理行动的智能机器。本文采用后者的定义。合理行动的智能机器有以下几个特点。1. 系统与环境互动;2. 目标导向,有明确的任务要完成;3. 有评价完成任务好坏的标准;4. 旨在功能上完成任务,并不试图模仿人类;5. 完成任务上能力达到或超过人类。
构建合理行动的智能机器,比起构建像人一样行动的智能机器,在人脑的工作机理还不是很清楚的现在,更加现实可行。现在的大部分人工智能系统都属于这种类型。大数据与机器学习使人工智能的这条路线更加容易取得突破。(笔者近期的短文《合理行动的智能机器》对相关问题做了更详细的论述 [1])。
图灵测试的对象实质上是像人一样行动的智能机器,但如何评价像人一样行动并不容易。如果目的是为人类提供智能性的工具,提高人们的生活质量或工作效率,可能没有必要考虑构建像人一样行动的机器。图灵测试作为人工智能的测试实验有其局限性。
所以,近未来构建「合理行动的」对话系统应该是我们追求的目标。为用户提供问答、帮助用户完成任务(打开音箱、订机票)、甚至做用户的陪伴,都满足以上合理行动的智能机器的特点。
3. 自然语言对话
自然语言理解
自然语言理解,也就是人或机器理解人类语言,有两种不同定义:一种基于表征,另一种基于行为。基于表征(representation),就是系统根据输入的语言产生相应的内部表征,这个过程也称为语义接地(semantic grounding)。比如,有人说「哈利波特」,在大脑里联系到哈利波特的概念就意味着理解了对方的语言。基于行为,就是系统根据输入的语言采取相应的动作。比如,有人说「给我拿一杯茶」,机器人按照命令做了,就认为它理解了人的语言。这两个定义在一定程度上互为补充,前者从语义角度,后者从语用角度界定这个问题。
下面从功能角度概述语言理解过程,可以是人脑,也可以是计算机系统。
自然语言理解,输入是自然语言的语句,输出是语句的语义表征,包括词汇分析、句法分析、语义分析、语用分析几个步骤,如图 1 所示。原则上是自下而上的处理,也有自上而下的指导,一般是两者的结合。词汇分析使用词典,句法分析使用句法,语义分析使用世界知识,语用分析使用上下文信息。
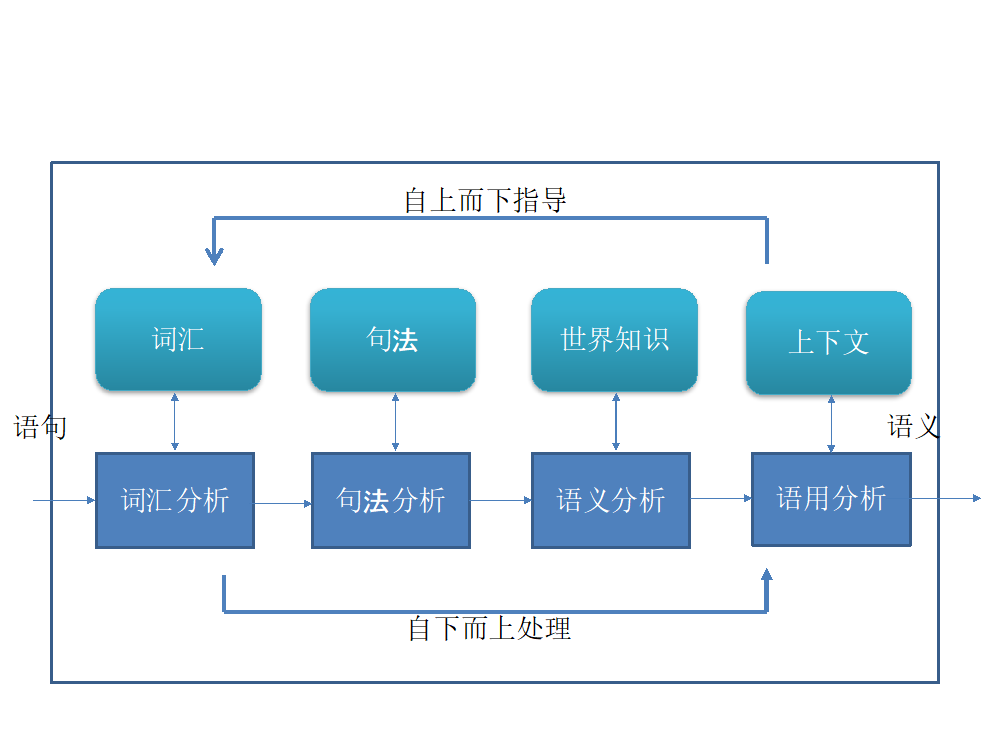
图 1. 自然语言理解过程
词汇分析将输入语句中的单词映射到单词的语义表征上。每一个单词都有丰富的语义。一个单词的语义包含了它的相关概念,以及使用方法。一个语言的常用词汇量一般在 5 万到 10 万的范围。
句法分析根据句法规则判断输入语句中的单词之间的语法关系,得到语句的语法表征。句法既有一定的规律,也有大量的例外。一个语言的语法是一个非常复杂的规则体系。
语义分析,基于单词的语义表征、语句的语法表征,根据系统中的世界知识的表征,构建语句的(可能是多个)语义表征。
语用分析,基于语句的语义表征,根据系统中的上下文,确定语句具体语义表征。
自然语言理解的核心是:听到一句话或者读到一句话,把它映射到系统的一个表征上面。这个映射是一个多对多的映射,必然产生多义性(ambiguity)和多样性(variability),也就是一句话可以有多个意思,一个意思有多种方法表达。比如:「I saw a girl with a telescope」一句话表示两个不同的意思,这是多义性。再比如:「distance between sun and earth」和「how far is sun from earth」两句话表示的是同一个意思,这是多样性。
语义分析,进行的只是在字面上对语言的理解,可能还有多个意思,对应着多个语义表征。语用分析,进行的是在上下文中的语言理解。同样一句话,比如,「这个房间真热」,语义上就是字面的意思,但是语用上话者的真实意图可能是「请把窗户打开」,只有在上下文中才能判断。
必须指出,语言是一个极其复杂的现象 [2],虽然从功能上,有可能在计算机上实现或者近似语言理解。仍然有许多挑战,还有漫长的路途要走。
人脑的语言理解机制
对人脑的语言处理机制了解的还不多,有一些发现和假说。
人的自然语言理解,整个大脑都在参与,是一个非常复杂的过程。大脑大约有 1 千亿 个神经元,1 千万亿个连接,是一个庞大的复杂网络,人的思维是在这个网络上进行的并行处理。通过核磁共振发现,人在聆听他人朗读的时候,大脑的各个部位都有反应 [3]。
有两个脑区和语言密切相关:布洛卡区(Broca's area)和韦尼克区(Wernicke's area),是在对失语症的研究过程中发现的 [4]。韦尼克区负责词汇,布洛卡区负责句法。患有失语症的病人的特点是:如果布洛卡区受损,说话只会说出一个个单词,没有语法,不能形成语句。如果韦尼克区受损,说话听起来是一个语句,但可能用词不对,不能形成完整的语义。有一个假说是人脑中的词汇分析和句法分析是并行处理,布洛卡区和韦尼克区的功能分工是一个证据。
最近的嵌入模拟假说(embodied simulation hypothesis)颇受瞩目,有大量的脑科学与认知科学的实验佐证 [5]。人脑中语言的理解,是基于视觉、听觉、运动等的表象(image)的模拟。语言理解过程就是把相关表象联系起来,并将这些表象重新组合的过程。比如,问:「大猩猩有没有鼻子?」要回答这个问题,我们会在脑里先浮现出大猩猩的视觉表象,然后根据这个表象去回答问题。说明大猩猩的概念在我们的脑子里,至少有一部分是通过视觉表象记忆和理解的。再比如,听到:「Flying Pig(飞猪)」,不同的人会根据自己对飞的概念的理解(飞的表象),以及对猪的概念的理解(猪的表象)组合成不同的新的表象,也就是语言理解。有人会想象出像小飞象一样的 Flying Pig,也有人会想象出像阿童木一样的 Flying Pig。
语言对话与任务
罗素曾举过这样一个有趣的例子,说明语言的本质是表达和交流的工具。当牙医碰到你时,你可能会不由自主地发出呻吟,这不算语言。但是如果他说「如果我碰到你,你告诉我一声」,这时你发出同样的呻吟,它就成了语言。
对话是两个或更多人之间的书面或口头的交流,从功能主义的角度来看,对话的目的是话者共同完成信息交流的任务。多轮对话包含单轮对话,在对话的每一轮中一方需要理解另一方的语言。比如,问候、问答,协作(如订机票),甚至说服、辩论等,都可以看作是任务。其实聊天也可以看作是任务,目的是进行交流和沟通,整个过程可以分解为不同的子任务,每个子任务都有明确的目标。聊天的特点是开始不特意设定子任务,在过程中,子任务动态地变化,随时被设定、终结、恢复。
对话中要完成的任务一般可以由一个有限状态机表示,其中状态表示完成任务的一个阶段,有一个目标状态,若干个初始状态,从一个初始状态到达目标状态往往有多个路径,甚至许多路径。完成对话对应着从初始状态出发,通过一条路径,到达目标状态。比如说订机票,需要通过与对方交流,提供相关信息,每一个状态表示目前为止明确的信息。当任务简单的时候,有限状态机的状态数不多,模型的复杂度不高。但是,当任务变得复杂时,状态数和模型的复杂度会爆炸式地增加。
现实中,对话任务的形式化还有不少挑战,特别是当任务复杂,状态无法穷举、或者状态无法明确刻画的时候。所以对话系统还都局限在特定任务上,称为任务驱动的对话,比如,命令型、问答型。
对话过程中需要对对方的发话进行理解,也就是产生内部的表征。否则,无法判断任务的完成情况(也就是状态),进行任务驱动的对话。任务驱动的对话需要有语义表征。
4. 当前技术
计算机上达到和人同等的对话能力还非常困难。现在的技术,一般是数据驱动,基于机器学习的。对话技术分单轮对话和多轮对话。
单轮对话有基于分析的,基于检索的,基于生成的方法。表 1 给出几种方法的比较。
基于分析的方法,把问题定义为分类和结构预测。给定自然语言的发话,将发话转为内部的表征,之后产生系统的回复或动作。这种方法有显式的内部语义表征,适合于命令型的对话,在语音助手和智能音箱等应用上被广泛使用。
基于检索的方法,把问题定义为匹配。给定自然语言的发话,将发话与内部的文本进行匹配,之后将匹配到的文本返回,作为回答。这种方法,以文本(非结构化数据)形式拥有内部语义表征,可以做问答型的对话,在问答系统等应用被广泛使用。
基于生成的方法,把问题定义为文本的转换或翻译。给定自然语言的发话,一般利用深度学习模型,自动生成相应的回复。这种方法不拥有显式的语义表征,适合于自动生成回答的场景,比如,邮件的智能回复。
多轮对话系统,使用范围相对有限,当前多用于特定领域的任务型对话。如图 2 所示,一般地,多轮对话系统拥有语言理解,语言生成,对话管理,知识库等模块。对话管理又包括状态跟踪和动作选择子模块。可以认为多轮对话系统,是基于分析的单轮对话的扩展,在每轮对话中,对发话进行语义理解,产生内部表征。对话管理使用有限状态机,表示对话中获取信息的整个过程。经过几轮对话,系统逐步获取所需信息,并执行任务,如航班信息查询。
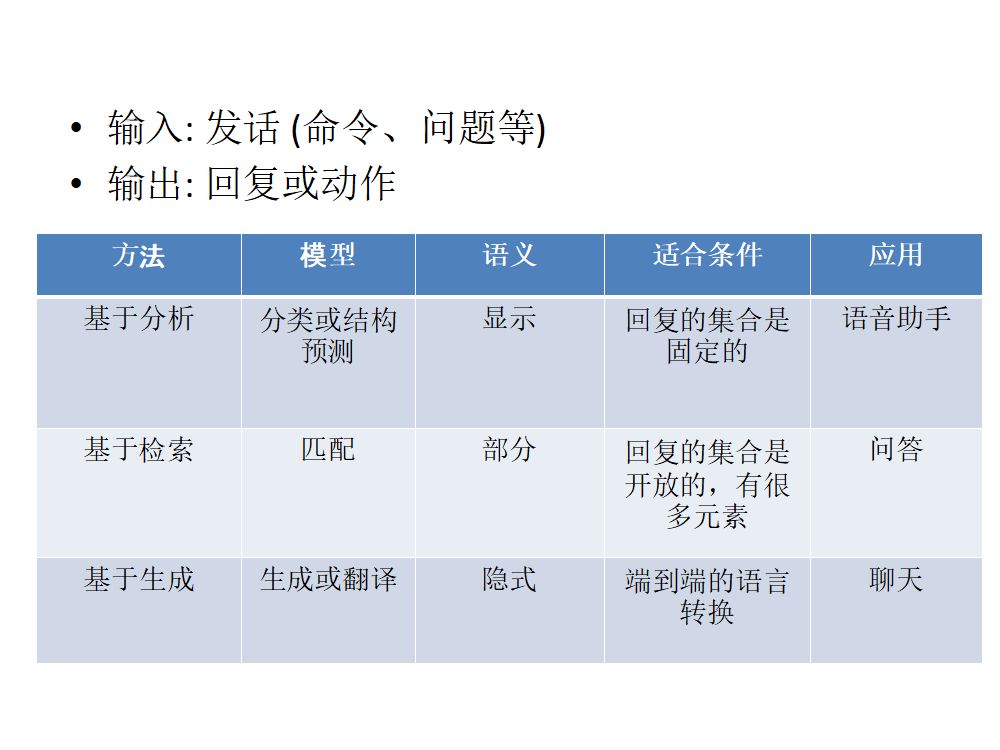
表 1 单轮对话方法比较
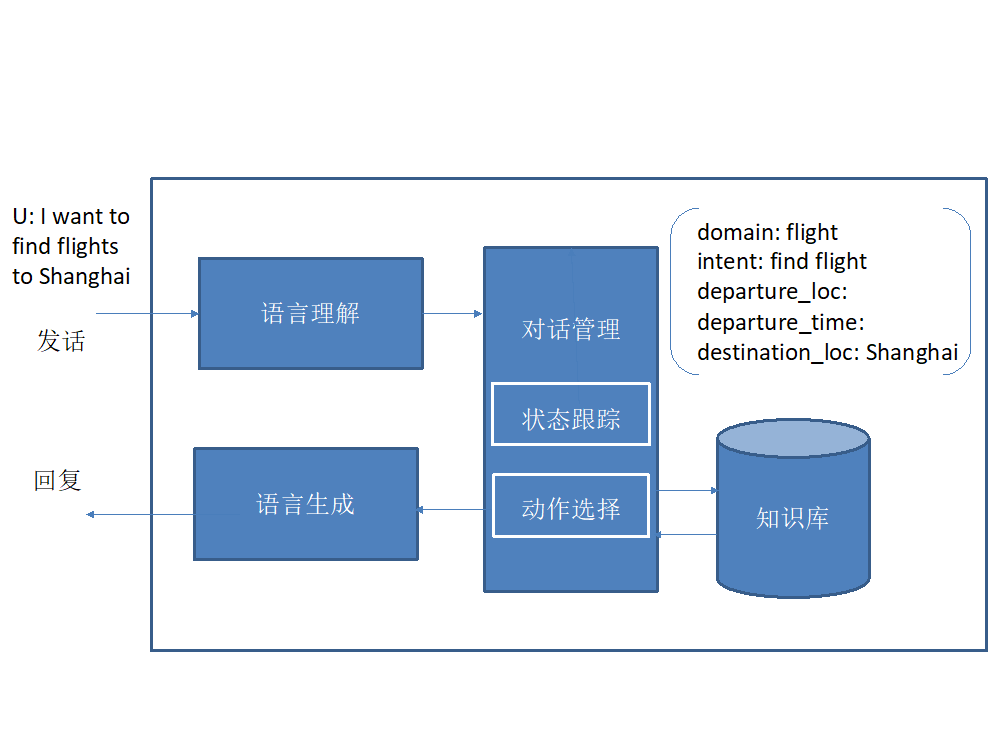
图 2 多轮对话系统
5. 最新进展
近年,深度学习、强化学习被成功应用到包括对话在内的自然语言处理的各个方面,并且取得了重大进展。端到端的训练和表征学习是深度学习的主要特点,正是这些特点使深度学习成为自然语言处理的强大工具,对话也不例外。强化学习适合于系统与环境互动并在这个过程中学习的贯序决策过程(sequential decision process)问题,多轮对话正是其应用。
下面介绍几个最新研究成果。
Liang 等开发了神经符号机(Neural Symbolic Machines)模型 [7]。神经符号机可以从知识图谱三元组中找到答案,回答像「美国最大的城市是哪里?」这样的问题。模型是序列对序列(sequence-to-sequence)模型,将问题的单词序列转换成命令的序列。命令的序列是 LISP 语言的程序,执行程序就可以找到答案。神经符号机的最大特点是序列对序列模型表示和使用程序执行的变量,用附加的键--变量记忆(key-variable memory)记录变量的值,其中键是神经表征、变量是符号表征。模型的训练是基于强化学习(策略梯度法)的端到端的学习。
吕等开发了神经查询器(Neural Enquirer)、符号查询器(Symbolic Enquirer),连接查询器(Coupled Enquirer)三个模型 [8,9],用于自然语言的关系数据库查询。比如,可以从奥林匹克运动会的数据库中找答案,回答「观众人数最多的奥运会的举办城市的面积有多大?」这样的问题。问答系统包括语言处理模块、短期记忆、长期记忆、查询器,语言处理模块又包括编码器和解码器。查询器基于短期记忆的问题表征(神经表征)从长期记忆的数据库中(符号表征与神经表征)寻找答案。
符号查询器是一个循环神经网络,将问句的表征(神经表征)转换为查询操作(符号表征)的序列,执行操作序列就可以找到答案。利用强化学习,具体地策略梯度法,可以端到端地学习这个循环神经网络。神经查询器是一组深度神经网络,将问句的表征(神经表征)多次映射到数据库的一个元素(符号表征),也就是答案,其中一个神经网络表征一次映射的模式。利用深度学习,具体地梯度下降法,可以端到端地学习这些深度神经网络。符号查询器执行效率高,学习效率不高;神经查询器学习效率高,执行效率不高。连接查询器把两者的优点结合起来。学习时先训练神经查询器,然后以其结果训练符号查询器,问答时只使用符号查询器。
Peng 等提出了基于层次化深度强化学习(hierarchical reinforcement learning)的对话策略学习方法,可以通过多轮对话帮助用户做旅行安排,包括预订机票、订酒店 [10]。对话系统整体架构与图 2 的相似,有语言理解、对话管理、语言生成模块。对话管理模块有两层结构,顶层模块负责管理子任务,底层模块负责管理子任务中的动作,状态跟踪模块负责管理全局的跨子任务的约束条件(如酒店的入住时间需晚于航班的达到时间)。对话管理策略通过层次化深度强化学习获得。
6. 未来展望
下面列举自然语言对话中比较重要的研究课题。
• 对话需要语义接地,即将自然语言映射到内部的表征,如何定义和使用语义表征是一个核心问题。
• 语言理解的多义性、多样性问题。虽然迄今有很多研究,但仍然没有根本解决。
• 语言和知识,既可以由符号表征,又可以由向量表征(神经表征),各有优缺点,如何将符号处理和深度学习结合是一个重要的问题。
• 多轮对话系统可以基于深度强化学习,也有很多问题需要研究。
• 对话系统是一个复杂的系统,需要进行层次化和模块化处理,如何构建这样的系统,并使其拥有自动学习功能也是一个大问题。
• 机器学习的数据往往是不够的,这使得端对端训练一个对话系统变得困难,在小样本的条件下学好对话模型是需要解决的重要课题。
7. 总结
以下将本文的主要观点进行总结。
从功能的角度,计算机也有可能能够像人一样,自如地进行自然语言对话,但是现在这个命题无法证真或证伪。原因是尚不清楚人脑的语言理解机制,用计算机完整模拟人的语言理解仍然非常困难。
但在特定领域,特定场景下,和人一样进行自然语言对话的计算机的实现,我们已经看到。问题是如何进行扩展,能够以更低的开发成本覆盖更多的领域和场景。
语言理解的核心是向内部表征的映射。多义性和多样性是计算机进行语言理解最大的挑战。
要完成具体的任务,体现计算机的智能性,定义和使用内部表征看来是不可或缺的。基于分析的方法本质上是重要的,甚至是在聊天机器人的场景。基于检索方法更适合于单轮问答的场景。基于生成的方法只能用于特定的场景。
多轮对话要体现完成任务的整个逻辑,有限状态机表示。开放式的对话意味着动态地改变任务,所以在现在的技术条件下,是非常困难的;在特定领域任务明确的条件下的对话,现实可行。
近年,深度学习和强化学习的使用,使得对话有了长足的进步。主要体现在表征学习、端到端学习上。事实上需要符号表征和神经表征,深度学习和符号处理的结合,这应该是未来发展的重要方向。
-
python自然语言2018-05-02 0
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
自然语言处理的语言模型2020-04-16 0
-
什么是自然语言处理2021-09-08 0
-
什么是自然语言处理_自然语言处理常用方法举例说明2017-12-28 18391
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5379
-
自然语言处理(NLP)的学习方向2020-07-06 13427
-
自然语言对话工具将人工智能跨越裂谷的关键之一2020-08-09 3019
-
自然语言理解问答对话文本数据,赋予计算机智能交流的能力2023-08-07 851
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 1966
-
神经网络在自然语言处理中的应用2024-07-01 764
-
自然语言处理技术的原理的应用2024-07-02 1059
-
自然语言处理属于人工智能的哪个领域2024-07-03 1950
-
自然语言处理包括哪些内容2024-07-03 1538
全部0条评论

快来发表一下你的评论吧 !
