

北斗短报文通信在工业远程监测控制和数据采集中的应用
电子说
描述
北斗卫星导航系统是我国自主建设、独立运行、集导航定位、授时、用户监测、短报文通信于一体的导航系统[1]。短报文通信是北斗系统特有的一个功能,其不受地形条件和环境气候等影响,可用于解决偏远地区数据实时通信问题,特别适用于常规通信手段存在盲区多、基建投入大的场合使用,例如野外的石油、天然气的阀站和门站,以及远离移动网络覆盖地区或者通信不稳定地区工厂的数据传输。
北斗卫星的主要任务是定位导航,通信的信道资源少,民用北斗短报文通信存在单次报文长度和通信频度受限的问题。对于工业远程监测控制和数据采集(Supervisory Control and Data Acquisition,SCADA)项目中的数据而言,数据采集频率高,数据量大。若对数据作分包处理,可实现大量数据传输。但谷军霞[2]等在2015年进行的北斗短报文丢包测试中表明,随着报文分包数的增加,报文的传输成功率逐步降低。若减少对原始工业数据的采样频率,则可降低数据量。但对于企业来说,历史数据是工业现场宝贵的财富,是为后续工程技术人员提供分析和故障处理的基础资料,是不能因为传输的限制就随意减少和丢弃的。因此就需要有一种方法,既可完成实时数据的传输,又不会产生太大的数据量。
短报文通信是我国北斗卫星导航系统特有的一个功能,可用于公网通信覆盖盲区位置的数据传输。而通信频度和报文长度的限制,降低了北斗短报文通信的效率,为此,提出了一种用于北斗通信数据的压缩方法。该压缩方法分两步,第一步为有损压缩,以工业数据库压缩技术中的旋转门算法为基础,同时为了实现有损压缩的精度可调,用改进的BP神经网络PID控制器对旋转门算法的参数进行在线调整;第二步为无损压缩,提出了前置特殊字节配合差值传递的无损压缩策略。实验表明经过此方法两步压缩后,对工业过程数据完成了较高的压缩,同时,压缩精度也可在压缩过程中准确调整。
目前已发表的关于北斗短报文通信的论文中,于龙海提出先建立运动目标的数学模型,通过参数简化和差分编码实现北斗定位数据的压缩[3]。陈海生提出的固定长度的索引码表用于渔获数据的传输,可以解决数据无损压缩传输,但是不具有通用性[4]。彭浩提出了中文智能分词和无损压缩编码的联合压缩算法,进而实现通信数据扩容[5],但是工业过程数据中,主要传输的是实数信息。目前,对于北斗短报文通信的工业过程数据的传输,还没有较实用的数据压缩和传输的解决办法。因此本文提出了一种分别从有损和无损压缩两个方面,对数据分步进行压缩处理的解决方案。实验证明,该方法可有效对短报文数据进行压缩处理,从而提高工业过程数据传输的效率和可靠性。
1 北斗通信压缩第一步:有损压缩
有损压缩是在压缩工程中损失一定的信息以获得较高的压缩比[6]。为后文评价有损压缩过程,本文采用曲奕霖[7]在其论文中提出的评价标准,如下:

CR用于衡量算法对一组数据的压缩能力,而δ用于衡量一组数据的平均失真度。
旋转门算法是一种常见的过程数据压缩算法。本文提出的北斗通信压缩算法中的有损压缩阶段就基于旋转门算法。下面先介绍旋转门算法,再介绍本文提出的基于改进BP神经网络PID的自控精度SDT有损压缩算法(后文简称为自控精度有损压缩算法)。
1.1 标准旋转门算法(SDT)分析
旋转门压缩算法由美国OSI软件公司研发,此算法主要针对的是浮点型的数据。SDT作为线性拟合的一种简便算法,具有效率高、压缩比高、实现简单、误差可控制的优点。基本算法原理如图1所示。
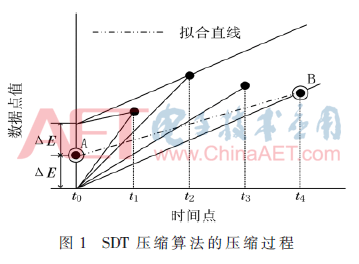
设ΔE为SDT算法的压缩精度参数,图1中A点为起始点,以距离A点为ΔE的上下两点为支点(类似两扇门的门轴,故得名旋转门)。压缩开始时,两扇门是关闭的,且在算法执行过程中,门只能往外开启,不能往内关闭。随着数据点的增加,门就会旋转打开,两扇门的内角和等于180°,就停止操作,存储前一个数据点,并由该点开始新一段压缩。经过旋转门压缩后,由A到B点的直线代替A到B的数据点。
解压过程:根据每段直线保存的起始点和终止点可以求出线段的公式,然后根据某点横轴坐标求出其对应的纵坐标数据值。
1.2 自控精度有损压缩算法算法设计
对于SDT算法有两方面需要注意:(1)ΔE是决定SDT算法解压平均误差δ的关键。如果ΔE选择较小,δ也小,压缩比CR低;反之ΔE选择较大,CR高,δ却也变大。即使是有经验的工程师,也需要长时间调整ΔE才能找到合适的值,且当数据范围和特征改变时,为满足压缩比和精度的要求,还需重新设置。(2)δ通常是作为评价压缩过程好坏的标准,如果δ不符合要求,较高的CR没有任何意义。
基于以上两点,将关注集中在δ的控制上。通过给定理想的δ,用算法自适应调整ΔE。本文将工程中的反馈控制思想引入,用PID算法对ΔE在线调整,同时用神经网络算法动态调整PID参数,并通过其强大的学习和网络记忆功能,实现相似数据快速压缩。
该算法包括两方面内容:改进BP神经网络PID控制器(后文简称为:NBP-PID)和标准SDT压缩及解压算法。数据通过SDT压缩及解压过程视为被控对象,期望的解压平均误差δs作为给定输入,实际解压平均误差δ作为系统的输出。NBP-PID控制器不断调整ΔE的输出,进而控制δ输出,直到偏差值小于算法停止运行的门限值Th为止,这样便完成了第一组数据的压缩。门限值计算公式为:
当首组数据压缩完成后,保留此时控制器各个参数,用做下一组数据压缩时控制器参数的初始值,完成第二组数据的压缩,以此类推。同时将压缩好的首组数据用北斗无损压缩算法继续压缩。图2为首组数据压缩算法的反馈控制系统模型。
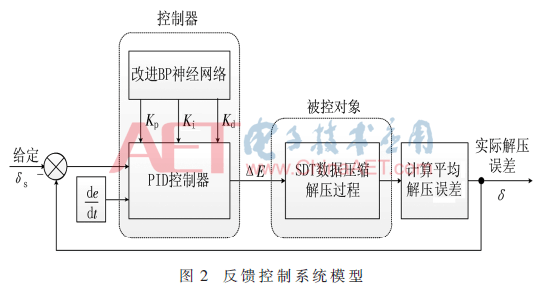
1.2.1 NBP-PID控制器设计
在工业控制中,对PID控制器比例、积分、微分3个系数的调整一般很难。根据神经网络理论,三层BP神经网络可逼近任意线性和非线性函数,通过神经网络的自身学习,加权系数调整可以使其稳定状态对应某种最有规律下的PID控制器参数[8]。于是本文采用三层BP神经网络(4-5-3结构)来调整PID的参数。
输入层神经元为4个,分别是输入rin、输出yout、误差error和常数1;隐含层选择5个即可满足要求,3个输出神经元对参数Kp、Ki、Kd进行在线调整。输入层的输入为:

1.2.2 自控精度有损压缩算法实现步骤
(1)第一次进行压缩时,对相应的参数初始化。令u、u_1、u_2、u_3、u_4、u_5,即控制器的输出零时刻和各历史时刻初始值都为0,同时误差error、输出值yout零时刻和各历史时刻也都初始化为0。隐含层的加权系数初始值和和输出层加权系数的初始值为-0.5~0.5之间的随机数。选定学习速率η、惯性系数α和β,以及门限值Th;
(2)采样得到rin(k);将前一时刻控制器的输出u(k-1),即ΔE传入代表被控对象模型的压缩解压函数中计算,得到此时的输出yout值,再计算该时刻的系统误差error(k)=rin(k)-yout(k);
(3)计算神经网络各层神经元的输入、输出,输出层的输出即对应PID控制器的3个可调参数Kp、Ki、Kd,据此计算控制器当前时刻的输出u(k);
(4)进行神经网络学习,在线调整输出层和隐含层加权系数值,然后将各状态参数更新;
(5)根据式(3),计算系统此时的Th值,如果小于预先设置的门限值,则表明此组数据已达到给定误差压缩要求,进入步骤(6),否则进入步骤(2),再次循环;
(6)将此时刻以及前3个时刻的输出层及隐含层加权系数值保存,作为下组数据压缩时零时刻及历史时刻的初始值,保存u及前5个时刻的值,作为下组数据压缩各时刻u的初始值。同时,此组压缩后的数据进入后续北斗无损压缩算法中继续压缩;
(7)利用前一组保存的控制器各参数开始下一组数据的压缩,即又一次进入步骤(2),直到所有组别的数据都压缩完毕,算法结束。
2 北斗通信压缩第二步——无损压缩
相对于有损压缩来说,无损压缩占用空间大,压缩比不高,但它 100%地保存了原始信息,没有任何信号丢失,不受信号源影响[9]。 一般的工业过程数据都有明确的物理含义,以项目中某能源公司提供的天然气阀站数据为例,包含了温度、流量、压力、阻力等模拟量信息,也有阀门启停、报警等状态量信息。
本文以过程数据中最常见的流量/压力/阻力为例,对北斗无损压缩算法作介绍。
2.1 数据预处理
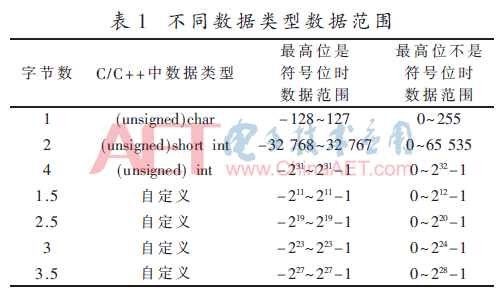
假设待压缩实数数据精度为两位小数,数据大小为0.00~999 999.00。且以一个float fRevBuf[500] 类型数组保存,若将此数组每个元素都乘以100,则其小数部分全部转化成了整数,再用强制类型转化得到4 B的无符号整形数组 iPlc[500]。不同类型的整数可表示的数据范围如表1前3行所示,且根据整数在计算机中的保存方式[10],可推得后面的4种情况。
2.2 北斗短报文通信无损压缩算法
过程数据一般是按时间的先后顺序采集的数据,数据中带有时间特性,大多数工业现场采集数据都是过程数据[11]。因此,数据之间在数值上是有关联的,所以根据相邻数组元素的差值,而不是元素值本身,对其分配存储空间更为合理。下面为具体步骤:
(1)新建数组 int iSub[500],用于保存数组iPlc中相邻元素的差值,即:iSub[i+1]=iPlc[i]-iPlc[i+1]; 并将iPlc数组中的首元素赋值给iSub数组中的首元素。
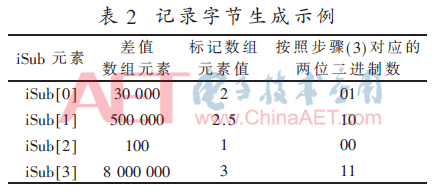
(2)根据差值数组iSub中的每个元素的值大小,对照表1,给每个元素分配一个从1~4不等的字节长度标记,并用另一个数组iLethByte作出记录。如表2中,差值元素为100,iLethByte数组相同下标元素值为1。
(3)iLethByte数组中每一个元素记录了相同下标位置的差值数组iSub每一个元素所需存储空间的最小字节长度,为了在北斗接收端作解压缩,除了传递iSub数组外也需要传递长度标记数组iLethByte,但这样需要传递的数据量过大。根据表1可知,以不同字节长度可表示的不同的数值范围为依据,可分为7种类型,但现实中不需要每次都分成7种类型,因为过程数据数值大小具有一定的连续性,并不是平均分布的,于是每次压缩时根据过程数据本身的分布规律选择其中的4种(选择的原则后面会补充)类型作为本次传输的标准类型,包含在其余类型里的数据最终会归类到这4种标准类型中,然后用两位二进制数代码来代指此次选出的4个标准类型。例如,此次的4个标准类型字节长度为1、2、2.5、3,则它们的二进制数代码可依次为:00 01 10 11。然后每个元素按照所在的标准类型的字节长度压缩数据,变成一个个存储长度不等的数据,再将每4个变换之后的iSub数组元素组成一组,在每组前面添加一个记录字节bt4Record,bt4Record为8位,每两个二进制位可表示一个iSub元素所在的标准类型的代码,且iSub元素在前面的对应bt4Record的高位,在后面的对应bt4Record的低位,如表2所示。至此,表2中这4个iSub元素前面的bt4Record字节二进制表示为:01100011。
(4)标准类型的选择组合共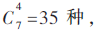 为让接收端确定是哪种组合,需要额外传递当前组合的编号。且单次需要压缩的数据个数如不是4的倍数,则使最后一个bt4Record字节不够8位,此时对于不足的字节先补零,然后额外传递本组压缩数据的总数值,便可使北斗接收端解压无误。在每组报文的开头,取两个字节(16个bit位),其中10个bit位记录本次压缩的数据元素总数值(10位可表示:210=1 024个数,足够),剩余6个bit位(26=64》35)表示标准类型组合编号。
为让接收端确定是哪种组合,需要额外传递当前组合的编号。且单次需要压缩的数据个数如不是4的倍数,则使最后一个bt4Record字节不够8位,此时对于不足的字节先补零,然后额外传递本组压缩数据的总数值,便可使北斗接收端解压无误。在每组报文的开头,取两个字节(16个bit位),其中10个bit位记录本次压缩的数据元素总数值(10位可表示:210=1 024个数,足够),剩余6个bit位(26=64》35)表示标准类型组合编号。
至此,一次北斗短报文的数据报文打包完成。
(5)将经过步骤处理后的数据通过北斗设备发送到接收端。接收端解压时,先取出前两个字节,根据6个比特位的分类编号确定此组数据中的四种标准类型;根据10个比特位的数据个数,确定此组原始数据的总个数。然后依次先取bt4Record,再按照此字节的记录长度对每个差值元素取数,分别保存成整数,再依次取下一个bt4Record字节。对于接收到数据字节长度为1、2、4类型的,可根据表1直接强制类型转化变回4个字节的整数;对于其余自定义类型,则需要提取符号位,再根据正数的补码与原码相同,负数的补码为原码取反加一原则处理转化成4个字节的整数。
(6)将步骤(5)保存的整数缩小100倍,再保存成实数类型,至此完成北斗无损压缩的解压缩过程。
补充:一组数据中最大值所在的类型必须是本次选取的标准类型之一。例如iSub[4]元素最大值为8 000 000,则字节为3的标准类型必须取,后再取其他可包含元素值最多的3个类型作为标准类型。
3 试验结果与对比分析
实验数据源于一滚铆实验机床,其作用是用滚铆工具碾压轴承外环边缘的环形槽,使环形槽的一侧边缘向座圈孔或轴承的变形,进而实现轴向固定。数据源自机床中的压力传感器,一组数据表示一次压紧过程,原始压力曲线如图3所示。(原始数据共18组,编号:S1~S18)图中曲线下降阶段是因为电机停转,压力逐步除去引起的,停机时间人为控制,故为排除人为干扰,每组只取前20 s的数据(200个)。
后续实验中都选定rin(k)为1,学习速率η为1.4,惯性系数α为0.3,β为0.5,门限值Th为0.1。且后续段落中,“第一阶段”指的是北斗通信压缩中的有损压缩阶段,“第二阶段”为无损压缩阶段。
3.1 NBP-PID与标准BP神经网络PID控制器性能对比
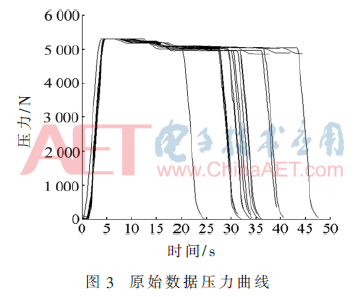
图4为在第一阶段中,NBP-PID算法较标准BP神经网络PID算法(简称为BP-PID),6组数据单独压缩时各自达到门限值所需压缩训练次数对比。
分析图4可知,在修改网络权值时,增加一个k-2时刻的惯性项和“阶梯惯性项”系数的NBP-PID算法,可以减少重复压缩的次数,从而更快达到门限值。
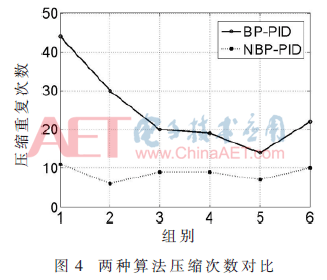
图5为第一组(S1)数据分别采用两种算法解压误差和训练次数的曲线图,采用NBP-PID可在训练11次时达到门限值,即达到给定值的90%以上而结束训练,而BP-PID在最大训练次数(20)内无法达到给定值的90%。综上,NBP-PID的确可以有效加快训练过程,减少重复压缩的次数,从而提升算法的实用性。
3.2 采用NBP-PID算法压缩多组数据
表3给出当首组数据压缩完成后,后续组别依次继续压缩,达到门限值的压缩次数的测试数据。

根据表3知,首次压缩数据在10次左右,后续组别重复压缩次数除了个别组别达到最大训练次数,其余数据组别基本可在一两次之内完成压缩。因此通过NBP-PID网络权值记忆功能,当类似数据出现时,可一定程度上加快后续组的压缩,提升整体压缩效率。
3.3 北斗通信压缩算法整体压缩分析
表4描述了两个阶段压缩过程中具体压缩信息。为排除偶然性,这里用的数据与前面实验的数据不同,采用S10~S14的5组数据作为实验数据。
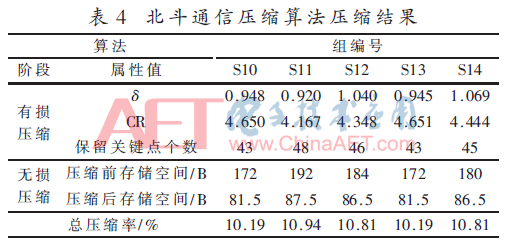
这5组数据的平均解压误差δ在1.0附近,满足给定值上下波动10%以内的要求。有损压缩阶段的压缩比平均为4.452,实现了用户自定义压缩误差的同时还能拥有不错的压缩比。无损压缩阶段中,压缩后的存储空间是压缩后的数组元素所占空间之和,加上记录字节所占空间之和,再加上处在报文开头的两个字节的总和。
总压缩率是无损压缩之后所占存储空间与原始数据所占存储空间(800=4×200)之比。可以看到,经过两个阶段的压缩之后,数据被压缩到了原始数据的10.5% 左右。由此可见北斗压缩算法的压缩效果良好。
4 结论
本文提出的有损压缩算法已经在实验室环境中完成测试,无损压缩算法在某天然气管线监测项目中实际完成测试部署,效果良好。基于北斗通信的工业数据压缩算法一方面解决了SDT压缩精度不可控、参数设置困难等问题;另一方面,数据经过两个阶段的压缩,获得了较高的压缩比。此外,该算法不仅可用于北斗短报文通信,也可用于其他通信频度和报文长度受限的场合下,因此该算法具有工程实用价值。
参考文献
[1] 杨元喜。北斗卫星导航系统的进展、贡献与挑战[J]。测绘学报,2010,39(1):1-6.
[2] 谷军霞,王春芳,宋之光。北斗短报文通信信道性能测试与统计分析[J]。气象科技,2015,43(3):458-463.
[3] 于龙洋,王鑫,李署坚,等。基于北斗短报文的定位数据压缩和可靠传输[J]。电子技术应用,2012,38(11):108-111.
[4] 陈海生,郭晓云,王峰,等。基于北斗短报文的渔获信息压缩传输方法[J]。农业工程学报,2015,31(22):155-160.
[5] 彭皓。北斗系统用户通信数据扩容技术研究[D]。西安:西安电子科技大学,2013.
[6] 徐慧。实时数据库中数据压缩算法的研究[D]。杭州:浙江大学,2006.
[7] 曲奕霖,王文海。用于过程数据压缩的自控精度SDT算法[J]。计算机工程,2010,36(22):40-42.
[8] 谭永红。基于BP神经网络的自适应控制[J]。控制理论与应用,1994,11(1):84-87.
[9] 郑翠芳。几种常用无损数据压缩算法研究[J]。计算机技术与发展,2011,21(9):73-76.
[10] 张德伟,沈培锋,张德珍,等。计算机补码概念剖析[J]。微计算机信息,2005,21(20):177-178.
[11] 沈春锋,黄松鑫,张冬,等。基于参数估计的通用工业数据在线压缩方法[J]。控制工程,2011(s1):142-145.
作者信息:
陈 勇,黄茹楠,刘 青,李建坡,李 鑫
(燕山大学 电气工程学院,河北 秦皇岛066004)
-
北斗短报文电网状态监测及应急通信系统_刘艳2017-01-17 1083
-
基于北斗短报文协议的可靠远程通信系统2018-02-09 2267
-
北斗终端、北斗短报文终端是什么?2022-07-01 8081
-
北斗手持机短报文是怎么实现通信的?2022-10-12 6876
-
北斗短报文通信原理、作用和应用领域2023-03-15 18873
-
北斗短报文是什么?看完你就懂了2024-03-14 3771
-
北斗三短报文终端是什么?看完你就懂了2024-03-19 2100
-
北斗短报文终端通信应用解决方案2024-05-20 1240
-
什么是北斗短报文功能?如何实现北斗短报文通信?2024-05-25 8348
-
北斗短报文通信在应急指挥调度的应用方案2024-05-27 1097
-
北斗短报文终端在应急消防通信场景中的应用2024-06-20 1140
-
北斗短报文终端如何进行双向通信?2024-07-12 2366
-
北斗短报文终端支持民用吗?2024-08-09 1153
-
北斗短报文是如何实现应急通信救援?2024-09-25 1487
-
智芯公司聚力攻关北斗短报文通信技术2024-12-13 969
全部0条评论

快来发表一下你的评论吧 !
