

GAN技术再到新高度 利用pytorch技术生成72种图像
电子说
描述
随着GAN的发展,单凭一张图像就能自动将面部表情生成动画已不是难事。但近期在Reddit和GitHub热议的新款GANimation,却将此技术提到新的高度。GANimation构建了一种人脸解剖结构(anatomically)上连续的面部表情合成方法,能够在连续区域中呈现图像,并能处理复杂背景和光照条件下的图像。
若是能单凭一张图像就能自动地将面部表情生成动画,那么将会为其它领域中的新应用打开大门,包括电影行业、摄影技术、时尚和电子商务等等。随着生成网络和对抗网络的流行,这项任务取得了重大进展。像StarGAN这样的结构不仅能够合成新表情,还能改变面部的其他属性,如年龄、发色或性别。虽然StarGAN具有通用性,但它只能在离散的属性中改变面部的一个特定方面,例如在面部表情合成任务中,对RaFD数据集进行训练,该数据集只有8个面部表情的二元标签(binary label),分别是悲伤、中立、愤怒、轻蔑、厌恶、惊讶、恐惧和快乐。
GANimation的目的是建立一种具有FACS表现水平的合成面部动画模型,并能在连续领域中无需获取任何人脸标志(facial landmark)而生成具有结构性(anatomically-aware)的表情。为达到这个目的,我们使用EmotioNet数据集,它包含100万张面部表情(使用其中的20万张)图像。并且构建了一个GAN体系结构,其条件是一个一维向量:表示存在/缺失以及每个动作单元的大小。我们以一种无监督的方式训练这个结构,仅需使用激活的AUs图像。为了避免在不同表情下,对同一个人的图像进行训练时出现冗余现象,将该任务分为两个阶段。首先,给定一张训练照片,考虑一个基于AU条件的双向对抗结构,并在期望的表情下呈现一张新图像。然后将合成的图像还原到原始的样子,这样可以直接与输入图像进行比较,并结合损失来评估生成图像的照片级真实感。此外,该系统还超越了最先进的技术,因为它可以在不断变化的背景和照明条件下处理图像。
最终,构建了一种结构上连续的面部表情合成方法,能够在连续区域中呈现图像,并能处理复杂背景和光照条件下的图像。它与其他已有的GAN方法相比,无论是在结果的视觉质量还是生成的可行性上,都是具有优势的。
图1:根据一张图像生成的面部动画
无监督学习+注意力机制
让我们将一个输入RGB图像定义为 ,这是在任意面部表情下捕获的。通过一组N个动作单元
,这是在任意面部表情下捕获的。通过一组N个动作单元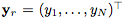 对每个手势表达式进行编码,其中每个
对每个手势表达式进行编码,其中每个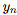 表示0到1之间的归一化值,表示第n个动作单元的大小。值得指出的是,由于这种连续的表示,可以在不同表情之间进行自然插值,从而可以渲染各种逼真、流畅的面部表情。
表示0到1之间的归一化值,表示第n个动作单元的大小。值得指出的是,由于这种连续的表示,可以在不同表情之间进行自然插值,从而可以渲染各种逼真、流畅的面部表情。
我们的目标是学习一个映射 ,将
,将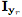 转换成一个基于动作单元目标
转换成一个基于动作单元目标 的输出图像
的输出图像 ,即:我们希望估计映射:
,即:我们希望估计映射:
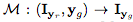
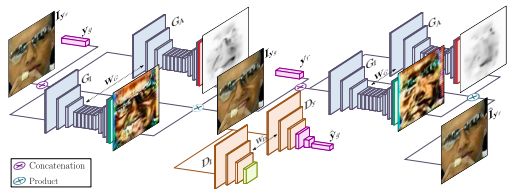
图2. 生成照片级真实条件图像方法的概述
所提出的架构由两个主要模块组成:用于回归注意力和 color mask 的生成器G; 用于评估所生成图像的真实度 和表情调节实现
和表情调节实现 的评论家(critic) D。
的评论家(critic) D。
我们的系统不需要监督,也就是说,不需要同一个人不同表情的图像对,也不假设目标图像
生成器G
生成器器 被训练来逼真地将图像
被训练来逼真地将图像
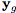
我们系统的一个关键要素是使G只聚焦于图像的那些负责合成新表情的区域,并保持图像的其余元素如头发、眼镜、帽子、珠宝等不受影响。为此,我们在生成器中嵌入了一个注意力机制。
图3:Attention-based的生成器
给定一个输入图像和目标表情,生成器在整个图像上回归并注意mask A和RGB颜色变换C。attention mask 定义每个像素强度,指定原始图像的每个像素在最终渲染图像中添加的范围。
具体地说,生成器器不是回归整个图像,而是输出两个mask,一个color mask C和一个attention mask A。最终图像可表示为:
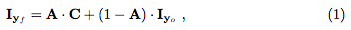
首先测试主要组件,即单个和多个AU编辑。然后将我们的模型与离散化情绪编辑任务中的当前技术进行比较,并展示我们的模型处理野外图像的能力,可以生成大量的解剖学面部变换的能力。最后讨论模型的局限性和失败案例。
值得注意的是,在某些实验中,输入的面部图像是未被裁剪的。在这种情况下,我们首先使用检测器2来对面部进行定位和裁剪,利用(1)式进行表达式的转换,以应用于相关区域。 最后,将生成的面部图像放回原图像中的原始位置。注意力机制(attention mechanism)可以确保经过变换处理的裁剪面部图像和原始图像之间的平滑过渡。
稍后图中可见,与以前的模型相比,经过这三个步骤的处理可以得到分辨率更高的图像(链接见文末)。
图4:单个动作单元的编辑
随着强度(0.33-1)的增加,一些特定的动作单元被激活。图中第一行对应的是动作单元应用强度为零的情况,可以在所有情况下正确生成了原始图片。
图5: 注意力模型
中间注意力掩模A(第一行)和颜色掩模C(第二行)的细节。 最底下一行图像是经合成后的表达结果。注意掩模A的较暗区域表示图像的这些区域与每个特定的动作单元的相关度更高。 较亮的区域保留自原始图像。
图6: 与当前最先进技术的定性比较
图为面部表情图像合成结果,分别应用DIAT、CycleGAN、IcGAN、StarGAN和我们的方法。可以看出,我们的解决方案在视觉准确度和空间分辨率之间达到了最佳平衡。 使用StarGAN的一些结果则出现了一定程度的模糊。
图7:采样面部表情分布空间
通过yg向量对活动单元进行参数化,可以从相同的源图像合成各种各样的照片的真实图像。
图8:自然图像的定性评估
上图:分别给出了取自电影《加勒比海盗》中的一幅原图像(左)及其用我们的方法生成的图像(右)。 下图:用类似的方式,使用图像框(最左绿框)从《权力的游戏》电视剧中合成了五个不同表情的新图像。
图9:成功和失败案例
图中分别表示了源图像Iyr,目标Iyg,以及颜色掩膜C和注意力掩模A. 上图是在极端情况下的一些成功案例。 下图是一些失败案例
-
华为助力埃塞俄比亚电信通信网络技术迈向新高度2025-08-20 1127
-
黑芝麻智能引领人形机器人技术迈向新高度2025-03-12 2019
-
利用Arm Kleidi技术实现PyTorch优化2024-12-23 2079
-
光纤矩阵,提升视觉体验新高度2023-09-01 1360
-
高技传动科技登陆央视,国家平台助力打造品牌新高度2021-12-30 1426
-
音圈马达加持的vivoX70再创手机影像新高度2021-09-16 1386
-
图像生成对抗生成网络gan_GAN生成汽车图像 精选资料推荐2021-08-31 1249
-
ZIF架构有哪些优势?如何使无线电设计性能达到的新高度?2021-03-11 2387
-
华为手机或将凭借麒麟990达到新高度2019-08-26 4187
-
重磅新品 | 解锁空间受限的消费和工业应用,ams微型摄像头引领摄像新高度2019-07-03 3872
-
必读!生成对抗网络GAN论文TOP 102019-03-20 7595
-
5G助力MBB走向新高度2018-06-28 9108
-
一种将电子配线架灵活性提升到新高度的创新方案2018-04-23 9588
-
Maxim全新高度集成的数字脉冲发生器2009-11-20 605
全部0条评论

快来发表一下你的评论吧 !
