

Google翻译出现“水逆”,是员工的恶作剧?
电子说
描述
最近,一些网友使用的 Google 翻译“水逆”了。
在 Reddit 上,有网友截图显示,在 Google 翻译中当某些语种的词汇翻译成英语时,输出的却是毫无由头的宗教语言。比如键入 19 个 dog,将其从毛利语翻译成英语时,输出的却是“距离十二点的世界末日时钟还差三分钟,我们正在经历世界上的人物和戏剧性发展,这预示着我们正在无线接近末日,耶稣回归时日将近。”
但这只是众多无厘头翻译的其中之一。还有网友放出了很多“不详”的翻译内容。例如,在索马里语中,“ag”这个词被翻译成了“Gershon 的儿子(sons of Gershon)”,“耶和华的名字(name of the LORD)”,并且会引用圣经里的“cubits”(计量单位)和Deuteronomy(《申命记》)。
有网友留言称其为“恶魔”或者“幽灵”,猜测这是 Google 员工的恶作剧,也有人建议设置“建议编辑”功能,让用户可以进行修改为正确内容。Google 发言人 Justin Burr 在一封电子邮件中称:这只是一个将无意义的话语输入系统然后产生无意义输出的功能。
不过 Justin Burr 并未透露 Google 翻译使用的训练数据是否有宗教文本。但上述诡异输出内容很可能已被 Google 翻译修正,AI科技大本营编辑输入上述相同内容后也并未发现异常。
但人们对探讨 Google 翻译出现如此结果的背后原因热情不减,更专业的声音在不断发出。哈佛大学助理教授 Andrew Rush 认为,这很可能与 2 年前 Google 翻译技术的改变有关,它目前使用了的是“神经机器翻译(NMT)”的技术。
BBN Technologies 的科学家 Sean Colbath 从事机器翻译工作,他同意奇怪的输出可能是由于 Google 翻译的算法试图在混乱中寻找秩序。他还指出,索马里语、夏威夷语以及毛利语等产生最奇怪结果的语言,它们用于训练的翻译文本比英语或汉语等更广泛使用的语言要少很多。所以他认为,Google 可能会使用像圣经等被翻译成多种语言的宗教文本来训练小语种的模型,这也解释了为什么会最终输出宗教内容。
前 Google 员工 Delip Rao 在其博客上则指出,当谈到平行语料库时,宗教文本是最低层次的共同标准资源,像“圣经”和“古兰经”这样的主要宗教文本有各种语言版本。
比如,如果你为政府部署一个 Urdu-to-English (乌尔都语——英语)的机器翻译系统,那么很容易将一堆已经翻译成乌尔都语的宗教文本组合在一起。因此,可以合理地假设 Google 的平行语料库中包含所有的宗教文本,而对于许多资源不足的语言,它们不只是训练语料库中微不足道的部分。
那么,为什么我们看到 Google 翻译会输出宗教文本,尤其是以那些资源不足的语言对作为输入时 ,如上文中的毛利语?一种解释是,因为宗教文本包含许多只会在宗教文本中出现的罕见词,而这些词在其他任何地方都不会出现。因此,罕见的词语可能会触发解码器中的宗教情境,尤其是当这些文本的比例很大时。另一种解释是该模型对输入的内容没有太多的统计支持,而输出也只是解码器模型的无意义采样。
更重要的是,他想要指出现在的神经机器翻译 (NMT) 真正存在的问题。
他特意总结了2017 年 Philipp Koehn 和 Rebecca Knowles 撰写的一篇论文,内容如下:
1.NMT 在域外数据上表现很差:像 Google 翻译这样的通用 MT 系统在法律或金融等专业领域的表现尤其糟糕。此外,与基于短语的翻译系统等传统方法相比,NMT 系统的效果更差。到底有多糟糕?如下图所示,其中非对角线元素表示域外结果,绿色是 NMT 的结果,蓝色是基于短语的翻译系统的结果。
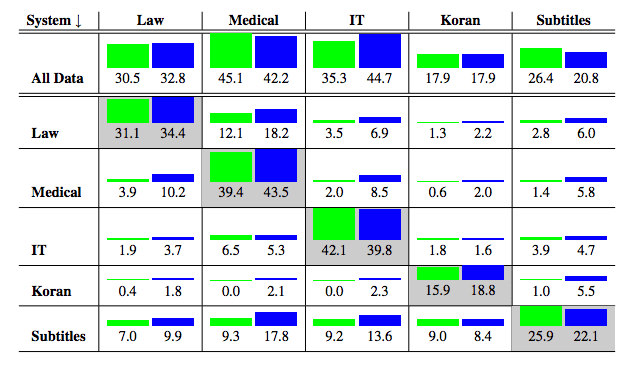
MT 系统在一个域 (行) 上训练并在另一个域 (列) 上进行测试。蓝色表示基于短语翻译系统的表现,而绿色表示 NMT 的表现。
2.NMT 在小数据集上的表现很差:虽然这算是机器学习的通病,但这个问题在 NMT 中体现尤其明显。相比基于短语的 MT 系统,虽然 NMT 随着数据量的增加能进行更好地概括 ,但在小数据量情况下 NMT 的表现确实更糟糕。
引用作者的话来说,“在资源较少的情况下,NMT 会产生与输入无关的输出,尽管这些输出是流畅的。”这可能也是 Motherboard 那篇文章中探讨 NMT 表现怪异的另一个原因。
3.Subword NMT 在罕见词汇上的表现很糟糕:虽然它的表现仍然要好过基于短语的翻译系统,但对于罕见或未见过的词语,NMT 的表现不佳。例如,那些系统只观察到一次的单词就会被 drop 掉。像 byte-pair encoding 这样的技术对解决这个问题有所帮助,但我们有必要对此进行更详细的研究。
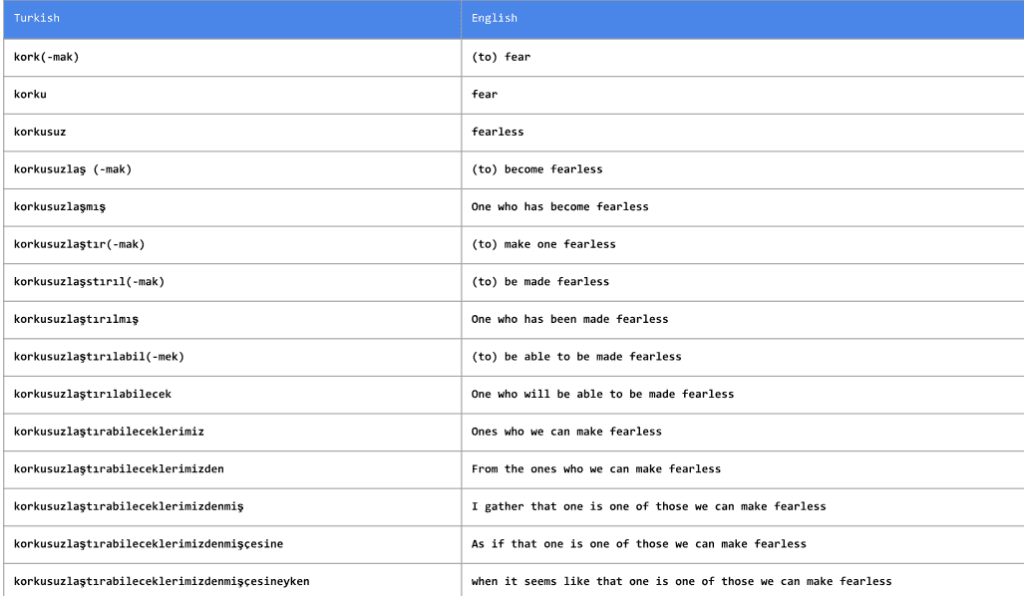
我们可以看到图中像土耳其语 (Turkish) 这样的语言,遇到词的变形形式是很常见的。
4.长句:以长句编码并产生长句,这仍然是一个开放的、值得研究的话题。在法律等领域,冗长复杂的句子是很常见的。MT 系统的性能将随句子长度而降级,而 NMT 系统亦是如此。引入注意力机制可能会有所帮助,但问题还远未解决。
5.注意力机制 != 对齐:这是一个非常微妙但又很重要的问题。在传统的 SMT 系统中,如基于短语的翻译系统,语句对齐能够提供有用的调试信息来检查模型。但即便论文中经常将软注意力机制视为“软对齐”,注意力机制并不是传统意义上的对齐。在 NMT 系统中,除了源域中的动词外,目标中的动词也可以作为主语和宾语。
6.难以控制翻译质量:每个单词都有多种翻译,并且典型的 MT 系统对源句的翻译好于 lattice of possible translations。为了保持后者的大小合理,我们使用集束搜索 (beam search)。通过改变波束的宽度,来找到低概率但正确的翻译。而对于 NMT 系统,调整集束尺寸似乎没有任何不利影响。
当你拥有大量数据时,NMT 系统的翻译性能依然还是难以被击败的,而且它们仍然在大量地被使用。关于通常我们所说的神经网络模型的黑盒性,也有待进一步说明,如今的 NMT 模型 (基于 LSTM 和 Transformer 模型) 也都受此影响。
-
12864同时显示汉字和数字时会出现乱码。。2013-04-19 6182
-
BME280 温湿度气压中文手册 部分翻译有误亲参照原文(已上传)2018-08-17 7847
-
怎么很快速的翻译出电容对应的规格?2018-12-20 1323
-
一众科技厂商竞相推出“翻译蛋”“翻译机”等各色智能翻译设备2018-07-27 7564
-
如何在没有大量标记数据的情况下,让计算机也学会翻译?2018-09-05 4895
-
无需翻译的无监督复述的新方法:允许从输入句子生成多样化、但语义上接近的句子2019-06-29 4292
-
Google Lens中AR翻译功能移植到VR平台2019-08-29 1287
-
Google翻译内核升级误差再降55%2020-05-10 991
-
Google的翻译功能将不再仅限于智能手机2020-07-28 2518
-
Google遵循AI原则减少机器翻译的性别偏见2021-08-24 3848
-
STM32 HAL库学习小计:如何解决编译出现大量未定义错误2022-01-25 1867
-
Arduino蜈蚣掉落恶作剧2022-11-28 292
全部0条评论

快来发表一下你的评论吧 !
