

机器学习开发者如何寻找满足自己需求的第三方库?
描述
在软件开发中容易被忽视的重要事情之一是共享代码存储库的想法。作为程序员,充分利用第三方库使开发更高效。从某种意义上说,他们改变了软件的开发过程。
机器学习开发者如何寻找满足自己需求的第三方库?当然,除了共享代码之外,我们还想分享预训练模型。共享预训练模型使开发人员可以根据不用领域、不用场景进行自定义,而无需访问计算资源或用于训练原始模型的数据。例如,NASNet 需要数千小时进行模型训练。通过共享学习的权重,模型开发人员可以使其他人更容易重用和构建工作。
机器学习模型的 “成分” 被打包,并通过 TensorFlow Hub 进行共享 。从某种意义上说,除了架构本身之外,共享预先训练的模型还共享用于开发模型所用的计算时间和数据集。
TensorFlow Hub 专门为机器学习开发者提供第三方库。在本文中,我们将简单介绍 TensorFlow Hub 中常用的几种库。TensorFlow Hub 是一个平台,主要被用于发布、发现和重用机器学习模块。一个模块,我们指的是 TensorFlow 图形的一个独立部分及其权重,可以在其他类似任务中重复使用。通过重用模块,开发人员可以使用较小的数据集训练模型,提升泛化能力或简单地加速训练。让我们看几个例子来说明这一点。
图像再训练
作为第一个例子,让我们看一下可以用来训练图像分类器的技术,仅从少量训练数据开始。现代图像识别模型具有数百万个参数,当然,从头开始训练需要大量标记数据和计算能力。使用称为图像重新训练的技术,您可以使用更少量的数据训练模型,并且使用更少的计算时间。如下所示:
1 # Download and use NASNet feature vector 2 module.
3 module = hub.Module(
4 “https://tfhub.dev/google/imagenet/nasnet_large/feature_vector/1")
5 features = module(my_images)
6 logits = tf.layers.dense(features, NUM_CLASSES)
probabilities = tf.nn.softmax(logits)
基本思想是重用现有的图像识别模块从图像中提取特征,然后在这些特征之上训练新的分类器。如您所见,在构造 TensorFlow 图时,可以从 URL(或从文件系统路径)实例化 TensorFlow Hub 模块。
TensorFlow Hub 上有多种模块供您选择,包括 NASNet,MobileNet(包括最近的 V2),Inception,ResNet 等。要使用模块,请导入 TensorFlow Hub,然后将模块的 URL 复制/粘贴到代码中。

每个模块都定义了接口,我们可以在很少或根本不了解其内部的情况下以可替换的方式使用。在这种情况下,此模块有一个方法可用于获取预期的图像大小。作为开发人员,您只需要提供正确形状的一批图像,并调用模块以获取特征表示。此模块负责为您预处理图像,因此您可以在一个步骤中直接从一批图像转到特征表示。从这里开始,您可以在这些基础上学习线性模型或其他类型的分类器。
请注意我们正在使用的模块由 Google 托管,并且已经进行版本控制。模块可以像普通的 Python 函数一样应用,以构建图形的一部分。一旦导出到磁盘,模块就是自包含的,并且可以被其他人使用而无需访问用于创建和训练它的代码和数据。
文本分类
我们来看看第二个例子。想象一下,你想训练一个模型,将电影评论分类为正面或负面,从少量的训练数据开始(比如几百个正面和负面的电影评论)。由于您的示例数量有限,因此您决定利用先前在更大的语料库中训练的单词嵌入数据集。如下所示:
1 # Download a module and use it to retrieve word embeddings.
2 embed = hub.Module(“https://tfhub.dev/google/nnlm-en-dim50/1")
3 embeddings = embed([“The movie was great!”])
和以前一样,我们首先选择一个模块。TensorFlow Hub 有多种文本模块供您探索,包括各种语言的神经网络语言模型,以及在维基百科上训练的 Word2vec,以及在 Google 新闻上训练的 NNLM。

在这种情况下,我们将使用一个模块进行字嵌入。上面的代码下载一个模块,用它来预处理一个句子,然后获取每个标记的嵌入。
这意味着您可以直接从数据集中的句子转换为适合分类器的格式。该模块负责对句子进行标记,以及其他逻辑。预处理逻辑和嵌入都封装在一个模块中,可以更轻松地试验各种单词嵌入数据集或不同的预处理策略,而无需大幅更改代码。

如果您想尝试,请使用本教程进行操作,并了解 TensorFlow Hub 模块如何与 TensorFlow Estimators 配合使用。
注:教程链接
https://www.tensorflow.org/hub/tutorials/text_classification_with_tf_hub
通用句子编码器
我们还分享了一个新的 TensorFlow Hub 模块!下面是使用 Universal Sentence Encoder 的示例。它是一个句子级嵌入模块,适用于各种数据集。它擅长语义相似性,自定义文本分类和聚类。
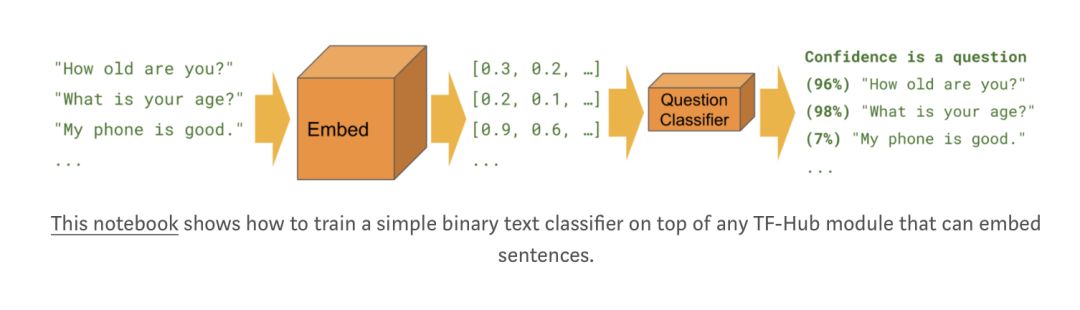
与图像再训练一样,需要相对较少的标记数据使模块适应特定的任务。如下所示:
1 # Use pre-trained universal sentence encoder to build text vector
2 review = hub.text_embedding_column(
3 “review”, “https://tfhub.dev/google/universal-sentence-encoder/1")
4 features = {
5 “review”: np.array([“this movie is a masterpiece”, “this movie was terrible”, …])
6 }
7 labels = np.array([[1], [0], …])
8 input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True)
9 estimator = tf.estimator.DNNClassifier(hidden_units, [review])
10 estimator.train(input_fn, max_steps=100)
查看本教程以了解更多信息。
注:教程链接
https://www.tensorflow.org/hub/tutorials/text_classification_with_tf_hub
其他模块
TensorFlow Hub 不仅仅有图像和文本分类库。在网站上,你还可以找到几个 Progressive GAN 模型和 Google Landmarks Deep Local Features.
注意事项
使用 TensorFlow Hub 模块时有几个重要注意事项。首先,请记住模块包含可运行的代码。并始终使用受信任来源的模块。其次,与所有机器学习一样,fairness 是一个重要的考虑因素。我们上面展示的两个示例都利用了大量预先训练的数据集。重用这样的数据集时,重要的是要注意它包含哪些数据,以及它们如何影响您正在构建的产品及其用户。
- 相关推荐
- 热点推荐
- 分类器
- 机器学习
- tensorflow
-
proteus第三方元器件库2011-12-05 50136
-
如何把第三方库加到PROTEUS中?2013-06-15 3397
-
关于proteus第三方元件库的问题2013-11-13 4709
-
Proteus 第三方元件库2014-04-16 4545
-
第三方dll调用问题!!!2018-05-11 4758
-
proteus第三方元件库2019-05-26 6495
-
下载python第三方库2019-07-02 2104
-
如何为Mixly开发第三方库来增加新功能?2021-10-13 2465
-
鸿蒙开源第三方组件资料合集2022-03-23 4530
-
推动AR技术开源化 Blippar将向第三方开发者提供API套件2016-11-08 829
-
移动应用第三方库自动检测和分类2017-12-29 1023
-
第三方实例:iView开发介绍 (1)2018-08-22 5656
-
鸿蒙开发中怎么引入第三方库2021-10-11 5644
-
在AWorks中怎样去修改第三方库的源码呢2022-07-03 2579
-
学会安装第三方开源库2023-07-13 2961
全部0条评论

快来发表一下你的评论吧 !
